计算机的 I/O
什么是 I/O
前面的文章主要是讲解了 CPU、高速缓存、内存这样的计算机部件,它们是计算机的核心且不可或缺的组件。但我们知道,这并不是计算机的全部,作为终端用户的我们也并不直接跟这些东西接触,我们直接接触的像是显示屏、USB 接口、键盘、鼠标、音箱或是麦克风,这些东西又是如何与计算机交互的呢?这就不得不说 I/O 了。
I/O 中的 I 代表的是输入(Input),O 代表的是输出(Output),如果我们把 CPU 和内存为整体的部分看作是计算机,那么这里的输入输出就是针对这个部分来说的。将数据或请求传送到 CPU 和内存称之为输入,而将 CPU 处理后的结果输出到类似显示屏这样的外围设备就是输出了。这都好理解,不过学习 I/O 我们主要是要学啥呢?
要知道现代计算机有着各种各样的功能,而这些功能的实现少不了 I/O 设备,这些设备通过不同型号的接口连接到计算机,要怎么管理这些设备就成为了一个问题,主要的难点在于软件层面如何组织,比如每个设备的接口与数据格式都不一样,我们该如何对它们进行区分的同时也将它们的请求转化为 CPU 能理解的信号?另外,如果多个设备同时请求,CPU 又该如何回应呢?还有,交互并不仅仅发生于 CPU 和设备之间,也有可能发生在设备与设备之间,这又该如何协调?那就带着这些问题,我们一起来学习学习 Linux/Unix 中的 I/O 系统。
文件
I/O 设备是实体,并且每个设备的型号和功能都不尽相同,从软件层面来说,我们更希望有一层抽象来统一管理这些设备,这一层抽象就是——文件。在 Unix/Linux 系统中,所有的 I/O 设备,比如网络、硬盘、终端以及鼠标键盘都会被看作是文件,这样设备的输入输出就被转化为文件的读写,这样所有的输入输出表现形式就变的一致了。
对于文件,有以下几个基本操作:
- 打开文件:在这个操作后,内核将会返回一个正整数,表示的是这个文件的描述符,是这个文件的 ID,程序可以通过这个 ID 来找到文件。内核会跟踪并更新打开文件的所有信息,当然了应用程序只需要保证这个 ID 和文件能对应起来就行。每个被 Linux shell 创建的进程,开始时都会有下面 3 个打开的文件:
- 标准输入流(0)
- 标准输出流(1)
- 标准错误流(2)
- 变换当前文件的位置:文件的位置表示的是读写发生的地方,内核会跟踪每个打开的文件的具体位置(初始化为 0),应用程序也可以更改文件的位置
- 读写文件:
- 读操作会从文件的当前位置
k拷贝n个字节到内存中去,然后将k更新为k + n - 写操作会从内存中拷贝
n个字节到文件中来,从k开始,然后将k更新为k + n - 当文件可供读取的字节数
m小于需要读取的字节数n,将会触发 end-of-file(EOF),应用程序将会被告知这一情况
- 读操作会从文件的当前位置
- 关闭文件:应用程序可以调用相关函数关闭文件,内核也会释放掉文件对应的内存资源。当一个进程被任何情况终止后,内核也会关闭跟其相关的文件
文件类型
Linux 中将文件分成了 3 类:
- 普通文件:包含任意数据的文件
