虚拟内存
虚拟内存是什么
我们之前在介绍 CSAPP 第六章——存储器结构 时,提到过内存(主存)是由 DRAM 缓存构成,上接 CPU 内部高速缓存,下接硬盘,具体可以参考下图:
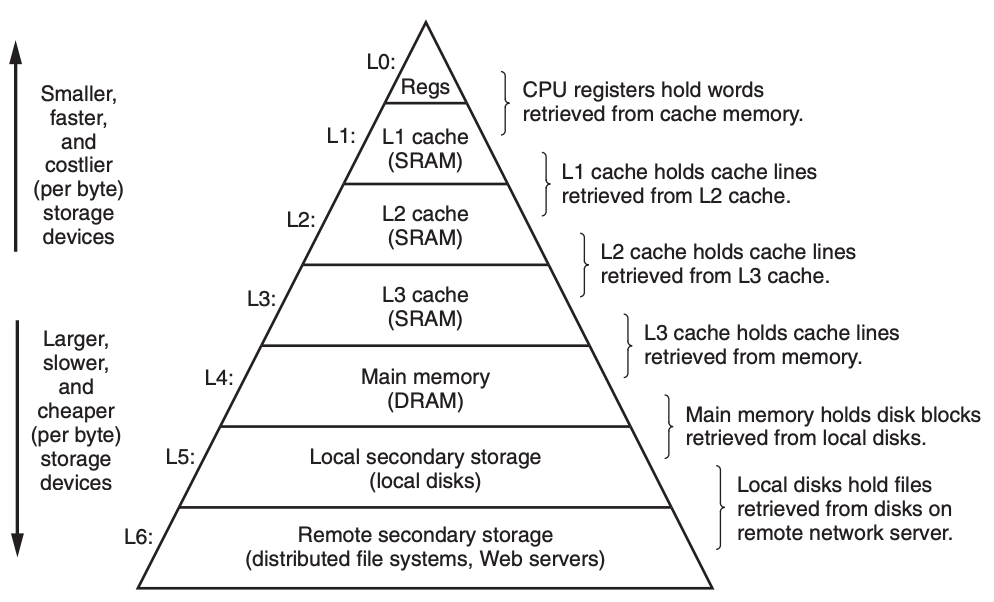
可能从上图中很难发觉内存的重要性,根据数据来看,DRAM 缓存会比 CPU 内部的 SRAM 缓存慢 10 倍,但是比硬盘要快 100000 倍,也就是说如果 CPU 频繁地在内存中获取不到数据,会对整个计算机的性能造成巨大的影响,如何保证内存的命中率是我们重点要考虑的问题。那虚拟内存又是什么东西呢?
我们写的程序基本上都在频繁地和计算机存储单元打交道,每当我们要将一个变量从内存中读取出来,或是将变量写回到内存中去,都少不了 “地址” 这个东西,地址这个概念可能在像 Python,Java 这种高级别的语言中不是很突出,但是如果你接触过 C 或是更加底层的汇编的话,你会发现地址这个东西是程序运行必不可少的成分。那这里的地址是什么呢,是内存的实际地址吗?这说的通,但是想想看这其实会导致诸多的问题。
设想一下,一台计算机上运行着许许多多的程序,每个程序都会使用到内存,但是程序之间如何不产生冲突呢?你可能会说给每个程序分配固定的地址段,但是问题是计算机也不清楚每个程序具体要使用多少的内存资源,有些程序挂在那里,它使用的资源完全由外部网络请求决定,这很难定量,分配少了程序会崩溃,分配多了造成资源的浪费。另外,内存的使用也是分区域的,比如我们所熟知的函数栈、堆内存、程序代码以及程序初始数据等等,这又会给内存的管理增添不少复杂度。那解决办法是什么?
