设计模式:修饰器模式
场景再现
和之前一样,在介绍具体的设计模式前,我们还是来看一个案例,这样可以让我们理解这个模式的应用场景以及它所解决的问题。
假设有一家餐厅为顾客提供定制化的菜品,顾客在菜单上面挑选菜品后,可以对菜品提一些个性化的要求,比如多加某种食材或是某种调料,也可以对烹调方式进行要求,根据顾客的要求不同,最后的菜品价格也会有所不同,我们可以得到下面这个结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
abstract class Dish {
String description = "Unknow Dish";
public String getDescription() {
return description;
}
public abstract double price();
}
class Hamburger extends Dish {
public Hamburger() {
description = "Hamburger";
}
public double price() {
return 10.99;
}
}
class HamburgerWithExtraOnion extends Dish {
public Hamburger() {
description = "Hamburger, Extra Onion";
}
public double price() {
return 11.99;
}
}
class HamburgerWithExtraKetchup extends Dish {
public Hamburger() {
description = "Hamburger, Extra Ketchup";
}
public double price() {
return 10.99;
}
}
// ...
上面的代码样例中,对于 Hamburger 这个菜品,由于顾客对它的需求不太一样,我们将所有的可能一一列出,每一种可能对应为一个类。这确实简单明了,而且每当新加一个菜品种类时,我们不需要改动原来的代码。可是这样的设计方式最终会导致类的数量过于庞大,并且由于组合方式的多种多样,我们也很难提前预测用户的具体要求。那是否有好一点的方式呢?
斟酌再三,我们得到下面的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
abstract class Dish {
String description = "Unknow Dish";
public String getDescription() {
return description;
}
public abstract double price();
}
class Hamburger extends Dish {
String description;
double price;
public Hamburger() {
description = "Hamburger";
}
public void addExtraOnion() {
description += ", Extra Onion";
price += 1.0;
}
public void addExtraKetchup() {
description += ", Extra Ketchup";
// price += 0;
}
// ...
public double price() {
return price;
}
}
和之前不一样的是,这里我们不再把每种需求拆分开来,既然每种需求都是针对 Hamburger 的,那么我们将这些需求都放到 Hamburger 类中,这样可以直接叫类中的方法来对最后的结果(description 和 price)进行更改。
可这样的方法还是存在问题,首先它违背了开放封闭原则(open-closed principle),试想一下,如果有新的需求加入,那么我们势必要更改现有的 Hamburger 类。更改现有的代码会造成逻辑的混乱不说,而且会影响现存的业务逻辑,因而,允许新增但避免修改是很有必要的。
此外,这样的做法也没有很好地重用代码,试想一下,我们有另外一道菜品,比如 BaconAndEgg,顾客也可以选择对其 addExtraOnion 以及 addExtraKetchup,那么在这个类中,我们还要重复创建这两个方法。不同的菜品,不同的定制化选项,到最后,我们会得到许许多多的重复代码,这无形之中增加了代码的复杂度以及维护成本。
那下面这段代码总该可以了吧?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
abstract class Dish {
String description = "Unknow Dish";
public String getDescription() {
return description;
}
public abstract double price();
}
class Hamburger extends Dish {
String description;
double price;
public Hamburger() {
description = "Hamburger";
}
public void updateDish(String ingredient, double price) {
this.description += ", " + ingredient;
this.price += price;
}
public double price() {
return price;
}
}
这段代码直接将难题扔给了客户端,客户端传进来什么,Hamburger 就更新什么。可这里的问题是,客户端怎么知道有哪些选项呢,又怎么知道每个选项对应有哪些特质?
另外这里还是违背了开放封闭原则,在 updateDish 中,我们默认所有的请求都是一样的操作(加法),现在看似行得通,如果新增的要求需要不一样的处理方式,那么还是避免不了去更改现有逻辑。
可以看出,要想更好地解决这个问题,我们需要引入一些最佳实践,也就是修饰器模式。
修饰器模式
还是之前的例子,如果使用修饰器模式,我们可以将之前的代码修改成下面这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
abstract class Dish {
String description = "Unknow Dish";
public String getDescription() {
return description;
}
public abstract double price();
}
class Hamburger extends Dish {
public Hamburger() {
description = "Hamburger";
}
public double price() {
return 10.99;
}
}
abstract class AdditionalRequirementDecorator extends Dish {
abstract public String getDescription();
}
class ExtraOnionDecorator extends AdditionalRequirementDecorator {
Dish dish;
public ExtraOnionDecorator(Dish dish) {
this.dish = dish;
}
public String getDescription() {
return dish.getDescription() + ", Extra Onion";
}
public double price() {
return 1.0 + dish.price();
}
}
class ExtraKetchupDecorator extends AdditionalRequirementDecorator {
Dish dish;
public ExtraKetchupDecorator(Dish dish) {
this.dish = dish;
}
public String getDescription() {
return dish.getDescription() + ", Extra Ketchup";
}
public double price() {
return dish.price();
}
}
// ...