- 目录:包含了一组链接,每个链接对应的是一个文件或是其他的目录
- 套接字(Socket):用于进程间网络通信的特殊文件
相关系统函数
我们还是对应着前面的几个基本操作来以此看看 Linux 为这些操作提供的函数接口,首先是打开文件操作:
1
2
3
4
5
6
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
// Returns: new file descriptor if OK, −1 on error
int open(char *filename, int flags, mode_t mode);
open 函数其实有两个功能:
- 打开一个现存的文件
- 如果文件不存在,创建一个新文件
open 函数将文件名(路径)转化为了文件的描述符(ID),并且这个描述符永远是没有被当前程序使用过的整数中最小的那个。这里的 flag 参数表示的是进程将要对文件进行的操作,最基础的有下面这些:
O_RDONLY. Reading only
O_WRONLY. Writing only
O_RDWR. Reading and writing
另一个参数 mode 表示的是这个文件的访问权限。
与打开文件对应的就是关闭文件,关闭文件对于应用程序来说十分简单,只需要传入文件对应的描述符即可:
1
2
3
4
#include <unistd.h>
// Returns: 0 if OK, −1 on error
int close(int fd);
打开关闭还好,主要的工作主要在内核,而读写文件则相对来说要复杂得多:
1
2
3
4
5
6
7
#include <unistd.h>
// Returns: number of bytes read if OK, 0 on EOF, −1 on error
ssize_t read(int fd, void *buf, size_t n);
// Returns: number of bytes written if OK, −1 on error
ssize_t write(int fd, const void *buf, size_t n);
这里来简单解释下这两个函数,read 函数会在文件 fd 的当前位置拷贝 n 个字节到内存 buf 中去,write 函数则是反过来,会从内存 buf 处拷贝 n 个字节到文件 fd 的当前位置,另外需要说明的是,在 x86-64 系统中 size_t 等同于 unsigned long 类型,ssize_t 等同于 long 类型。
比如下面就是一个利用 read 和 write 将标准输入拷贝到标准输出的例子:
1
2
3
4
5
6
7
8
#include "csapp.h"
int main(void) {
char c;
while(Read(STDIN_FILENO, &c, 1) != 0)
Write(STDOUT_FILENO, &c, 1);
exit(0);
}
read 和 write 函数在下面这些情况下拷贝的字节数会小于应用程序请求的 n:
