链接:程序是如何被加载的
什么是链接
如果你不经常接触计算机底层的知识,链接这个概念可能对你比较陌生,但是可以这么说,只要有程序运行,就会有链接发生。链接会有很多的表现形式,今天我们主要是以 C 这种编译型语言为基础来看看链接。
我们都知道,当我们写好了一段 C 程序,想要执行,我们先需要编译,编译是将 C 源码转化为可执行的二进制文件,编译在我们的认知里就是运行类似下面这条指令:
1
>$ gcc hello.c
上面的指令会生成一个 a.out 的二进制文件,我们直接通过下面的指令执行即可:
1
>$ ./a.out
作为上层用户,我们会觉得说,你看编译就是负责将源码转化为二进制流,编译器直接生成了最后的执行文件,所以链接也应该属于编译的一部分。然而,编译和链接其实是两个东西,不存在谁包括谁的关系,当你执行 gcc hello.c 时,编译器的确做了一部分的工作,编译器将源码转化为汇编指令,但这还没到最终的可执行文件,编译阶段后面还有两个步骤,分别是汇编器将汇编指令转化为二进制流,还有就是链接器,这个指令完整的过程如下图所示
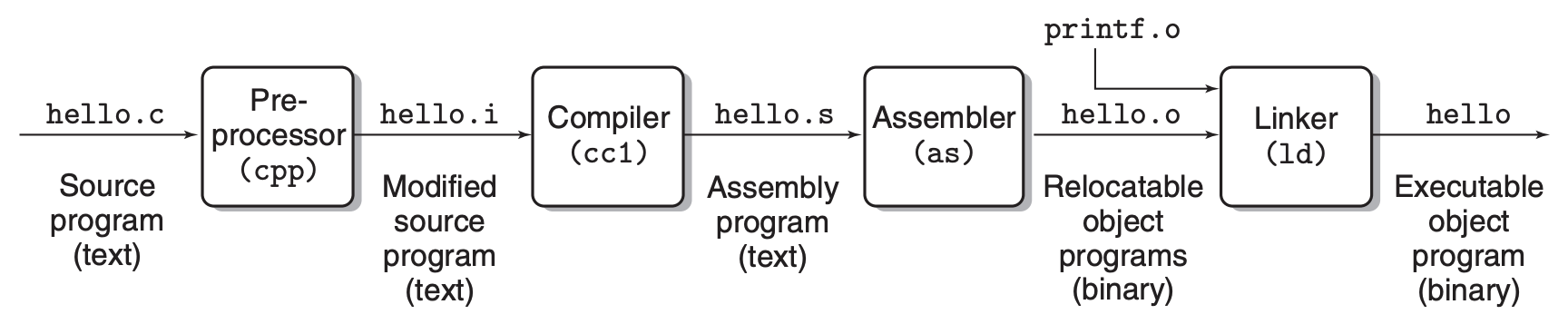
从上图看,链接器所做的事情就是将多个可执行文件组合在一起形成最终的可执行文件,你可能会觉得说,这不就是简单的文件组合嘛,有啥难度的,会觉得这一步可有可无。然而链接器所做的不单纯是文件的组合,它主要解决了下面的问题:
- 编译器和汇编器做的事情用人话说就是 “翻译”,将源码翻译成二进制流。然而,即使你有了二进制流又如何呢?这个二进制流该被加载到哪里?只有当二进制流被加载进内存后,CPU 才能够将其执行,所以这一部分也是需要链接器的帮助
- 当程序变得复杂,有全局变量、局部变量、每个模块(文件)中又会存在重名的变量,变量的作用域等等这些东西该如何解决呢?这大部分也需要链接器的帮助
- 另外,很多程序模块是会被经常使用的,比如上图中的
printf.o,如果每次运行一个程序都要将其编译并加载进内存,这会导致资源的浪费,同时也非常的耗时。这也是需要链接器进行优化的
所以链接是保证程序能够正常执行,系统高效运行的重要组成部分。
静态链接
我们先来看看最为常见也最为基础的静态链接。静态链接主要被分成两部分:
- 符号解析:由于所需要链接的程序中可能会出现重名变量、函数,这一部分主要就是将其统一,这部分完成后,程序中的每个符号(变量名、函数名、结构体名。。。)都会有且仅有一个定义
- 重定位:不管是变量,还是程序本身都是需要被加载至内存的,这一步就是将上一步生成的符号和内存地址关联起来
当然,链接器完成上面这些工作也是基于前面的编译器和汇编器生成的信息,具体什么信息,这个我们后面会说到。
符号解析
目标文件
我们首先要弄清楚一个概念就是目标文件(二进制文件),目标文件具体有下面三种:
- 可重定位目标文件
- 可共享目标文件
- 可执行目标文件
前面两个都是编译器和汇编器所生成的,链接器生成的是最后的可执行目标文件。目标文件遵循 Executable and Linkable Format (ELF) 的格式,不同目标文件所存放的信息会有所不同,我们先来看看可重定位目标文件:
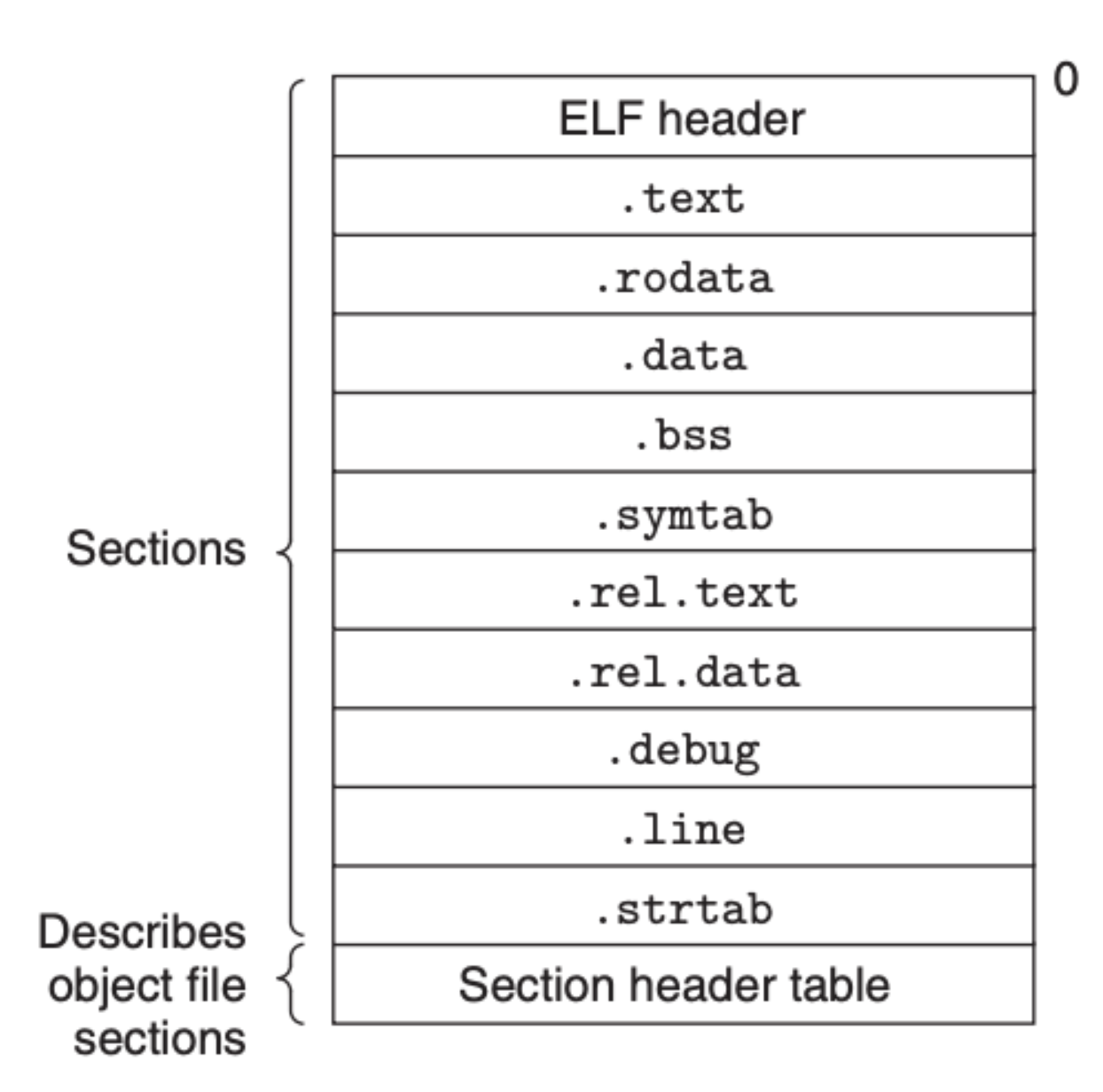
上面的 ELF header 是一个 16 字节的二进制流,它包括了一些元数据,诸如字长、文件类型、机器的类型等等,紧随其后的是程序以及链接器所需要用到的信息:
.text: 程序的二进制流 .rodata: 一些只读数据,比如格式化后的字符串,跳转列表 .data: 初始化后的全局变量,包括 C 中的静态(static)变量 .bss: 定义了但未初始化的全局变量,和静态(static)变量,还有就是初始化为 0 的全局变量,和静态(static)变量 .symtab: 一个符号表格,定义了程序中需要引用的函数和全局变量 .rel.text: 列出了 .text 中需要在链接中被修改的地方 .rel.data: 需要进行重定位的全局变量 .debug:(可选项)用于调试的信息 .line:(可选项)C 源码和机器码(.text)之间的映射 .strtab: 一个字符串表,内容包含前面 .symtab 和 .debug 中的符号表,以及 header 中的每部分的名字
另外,最后的 Section header table 里面存放的是上面这些部分的索引信息,包括各个部分的位置大小等等。
符号定义
链接器会将符号分为下面三类:
- 全局符号:比如全局变量,C 中的非静态函数,这些符号可以被其他的模块引用
- 外部符号:当前模块引用其他模块的符号
- 局部符号:只能在当前模块内使用,比如 C 中的静态函数和变量(注意这里的局部变量并不是函数中定义的变量,函数中的变量是在运行时生成的,因而不需要链接器进行处理)
我们前面说过,编译器其实提前做了很多事,这为链接器的工作打下了基础,编译器做了下面这些工作:
- 保证每个模块中的符号只有一个定义
- 保证静态的局部变量有唯一的变量名
- 当编译器发现当前模块引用的符号并不在模块内,编译器会假设这个符号定义在其他模块中,编译器会生成一个符号表格,将其放在 ELF 的指定位置,剩下的事情交由链接器处理
在此基础上,链接器开始运作,如果在输入的模块中,链接器无法找到一个符号的定义时,它会触发错误,并终止执行。
那么链接器是如何处理重名变量的呢?这里就涉及一个概念,有初始化值的全局变量和函数被链接器定义为 强符号(Strong Symbol),而没有初始化的变量被定义为 弱符号(Weak Symbol),然后基于此有以下这些规则:
- 在同一个模块中,多个同名的强符号不可以共存
- 如果一个强符号和多个弱符号重名,选择强符号
- 如果有多个弱符号重名,任意选择其中一个弱符号
我们还是来看一个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
/* foo5.c */
#include <stdio.h>
void f(void);
int y = 15212;
int x = 15213;
int main() {
f();
printf("x = 0x%x y = 0x%x \n", x, y);
return 0;
}
/* bar5.c */
double x;
void f() {
x = -0.0;
}