下图可以简单地表示上面代码模块的关系:
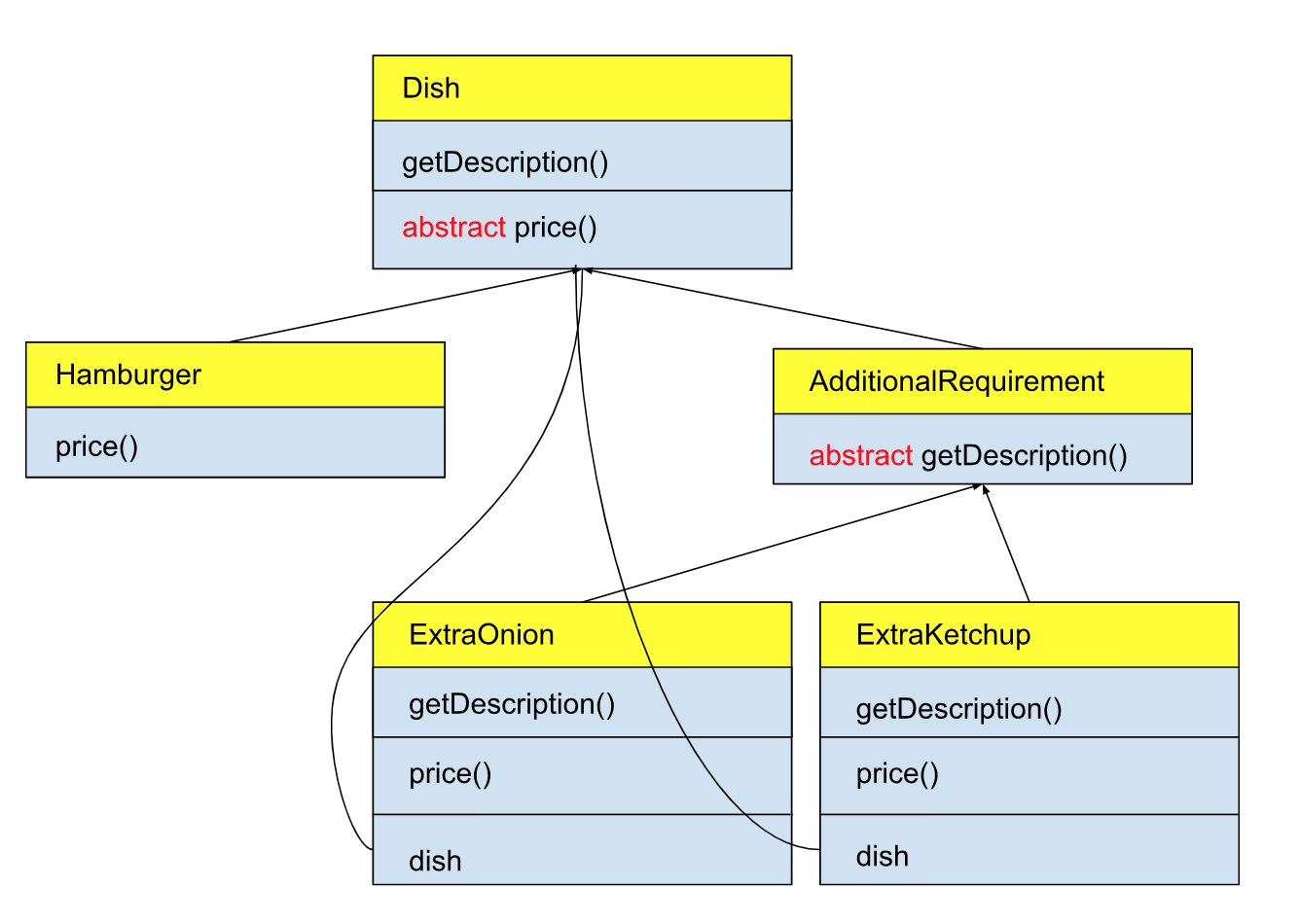
其中,基类 Dish 还是和之前一样,我们并没有对其改动,在菜品类 Hamburger 中我们也没有添加任何的附加逻辑。我们新建了另一个基类 AdditionalRequirementDecorator 用来表示顾客的额外要求,任何的额外要求均为这个类的子类,比如这里的 ExtraOnionDecorator 以及 ExtraKetchupDecorator。
ExtraOnionDecorator 以及 ExtraKetchupDecorator 就是修饰器,它们的主要职责是对对象添加额外逻辑或操作,对什么对象呢?你可以看到,这两个类的内部都嵌套了一个 Dish 变量,它们就是对这个嵌套的 Dish 对象增加额外逻辑。
如果你是第一次接触修饰器模式,相信看到这里你会有点懵,什么嘛?又是继承又是组合,绕来绕去的,感觉不比之前好多少啊?别急,接下来我们来看看修饰器模式具体好在哪,它为什么要这样实现,又是如何解决我们之前提到的那些问题的。
修饰器模式解析
这里可能最难理解的是,为什么修饰器既要组合嵌套一个基类的对象,又要继承上面的基类,并且还不是直接继承最顶上的 Dish,中间还穿插了个 AdditionalRequirementDecorator。
组合与继承都有各自的目的,组合比较好理解,因为你是修饰器,那么你的职责就是对已存在的对象进行修饰,而不是凭空创造对象,嵌套对象的目的就是更好地对其进行修饰,对其进行再加工。