read的过程中发生了 EOF- 如果打开的文件和终端关联,
read每次会拷贝一行的数据,当拷贝行的字节数小于n时,就会发生这个情况 - 在读写网络套接字时,网络缓冲区的限制以及长时间的网络延迟将会导致这个情况的发生
更加健壮的读写函数(RIO 包)
在许多情形下 read 和 write 函数确实可以满足我们的需求,但是在一些特殊场合我们需要构建一个更加健壮的应用,比如构建一个 web 服务器。这时,我们就需要在这两个函数的基础上进行改写,让其变得更易用。
RIO 包提供两种类型的读写函数,一种是无缓冲的,也就是类似 read 和 write,直接在内存和文件之间拷贝数据,另一种是有缓冲的,应用程序中的缓冲可以缓存数据一提升效率。
首先我们来看看没有缓冲的函数接口定义:
1
2
3
4
5
#include "csapp.h"
// Returns: number of bytes transferred if OK, 0 on EOF (rio_readn only), −1 on error
ssize_t rio_readn(int fd, void *usrbuf, size_t n);
ssize_t rio_writen(int fd, void *usrbuf, size_t n);
接口定义和前面的 read 以及 write 类似,不同的是 rio_readn 只会在读取过程中出现 EOF 的情况下返回小于请求的字节数,rio_writen 在任何情况下均不会发生实际执行字节数小于请求数的情况。这两个函数的具体实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
ssize_t rio_readn(int fd, void *usrbuf, size_t n) {
size_t nleft = n;
ssize_t nread;
char *bufp = usrbuf;
while (nleft > 0) {
if ((nread = read(fd, bufp, nleft)) < 0) {
if (errno == EINTR) /* Interrupted by sig handler return */
nread = 0; /* and call read() again */
else
return -1; /* errno set by read() */
} else if (nread == 0)
break; /* EOF */
nleft -= nread;
bufp += nread;
}
return (n - nleft); /* Return >= 0 */
}
ssize_t rio_writen(int fd, void *usrbuf, size_t n) {
size_t nleft = n;
ssize_t nwritten;
char *bufp = usrbuf;
while (nleft > 0) {
if ((nwritten = write(fd, bufp, nleft)) <= 0) {