基本上所有的计算机软件的问题都可以通过增加一层抽象解决,而虚拟内存就是在内存之上的一层抽象,程序提供虚拟地址,内存管理单元将虚拟地址转化为实际的内存地址,具体关系如下图所示:
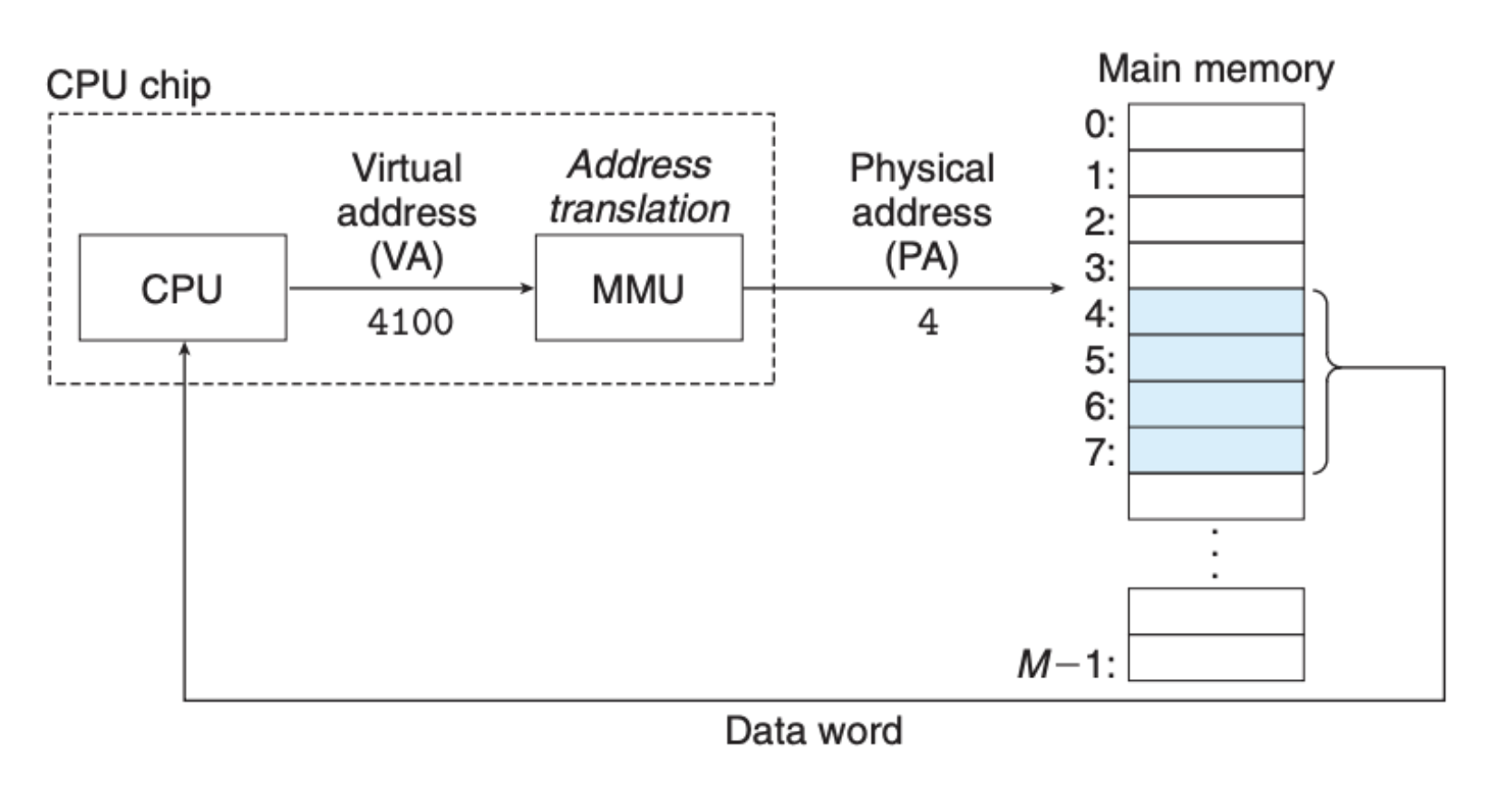
这样一来,从单个程序的视角来看,内存地址变得简单明了,我们不需要去关注其他程序对内存的使用情况,并且我们也不需要去关注虚拟内存是如何具体对应到实际内存地址的,内存管理单元(MMU)会帮助我们进行转化。当然了,为了更好地了解这里发生的事情,我们有必要知道这里面的一些细节。
缓存
研究虚拟内存,我们需要看它在各个方面中的运行机制。我们知道内存会将硬盘或者磁盘的数据缓存起来,这样可以大大提升计算机的效率,那虚拟内存是怎么运作的呢?虚拟内存系统将整个虚拟内存划分为固定大小的虚拟页(virtual page),这个其实就类似我们之前提到的数据块(block),只不过内存中用页(page)来作为统计单位。
虚拟页上的每个地址会存在下面三种情况:
- 未分配:表示这个地址为空,虚拟内存地址没有被分配,实际内存地址上也没有缓存数据
- 未缓存:虚拟内存地址被分配了,但是实际的内存地址并没有缓存数据
- 缓存:虚拟内存地址被分配了,并且实际的内存地址中缓存了数据
这三种情况可以用下图来说明:
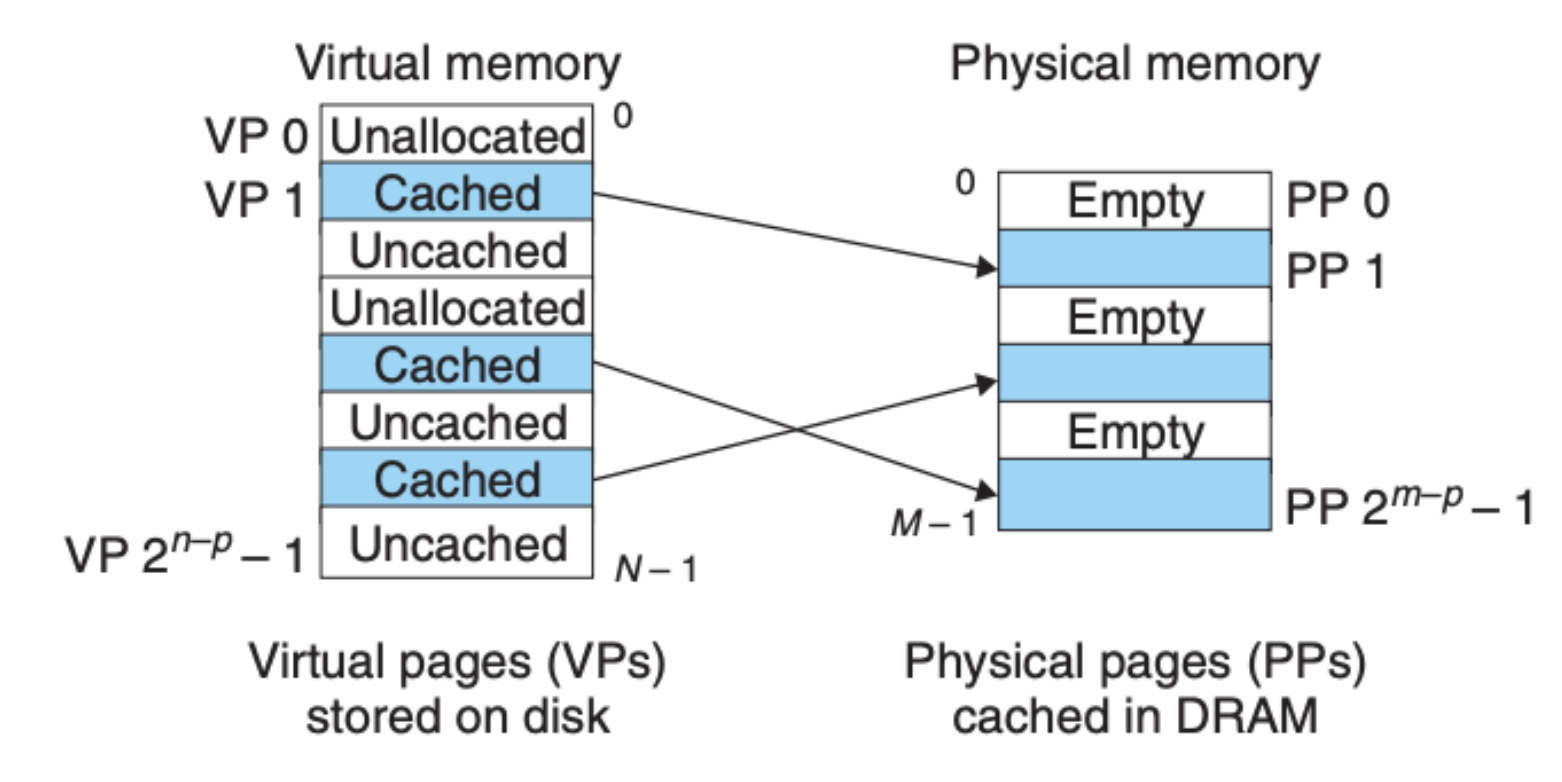