上面这段程序是存在问题的,在 foo5.c 文件中,我们定义了两个全局变量 x 和 y,并引用外部的函数 f(),其定义在 bar5.c 中,但是在 bar5.c 又重新定义了 x,并且函数 f 会给 x 赋值 -0.0。在链接阶段,链接器并不会认为上面这种情况是一个错误,虽然 x 重名,但是一个是强符号,另一个是弱符号,链接器会选择将强符号的内容加载进内存,但是弱符号其实也是指向同一个内存地址,在运行 f 时 x 会被一个 8 字节的常数赋值,这样 x 和 y 的值都会被覆盖。
静态库
考虑到目标文件很多且杂乱无章,很多相同的目标文件其实可以合并成一个文件,这个单一的文件就被称为静态库。静态库会以 archive 格式存放在磁盘上
比如对于下面这段程序:
1
2
3
4
5
6
7
8
9
10
11
#include <stdio.h>
#include "vector.h"
int x[2] = {1, 2};
int y[2] = {3, 4};
int z[2];
int main() {
addvec(x, y, z, 2);
printf("z = [%d %d]\n", z[0], z[1]);
return 0;
}
上面的代码并不是所有部分都需要经过编译器和汇编器,如果系统中已经存在相对应的静态库文件,这些文件直接可以被链接器操作:
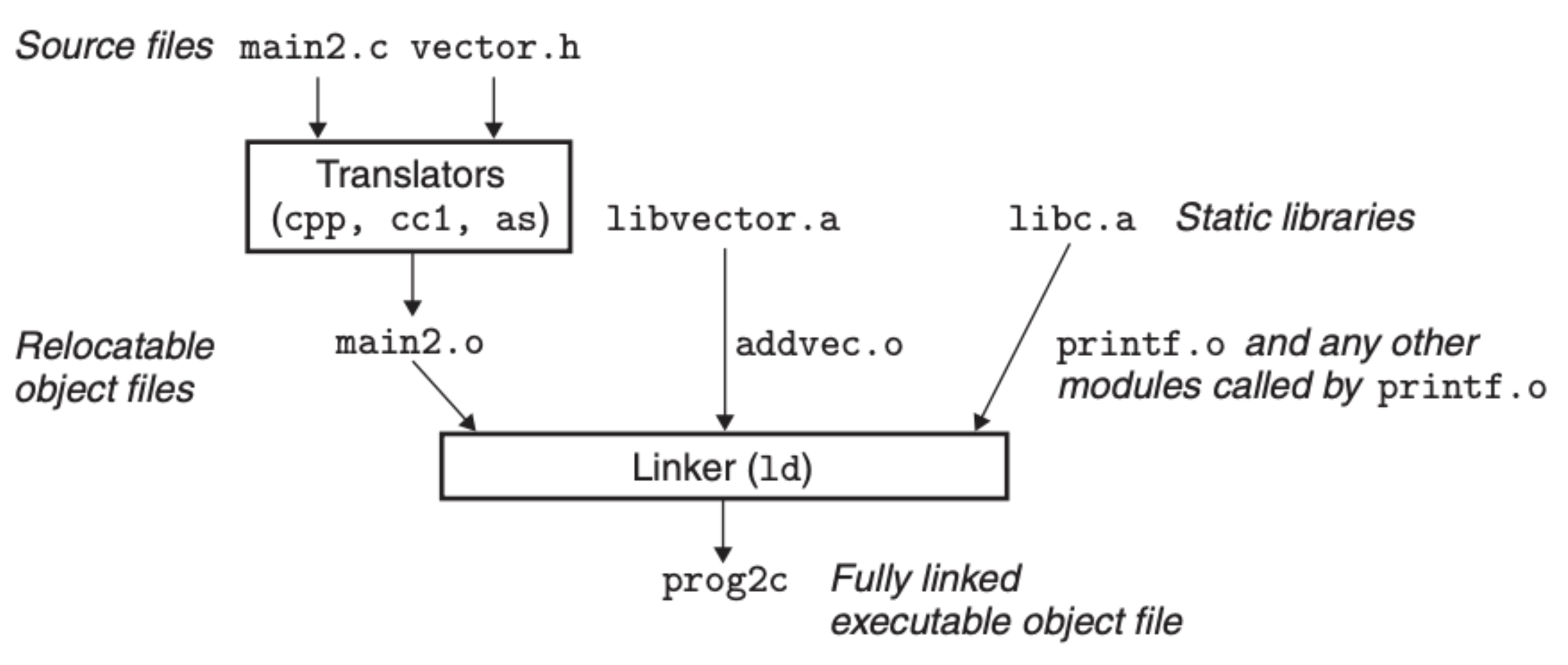
符号解析的这一过程具体是如何进行的呢?首先,我么会在命令行中输入需要编译的文件,比如下面这个指令:
1
>$ gcc foo.c libx.a libz.a liby.a
链接器会从左到右遍历所有的可重定位目标文件,在扫的过程中,链接器维护着三个集合——E、U 以及 D,最开始这三个集合都是空的,其中 E 中存放的是最终要用来生成可执行目标文件的可重定位文件,U 中存放的是在这过程中尚未解析的符号,D 中存放的是在前面扫过的文件中定义过的符号。
基于此,对于每个输入文件,链接器会执行下列步骤:
- 判断输入文件是可重定位目标文件还是 archive 文件(静态库)
- 如果是目标文件,链接器会将文件加入到
E中,并根据文件中的引用情况更新U和D,然后去到下一个文件 - 如果是静态库,链接器会尝试去匹配集合
U中尚未解析的符号,在静态库中挑选成员目标文件放入E中,剩下的成员目标文件将会被丢弃 - 如果当链接器遍历完所有的文件后,
U不为空,那么链接器会报错并退出
需要特别说明的是,因为链接器是从左到右遍历的,文件在命令中出现的位置也特别关键,如果将依赖项放到前面(左边),那么最后链接器很有可能因为找不到符号定义而报错,比如下面这个例子:
1
2
3
>$ gcc -static ./libvector.a main2.c
/tmp/cc9XH6Rp.o: In function ‘main’:
/tmp/cc9XH6Rp.o(.text+0x18): undefined reference to ‘addvec’
通常来说,是把静态库放在后面,当然为了确保符号解析的正确性,我们也可以在命令中重复指定文件,比如说 foo.c 引用了 libx.a 中的函数,而 liby.a 也引用了 libx.a 中的函数,下面这个命令也是可行的:
1
>$ gcc foo.c libx.a liby.a libx.a
到此,符号解析的任务就算完成,链接器会继续合并和重定位 E 中的目标文件。
重定位
在前面的符号解析中,我们筛选出了链接所需要的目标文件,并且我们也将符号和符号定义绑定了在一起,消除了重复的定义。剩下的事就是重定位。
重定位主要有两个步骤:
- 因为最终我们是要生成一个文件,所以这个阶段链接器会将所有目标文件的各个部分进行合并,生成可执行目标文件,这个步骤后,所有的指令或者全局变量都会映射到唯一的内存地址
- 链接器会继续改变
.text和.data中的符号引用,使其指向正确的内存地址
重定位的信息是放在 .rel.text 和 .rel.data 中,其中 .rel.text 放置的是代码的重定位信息,.rel.data 放置的是数据,比如常量的重定位信息,这些信息的格式如下:
1
2
3
4
5
6
typedef struct {
long offset; /* Offset of the reference to relocate */
long type:32, /* Relocation type */
symbol:32; /* Symbol table index */
long addend; /* Constant part of relocation expression */
} Elf64_Rela;
下面这个伪函数显示了大致的重定位逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
foreach section s {
foreach relocation entry r {
refptr=s+ r.offset; /* ptr to reference to be relocated */
/* Relocate a PC-relative reference */
if (r.type == R_X86_64_PC32) {
refaddr = ADDR(s) + r.offset; /* ref’s run-time address */
*refptr = (unsigned) (ADDR(r.symbol) + r.addend - refaddr);
}
/* Relocate an absolute reference */
if (r.type == R_X86_64_32)
*refptr = (unsigned) (ADDR(r.symbol) + r.addend);
}
}
重定位最终生成的是可执行目标文件,这个文件也是按前面的 ELF 进行排版的,但内容会有所不同:
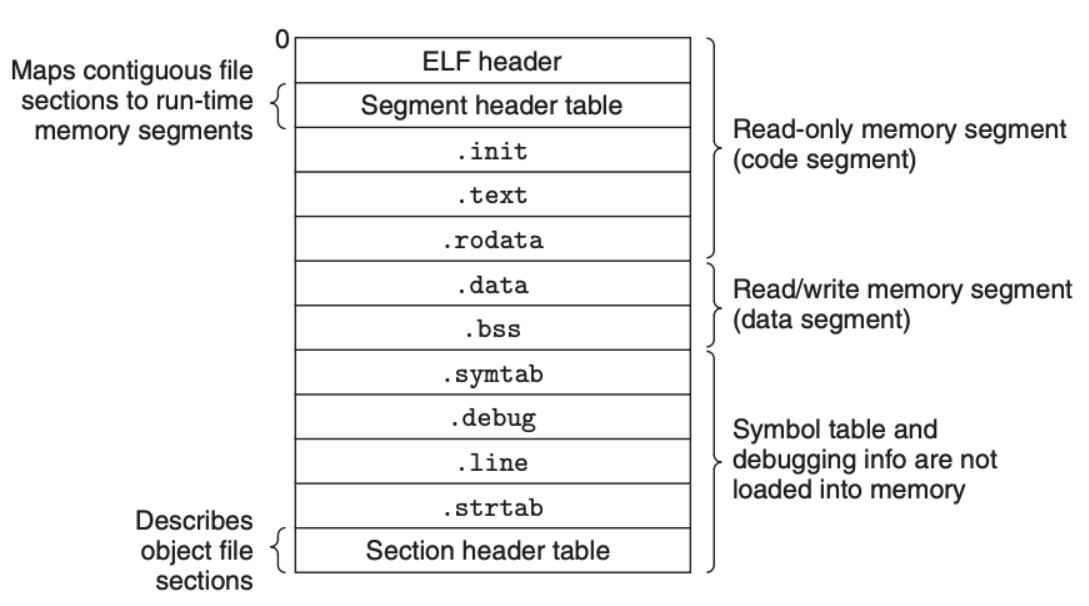
上面的大部分和可重定位目标文件一样,和前面不同的是,这里多了 .init 部分,这个部分定义了程序的初始化代码。另外,Segment header table 用于将可执行文件映射到内存上,这是加载程序必不可少的信息。
有了这些信息,可执行目标文件就会被加载进内存,具体的位置如下图所示:
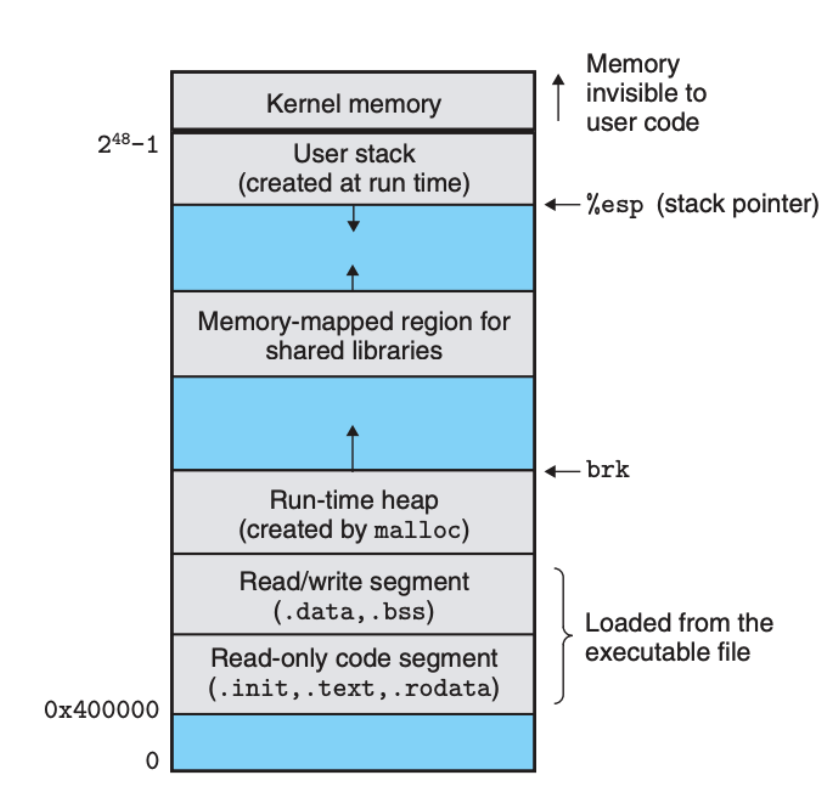