if (errno == EINTR) /* Interrupted by sig handler return */
nwritten = 0; /* and call write() again */
else
return -1; /* errno set by write() */
}
nleft -= nwritten;
bufp += nwritten;
}
return n;
}
可以看到的是,这两个函数的核心功能也是基于原始的系统函数 read 和 write,但如果在调用 read 和 write 的过程中有错误发生,比如中断,rio_readn 和 rio_writen 都将会进行重试。
另外一种改良版本是带缓冲的,函数接口如下所示:
1
2
3
4
5
6
7
8
#include "csapp.h"
// Returns: nothing
void rio_readinitb(rio_t *rp, int fd);
// Returns: number of bytes read if OK, 0 on EOF, −1 on error
ssize_t rio_readlineb(rio_t *rp, void *usrbuf, size_t maxlen);
ssize_t rio_readnb(rio_t *rp, void *usrbuf, size_t n);
因为是带缓冲的,我们需要将缓冲和具体的文件关联起来,需要有一个初始化的步骤,rio_readinitb 做的就是这件事,这个函数会将一个空的缓冲 rp 和一个打开的文件 fd 进行关联。比如将前面的那个将标准输入拷贝到标准输出的例子改写用 RIO 包内的函数就会是下面这样:
1
2
3
4
5
6
7
8
9
10
11
#include "csapp.h"
int main(int argc, char **argv) {
int n;
rio_t rio;
char buf[MAXLINE];
Rio_readinitb(&rio, STDIN_FILENO);
while((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0)
Rio_writen(STDOUT_FILENO, buf, n);
}
另外,我们在看看缓冲类型和 rio_readinitb 的实现逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
#define RIO_BUFSIZE 8192
typedef struct {
int rio_fd; /* Descriptor for this internal buf */
int rio_cnt; /* Unread bytes in internal buf */
char *rio_bufptr; /* Next unread byte in internal buf */
char rio_buf[RIO_BUFSIZE]; /* Internal buffer */
} rio_t;