再来说说继承,继承的目的是为了保证类型匹配。修饰器其实就是一个包裹类,经由它包裹后的对象是不是应该和包裹前的类型保持一致?Hamburger 经过修饰器加工后,虽然里面的内容变的和之前不一样,但是类型依旧是 Hamburger。
中间增加一个 AdditionalRequirementDecorator 主要是为了区分正常的 Dish 类和修饰器类的。没有中间这个类作为过渡,代码依旧可以运行,但是可读性就差很多了,我们很容易把 ExtraOnionDecorator 或是 ExtraKetchupDecorator 当作是真正的 Dish,其实它们只起到修饰作用,当然了,这里的命名确实一目了然。
除了继承,在 Java 中,我们也可以选择实现接口的方式来设计修饰器,其目的都是一样的————保证类型一致。
说了这么多,你可能很好奇,使用了修饰器模式后,一开始我们讨论的问题真的都解决了吗?首先,我们先来看看针对之前的例子,客户端是如何使用修饰器的:
1
2
3
4
5
6
7
8
9
10
11
public class Restaurant {
public static void main(String[] args) {
Dish dish = new Hamburger();
System.out.println(dish.getDescription() + " $" + dish.price());
Dish dishWithExtra = new Hamburger();
dishWithExtra = new ExtraOnion(dishWithExtra);
dishWithExtra = new ExtraKetchup(dishWithExtra);