当可执行文件被加载进内存,就表示说链接阶段的工作结束,程序可以被 CPU 执行了。
动态链接
共享库
有静态链接,肯定就有动态链接。首先我们要弄清楚的一个问题,为什会有动态链接?它的出现是为了解决什么问题?通过上面静态链接的讲解,我们可以发现,整个链接的过程需要扫描符号依赖、挑选可重定位目标文件、合并文件,最后还要加载至内存,这里面还牵扯到诸多的细节,比如目标文件中每部分的具体信息,符号去重等等,如果说每运行一个程序,都需要经过这样一系列的步骤,那这效率肯定高不到哪去。另外一个重点是,静态链接的工作是将还未运行的程序加载至内存,然后将其启动,但是如果说正在运行的程序想要运行时更新,使用新的库文件,这时静态链接就没法很好地应对了。
共享库是动态链接得以实现的基础,共享库也是一个可执行文件,但是与前面的目标文件不同的是,它可以在运行时被加载进内存的任意地方,并和内存中正在运行的程序关联起来,如下图所示:
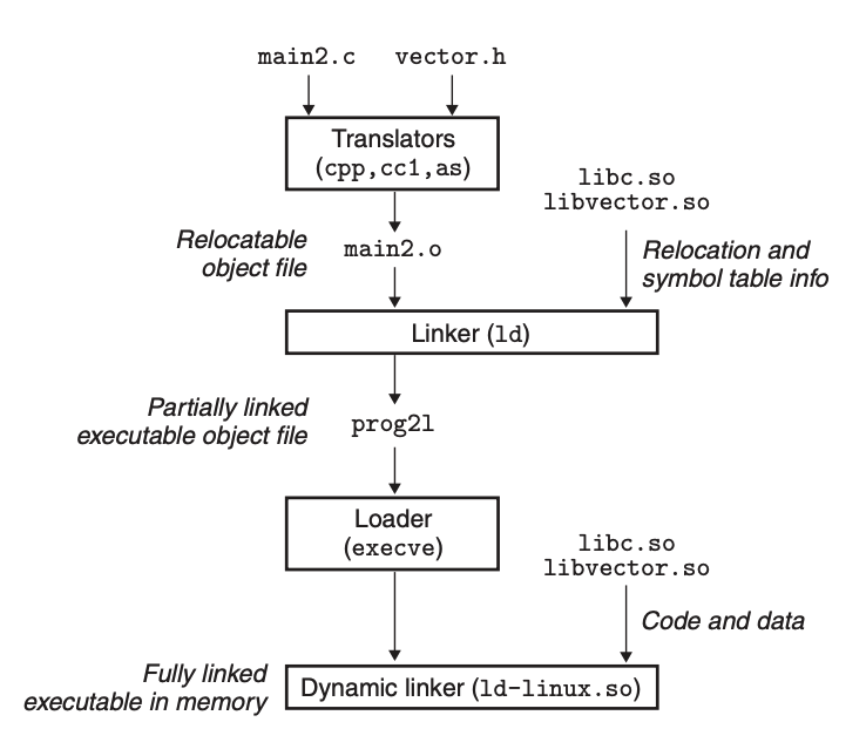
动态链接的执行是通过动态链接器 ld-linux.so 来进行的,动态链接器也是个共享库。可执行目标文件 prog21 其实仅仅做了部分的链接,剩下的链接是通过动态链接实现的。
另外,因为所有正在运行的进程都可以动态地与共享库进行链接,所以共享库潜在地也节省了内存的消耗。
正在运行的应用程序可以通过调用动态链接器来加载和链接任意的共享库,Linux 提供了下列接口来实现这部分功能:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#include <dlfcn.h>
// Loads and links the shared library filename
// Returns: pointer to handle if OK, NULL on error
void *dlopen(const char *filename, int flag);
// Takes a handle to a previously opened shared library and a symbol name and returns the address of the symbol
// Returns: pointer to symbol if OK, NULL on error
void *dlsym(void *handle, char *symbol);
// Unloads the shared library if no other shared libraries are still using it
// Returns: 0 if OK, −1 on error
int dlclose (void *handle);
// Returns a string describing the most recent error that occurred as a result of calling dlopen, dlsym, or dlclose, or NULL if no error occurred