void rio_readinitb(rio_t *rp, int fd) {
rp->rio_fd = fd;
rp->rio_cnt = 0;
rp->rio_bufptr = rp->rio_buf;
}
rio_readinitb 其实就是对缓冲对象进行初始化,另外两个缓冲读取函数的核心是下面这个函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
static ssize_t rio_read(rio_t *rp, char *usrbuf, size_t n) {
int cnt;
while (rp->rio_cnt <= 0) { /* Refill if buf is empty */
rp->rio_cnt = read(rp->rio_fd, rp->rio_buf, sizeof(rp->rio_buf));
if (rp->rio_cnt < 0) {
if (errno != EINTR) /* Interrupted by sig handler return */
return -1;
} else if (rp->rio_cnt == 0) /* EOF */
return 0;
else
rp->rio_bufptr = rp->rio_buf; /* Reset buffer ptr */
}
/* Copy min(n, rp->rio_cnt) bytes from internal buf to user buf */
cnt = n;
if (rp->rio_cnt < n)
cnt = rp->rio_cnt;
memcpy(usrbuf, rp->rio_bufptr, cnt);
rp->rio_bufptr += cnt;
rp->rio_cnt -= cnt;
return cnt;
}
rio_read 是带缓冲版本的 read,而 rio_readnb 的框架和前面的 rio_readn 是一样的,只不过把其中的 read 替换成了这里的 rio_read:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
ssize_t rio_readnb(rio_t *rp, void *usrbuf, size_t n) {
size_t nleft = n;
ssize_t nread;
char *bufp = usrbuf;
while (nleft > 0) {
if ((nread = rio_read(rp, bufp, nleft)) < 0)
return -1; /* errno set by read() */
else if (nread == 0)
break; /* EOF */
nleft -= nread;
bufp += nread;
}
return (n - nleft); /* Return >= 0 */
}
对于 rio_readlineb 来说也是一样的,只不过这个函数主要是读行,通过行分隔符 \n 来判断操作终止:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