System.out.println(dishWithExtra.getDescription() + " $" + dishWithExtra.price());
}
}
可以看到,修饰器对客户端是透明的,客户端可以选择任意种类、任意数量的修饰器通过任意的顺序包裹原对象。并且使用起来也相当简便。这就是修饰器模式的一大优势————允许在运行时对对象增添额外的行为。想想看,传统的面向对象设计中,子类只能通过 override 父类的方法来增添新的行为,而且这都是静态的,编译时的。而修饰器模式依靠着对象组合(Composition)以及任务委托(Delegation)提供了另外一种思路。
修饰器模式也是遵守开放封闭原则的,当有新的要求过来,我们只需要新增一个修饰器即可。每个修饰器自定义如何对对象的行为进行更改,可以在原本的行为发生前,也可以在原本的行为发生后。此外,例子当中的修饰器可以被用在不同的 Dish 上,这一定程度上增加了代码的重用率,减少了代码重复。
那么修饰器对象有没有缺点呢?当然是有的,大量使用修饰器模式会产生很多小的修饰器类,如果代码读者不熟悉修饰器模式的话,那么他将难以理解这里面错综复杂的关系。
在 Java 的 I/O 类库中,就大量使用了修饰器模式:
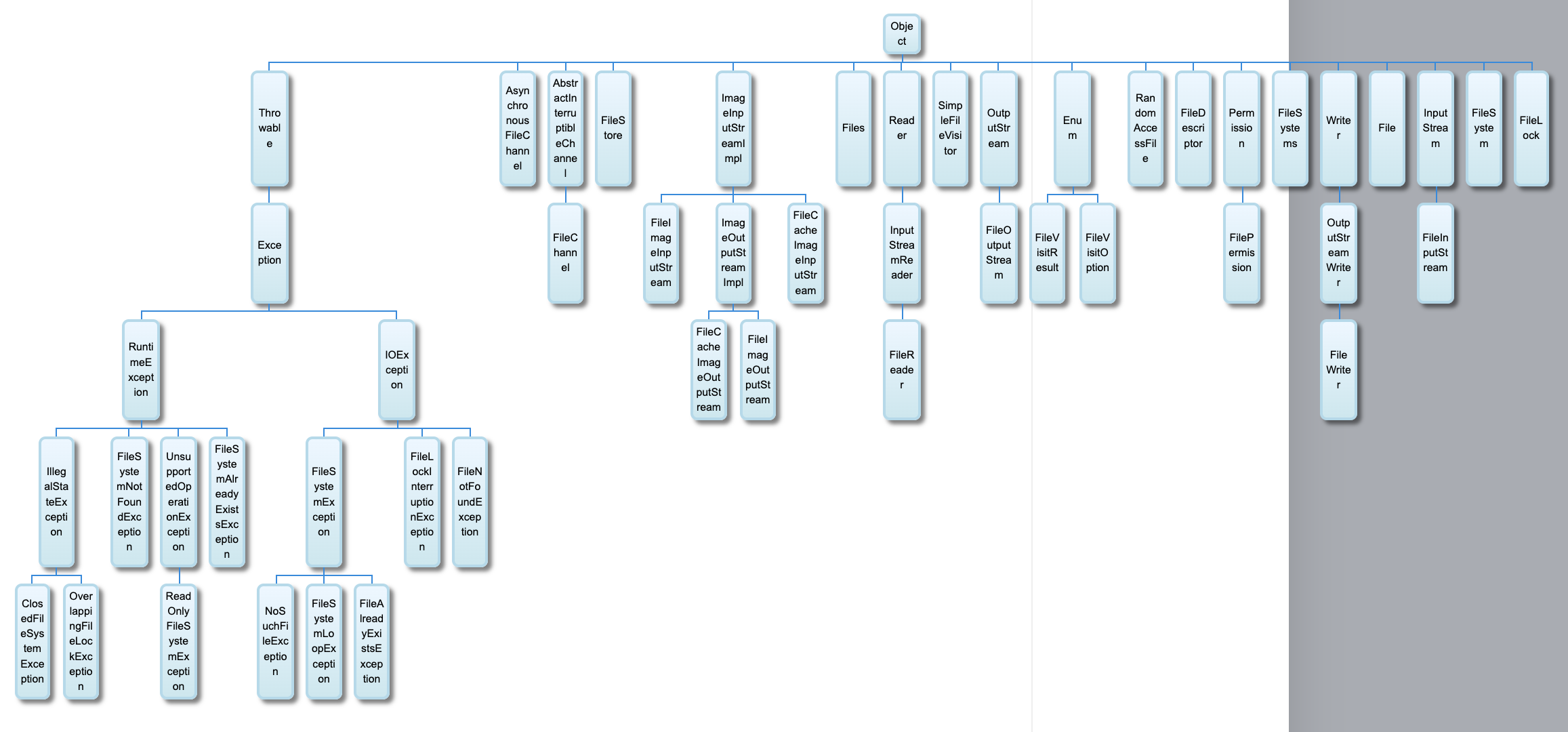
当然,如果你知道并且熟悉修饰器模式,那么即使类的数量再多,你也可以找到这里的逻辑关系。
另外,修饰器其实是依赖于组合对象的行为的,组合对象的行为的改动以及变化均会对修饰器的结果造成影响。也就是说修饰器和组合对象存在着耦合,并且当客户端使用多个修饰器连接在一起形成一条长长的包裹链时,出现了问题我们很难 debug,也很难看清这里面的逻辑关系。