// Returns: error message if previous call to dlopen, dlsym, or dlclose failed; NULL if previous call was OK
const char *dlerror(void);
下面的例子展示了如何使用上面的接口:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
#include <stdio.h>
#include <stdlib.h>
#include <dlfcn.h>
int x[2] = {1, 2};
int y[2] = {3, 4};
int z[2];
int main() {
void *handle;
void (*addvec)(int *, int *, int *, int);
char *error;
/* Dynamically load the shared library containing addvec() */
handle = dlopen("./libvector.so", RTLD_LAZY);
if (!handle) {
fprintf(stderr, "%s\n", dlerror());
exit(1);
}
/* Get a pointer to the addvec() function we just loaded */
addvec = dlsym(handle, "addvec");
if ((error = dlerror()) != NULL) {
fprintf(stderr, "%s\n", error);
exit(1);
}
/* Now we can call addvec() just like any other function */
addvec(x, y, z, 2);
printf("z = [%d %d]\n", z[0], z[1]);
/* Unload the shared library */
if (dlclose(handle) < 0) {
fprintf(stderr, "%s\n", dlerror());
exit(1);
}
return 0;
}
位置无关代码
共享库固然是好的,但是共享库依然是文件层面的概念,那有没有可能仅仅将某一段代码共享呢?答案是可能的,这个机制得以实现是因为数据部分和代码部分的距离是一个运行时常量,比如下面这个例子:
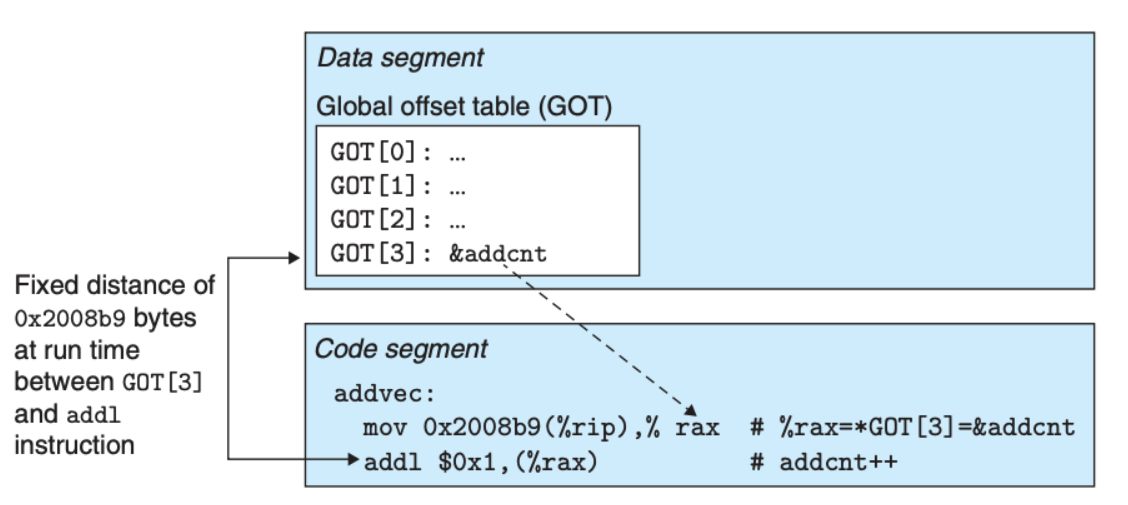
GOT 是编译器创建的一个全局偏移量表,每个被这个目标模块引用的全局符号都有一个 8 字节条目,编译器还为 GOT 中每个条目生成一个重定位记录。在加载时,动态链接器会重定位 GOT 中的每个条目,使得它包含目标的正确的绝对地址。比如上面这个例子中,addvec 例程通过 GOT[3] 间接地加载全局变量 addcnt 的地址,然后把 addcnt 在内存中加 1。
编译器可以利用代码段和数据段之间不变的距离,产生对 addcnt 的直接引用,并增加一个重定位,让链接器在构造这个共享模块时解析它。
具体的过程如下图所示:
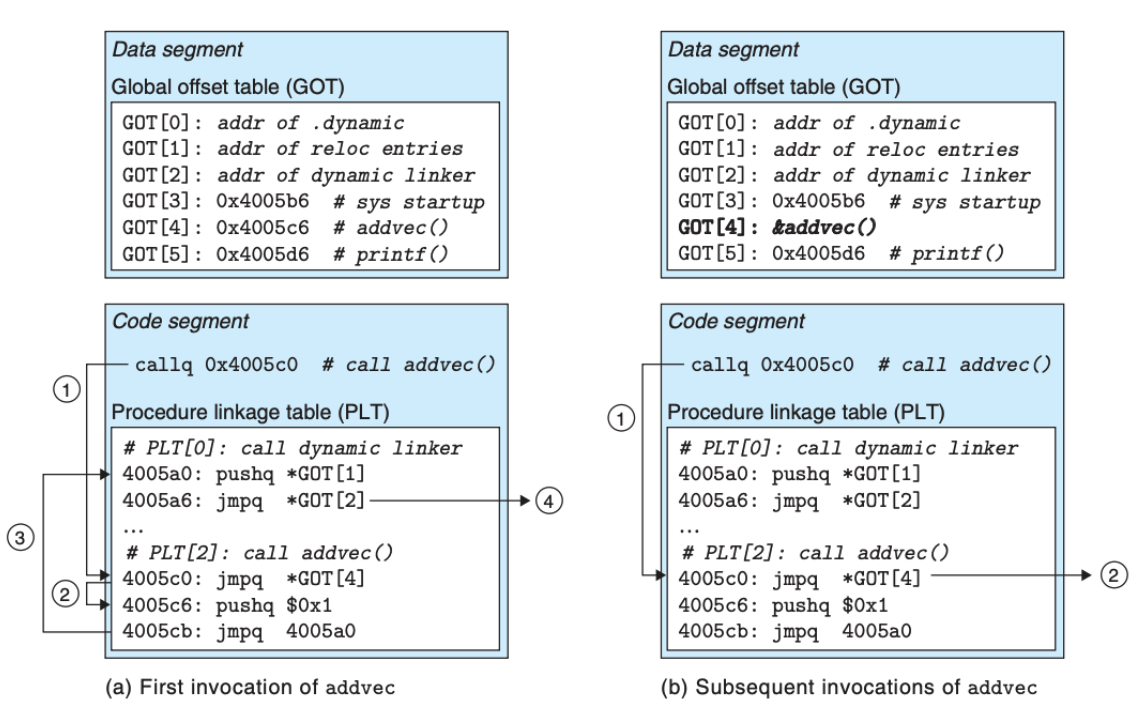