ssize_t rio_readlineb(rio_t *rp, void *usrbuf, size_t maxlen) {
int n, rc;
char c, *bufp = usrbuf;
for (n = 1; n < maxlen; n++) {
if ((rc = rio_read(rp, &c, 1)) == 1) {
*bufp++ = c;
if (c == '\n') {
n++;
break;
}
} else if (rc == 0) {
if (n == 1)
return 0; /* EOF, no data read */
else
break; /* EOF, some data was read */
} else
return -1; /* Error */
}
*bufp = 0;
return n-1;
}
读取文件元数据
应用程序可以通过下面这两个函数来获取文件的基本信息(元数据):
1
2
3
4
5
6
#include <unistd.h>
#include <sys/stat.h>
// Returns: 0 if OK, −1 on error
int stat(const char *filename, struct stat *buf);
int fstat(int fd, struct stat *buf);
其中元数据 stat 的结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
struct stat {
dev_t st_dev; /* Device */
ino_t st_ino; /* inode */
mode_t st_mode; /* Protection and file type */
nlink_t st_nlink; /* Number of hard links */
uid_t st_uid; /* User ID of owner */
gid_t st_gid; /* Group ID of owner */
dev_t st_rdev; /* Device type (if inode device) */
off_t st_size; /* Total size, in bytes */
unsigned long st_blksize; /* Block size for filesystem I/O */
unsigned long st_blocks; /* Number of blocks allocated */
time_t st_atime; /* Time of last access */
time_t st_mtime; /* Time of last modification */
time_t st_ctime; /* Time of last change */
};
这些信息其实我们并不陌生,很多都是平时我们使用 Linux 下的 ls -al 指令时显示出来的。有了 stat 对象,我们就可以在应用程序中调用一些宏函数来帮助我们进行判断,如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include "csapp.h"
int main (int argc, char **argv) {
struct stat stat;
char *type, *readok;
Stat(argv[1], &stat);
if (S_ISREG(stat.st_mode)) /* Determine file type */
type = "regular";
else if (S_ISDIR(stat.st_mode))
type = "directory";
else
type = "other";
if ((stat.st_mode & S_IRUSR)) /* Check read access */
readok = "yes";
else
readok = "no";
printf("type: %s, read: %s\n", type, readok);
exit(0);
}
读取目录内容
我们前面有提到过,目录也是文件,是一种特殊的文件,因此这里我们需要使用到另一组系统函数对其进行操作,首先是打开目录:
1
2
3
4
5
#include <sys/types.h>
#include <dirent.h>
// Returns: pointer to handle if OK, NULL on error
DIR *opendir(const char *name);
opendir 的输入参数是一个目录的路径名,返回的是一个指针,指向的是一个排序好的目录序列,这当然不够,想要看每个目录的内容,我们还需要下面这个函数:
1
2
3
4
#include <dirent.h>
// Returns: pointer to next directory entry if OK, NULL if no more entries or error
struct dirent *readdir(DIR *dirp);
判断目录序列有没有读完的唯一方法就是检查全局变量 errno,因此我们在使用 readdir 时需要考虑好线程安全的问题。这个函数返回的是一个存放对应目录基本信息的结构体:
1
2
3
4
struct dirent {
ino_t d_ino; /* inode number */
char d_name[256]; /* Filename */
};
除此之外,还有一个负责关闭目录的函数:
1
2
3
4
#include <dirent.h>
// Returns: 0 on success, −1 on error
int closedir(DIR *dirp);
下面的这个是一个读取目录内容的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
#include "csapp.h"