上图展示的是 GOT 和 PLT 如何协同工作,PLT 是过程链接表,是个数组,每个被可执行程序调用的库函数都有它自己的 PLT 条目。
在 addvec 第一次被调用时:
- 不直接调用
addvec,程序调用进入PLT[2],也就是addvec的 PLT 条目 - 因为每个 GOT 条目初始时都指向它对应的 PLT 条目的第二条指令,这个控制跳转只是简单地把控制传回
PLT[2]的下一条指令 - 把
addvec的 ID(0x1)压入栈中之后,PLT[2]跳转到PLT[0] PLT[0]通过GOT[1]间接地把动态链接器的一个参数压入栈中,然后通过GOT[2]间接跳转至动态链接器中。动态链接器使用两个栈条目来确定addvec的运行时位置,用这个地址重写GOT[4],再把控制传递给addvec
但是当 addvec 被再次调用时,流程就会简单很多,只需两步:
- 控制传递到
PLT[2] - 这次通过
GOT[4]的间接跳转会直接转移到addvec
库打桩机制
库打桩机制允许你截断对共享库的调用,让你自己的代码被执行,说白了就是在程序运行时用你自己的代码替代共享库。首先我们来看看编译时期的打桩机制,比如说对于下面这段程序:
1
2
3
4
5
6
7
8
9
// int.c
#include <stdio.h>
#include <malloc.h>
int main() {
int *p = malloc(32);
free(p);
return(0);
}
我们将对应的函数定义放在了另一个文件中:
1
2
3
4
5
6
// malloc.h
#define malloc(size) mymalloc(size)
#define free(ptr) myfree(ptr)
void *mymalloc(size_t size);
void myfree(void *ptr);
实现也是用 C 中的宏来定义的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// mymalloc.c
#ifdef COMPILETIME
#include <stdio.h>
#include <malloc.h>
/* malloc wrapper function */
void *mymalloc(size_t size) {
void *ptr = malloc(size);
printf("malloc(%d)=%p\n", (int)size, ptr);
return ptr;
}
/* free wrapper function */
void myfree(void *ptr) {
free(ptr);
printf("free(%p)\n", ptr);
}
#endif
可以看到,编译阶段的打桩机制主要是通过程序预处理实现的。除了编译阶段,我们还可以在链接阶段进行打桩:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
#ifdef LINKTIME
#include <stdio.h>
void *__real_malloc(size_t size);