int main(int argc, char **argv) {
DIR *streamp;
struct dirent *dep;
streamp = Opendir(argv[1]);
errno = 0;
while ((dep = readdir(streamp)) != NULL) {
printf("Found file: %s\n", dep->d_name);
}
if (errno != 0)
unix_error("readdir error");
Closedir(streamp);
exit(0);
}
共享文件
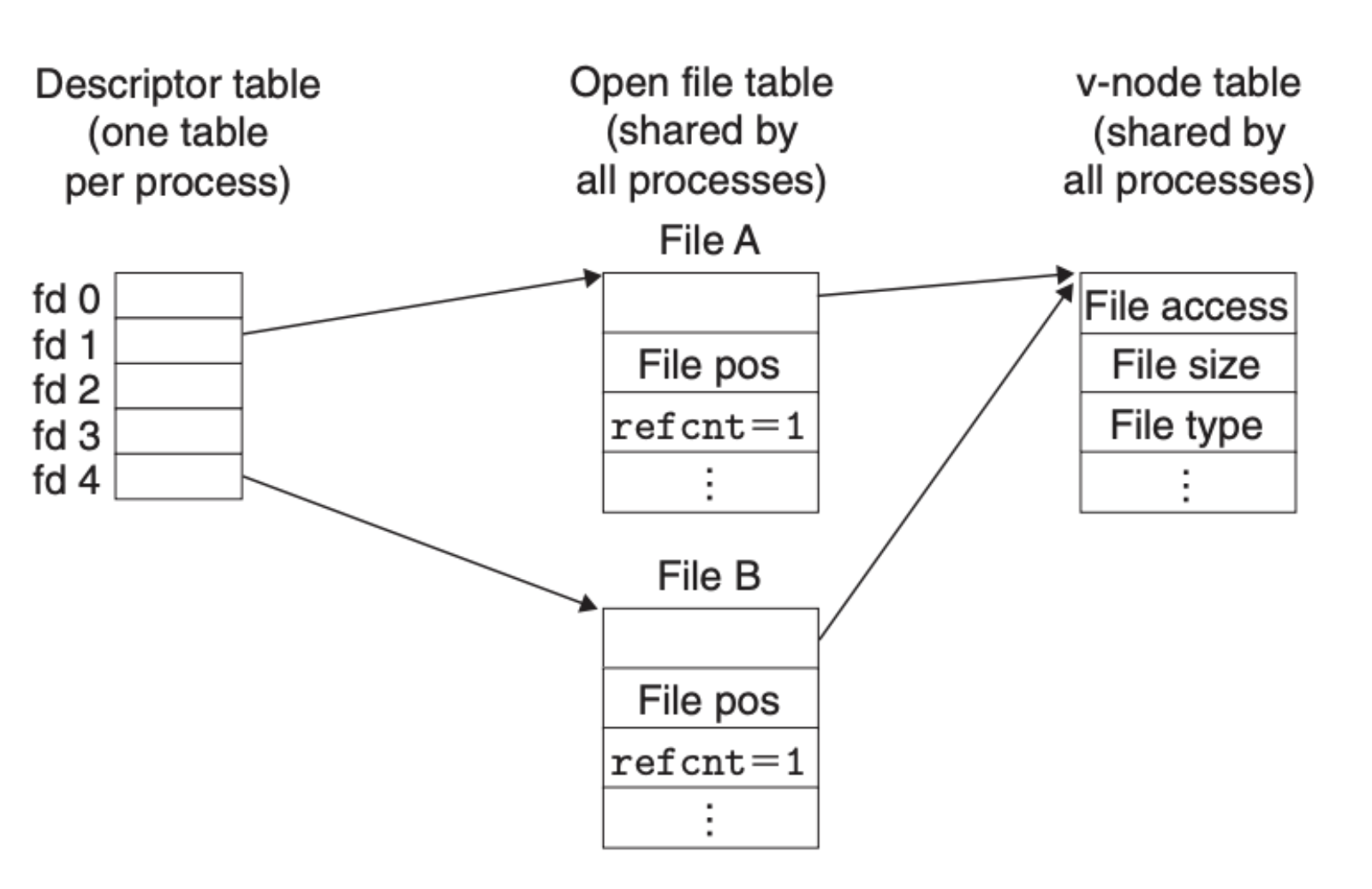
前面我们知道了文件的基本操作,这还远远不够,要清楚整个文件系统,我们还需要站在更高的层面,了解操作系统是如何管理文件的。操作系统内核定义了如下 3 个数据结构:
- 文件描述符表(descriptor table):每个进程都会有自己的文件描述符表,这里面的元素是该进程对应的打开文件
- 文件表(file table):这个表是所有进程共享的,里面包含所有打开的文件
- v-node 表:和文件表一样
下图可以很好地说明上面三者之间的关系:

在这个框架下,文件共享成为了可能,比如下面这个例子就是两个不同的文件描述符指向同一个磁盘文件:
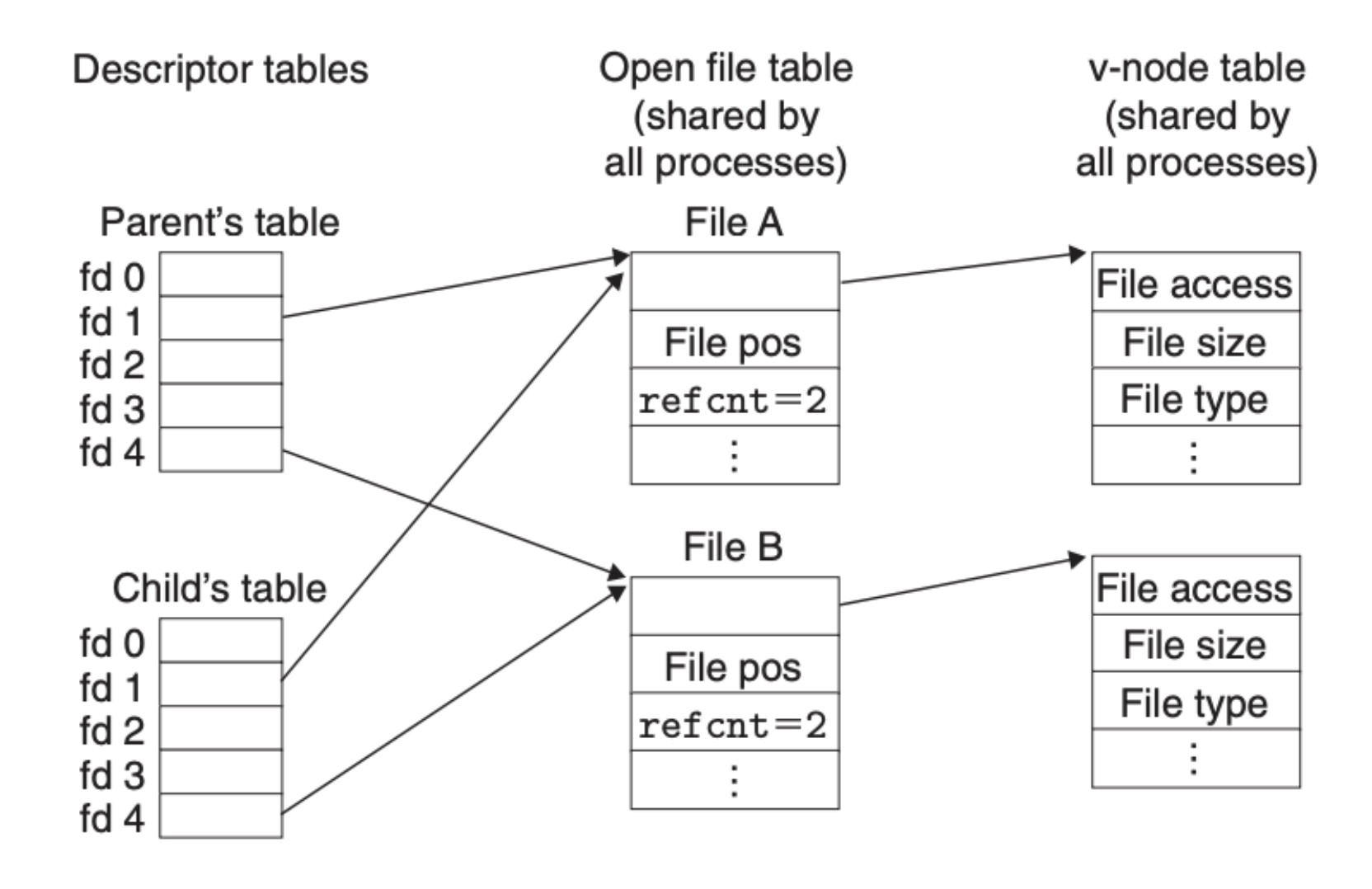
另外,在 CSAPP 第八章 中我们提到了进程创建,父进程和新创建出来的子进程有着同样的文件资源,要实现这一点,我们只需要将文件描述符表复制一份就好,其他的都不需要变化,如下所示:
这里需要注意的是,父进程和子进程都需要通过各自的文件描述符,关闭打开的文件,否则会造成资源泄漏。
I/O 重定向
Linux 提供了 I/O 重定向符号来将文件和标准输入/输出关联起来,使用如下所示:
1
linux> ls > foo.txt
应用程序也可以调用下面这个系统函数来达到一样的效果:
1
2
3
4
#include <unistd.h>
// Returns: nonnegative descriptor if OK, −1 on error
int dup2(int oldfd, int newfd);
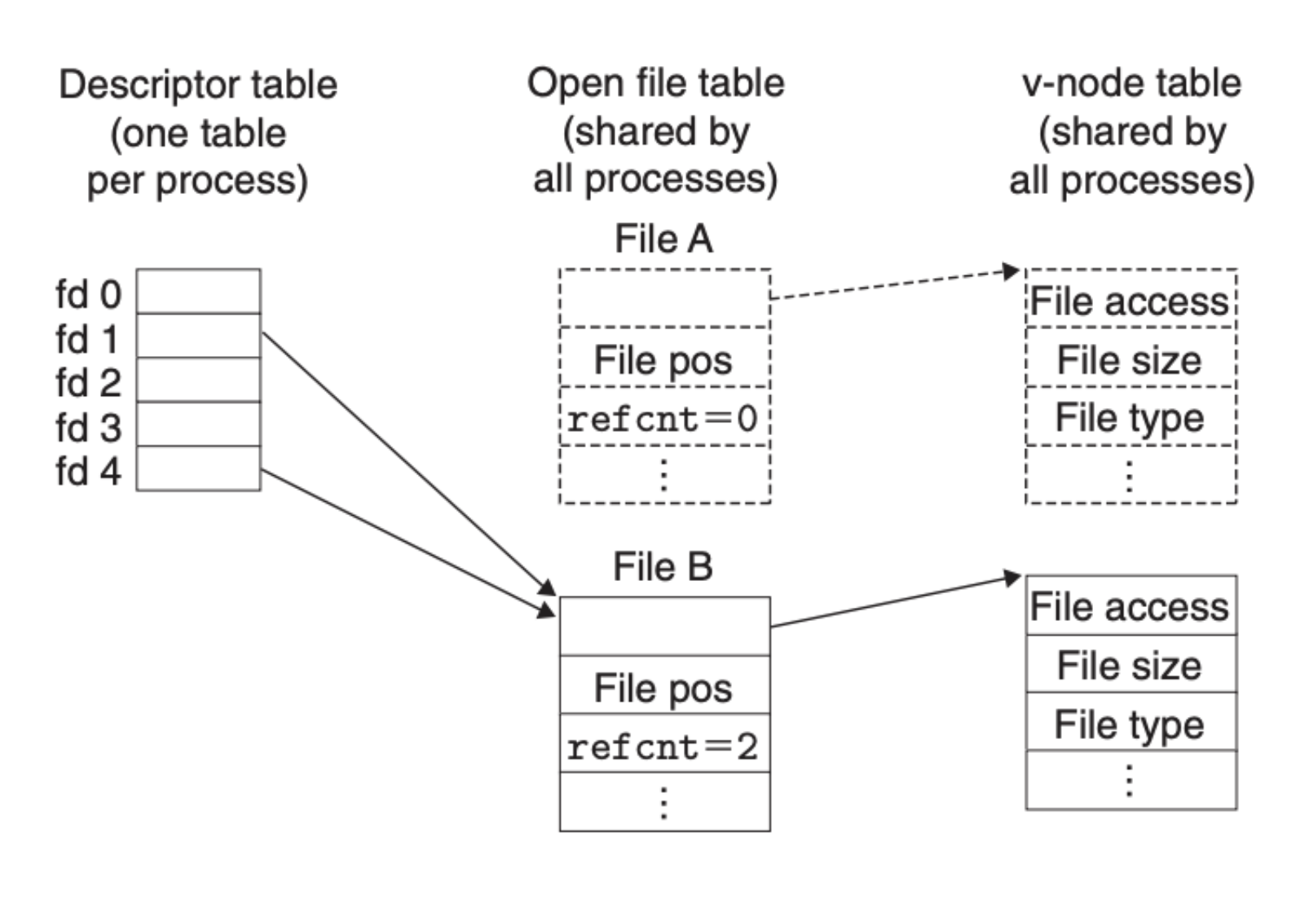
dup2 函数会将描述符 oldfd 拷贝到 newfd,并覆盖之前的值,比如说 dup2(4, 1) 对应的结构变化如下图所示:
总结
关于上面介绍的 I/O 的相关函数,下图可以说明它们之间的关系:
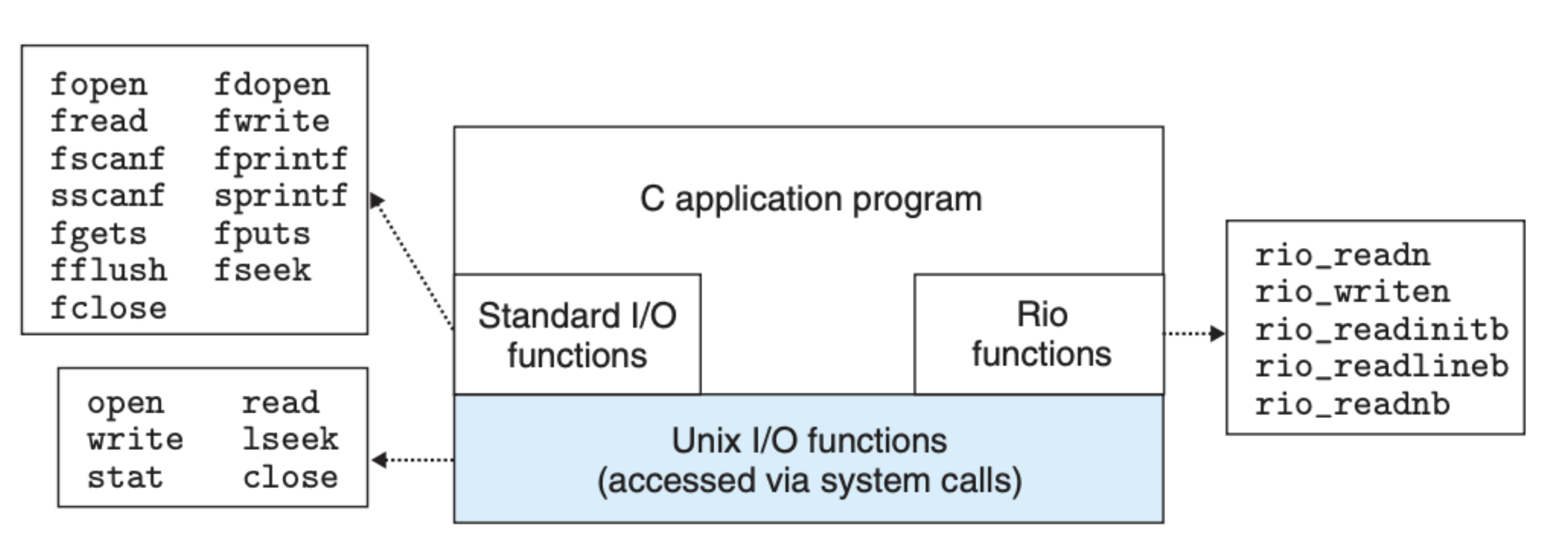
需要注意以下几点:
- 任何时候都优先考虑使用 standard I/O 函数,因为这些函数是为 I/O 量身定制的,并且使用次数也是最多的
- 不要使用
scanf或是rio_readlineb来读取二进制数据,我们前面也说过rio_readlineb会基于\n来判断行,这两个函数都是基于文本文件的 - 使用 RIO 函数来处理网络套接字 I/O