void __real_free(void *ptr);
/* malloc wrapper function */
void *__wrap_malloc(size_t size) {
void *ptr = __real_malloc(size); /* Call libc malloc */
printf("malloc(%d) = %p\n", (int)size, ptr);
return ptr;
}
/* free wrapper function */
void __wrap_free(void *ptr) {
__real_free(ptr); /* Call libc free */
printf("free(%p)\n", ptr);
}
#endif
然后我们可以通过下面的指令来实现链接阶段的打桩:
1
2
3
$> gcc -DLINKTIME -c mymalloc.c
$> gcc -c int.c
$> gcc -Wl,--wrap,malloc -Wl,--wrap,free -o intl int.o mymalloc.o
命令通过参数 --wrap,f 来告诉链接器将符号 f 解析为 __wrap_f,另外还要将 __real_f 符号解析为 f。最后是运行时的打桩,这个就需要我们前面介绍的 Linux 提供的共享库接口:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
#ifdef RUNTIME
#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <dlfcn.h>
/* malloc wrapper function */
void *malloc(size_t size) {
void *(*mallocp)(size_t size);
char *error;
mallocp = dlsym(RTLD_NEXT, "malloc"); /* Get address of libc malloc */
if ((error = dlerror()) != NULL) {
fputs(error, stderr);
exit(1);
}
char *ptr = mallocp(size); /* Call libc malloc */
printf("malloc(%d) = %p\n", (int)size, ptr);
return ptr;
}
/* free wrapper function */
void free(void *ptr) {
void (*freep)(void *) = NULL;
char *error;
if (!ptr)
return;
freep = dlsym(RTLD_NEXT, "free"); /* Get address of libc free */
if ((error = dlerror()) != NULL) {
fputs(error, stderr);
exit(1);
}
freep(ptr); /* Call libc free */
printf("free(%p)\n", ptr);
}
#endif