上面我们提到过,DRAM 缓存相比于硬盘或磁盘的效率可谓是天壤之别,内存是计算机中极其重要的存储单元,因为我们要保证最大效率的利用内存,所以整个内存是 全关联 的。什么意思?就是任何的数据都可以存放在任意一个内存单元,任意的虚拟页都可以和任意的实际物理页对应起来,当然,操作系统会对整个内存做分段管理(比如栈区、堆区、代码区等),但是硬件层面对数据的存取没有任何的限制。
另外,内存都是采用 write-back 的读写方式,也就是说每当我们对某个内存地址单元进行写入或者更新,内存会直接响应请求而并不会向下更新硬盘或者磁盘,只有当内存地址上的数据将要被硬盘或磁盘新进入的数据取代时才会向下作更新操作。原因也很好理解,等待硬盘和磁盘的时间开销太大,这样的操作要尽可能地减少或推迟。
页表(Page Tables)
有了虚拟内存还不足以让内存系统如期运作,如何通过虚拟内存来关联物理内存,以及相对应的硬盘数据,这其实需要操作系统、内存管理单元(MMU)以及另外一个数据结构——页表的相互配合来达成的。
页表是什么?我们前面说虚拟内存和物理内存的关系时,提到实际的数据其实是存放在硬盘中的,内存(DRAM)并不能持久化地保存数据,每当计算机掉电重启,内存都会去到硬盘中读取数据,并且会将内存中的数据与硬盘中的数据一一关联起来。只有这样,当数据更新发生时,我们才能保证数据的一致性,而页表这个数据结构就可以帮助我们关联硬盘和内存,具体如下图所示:
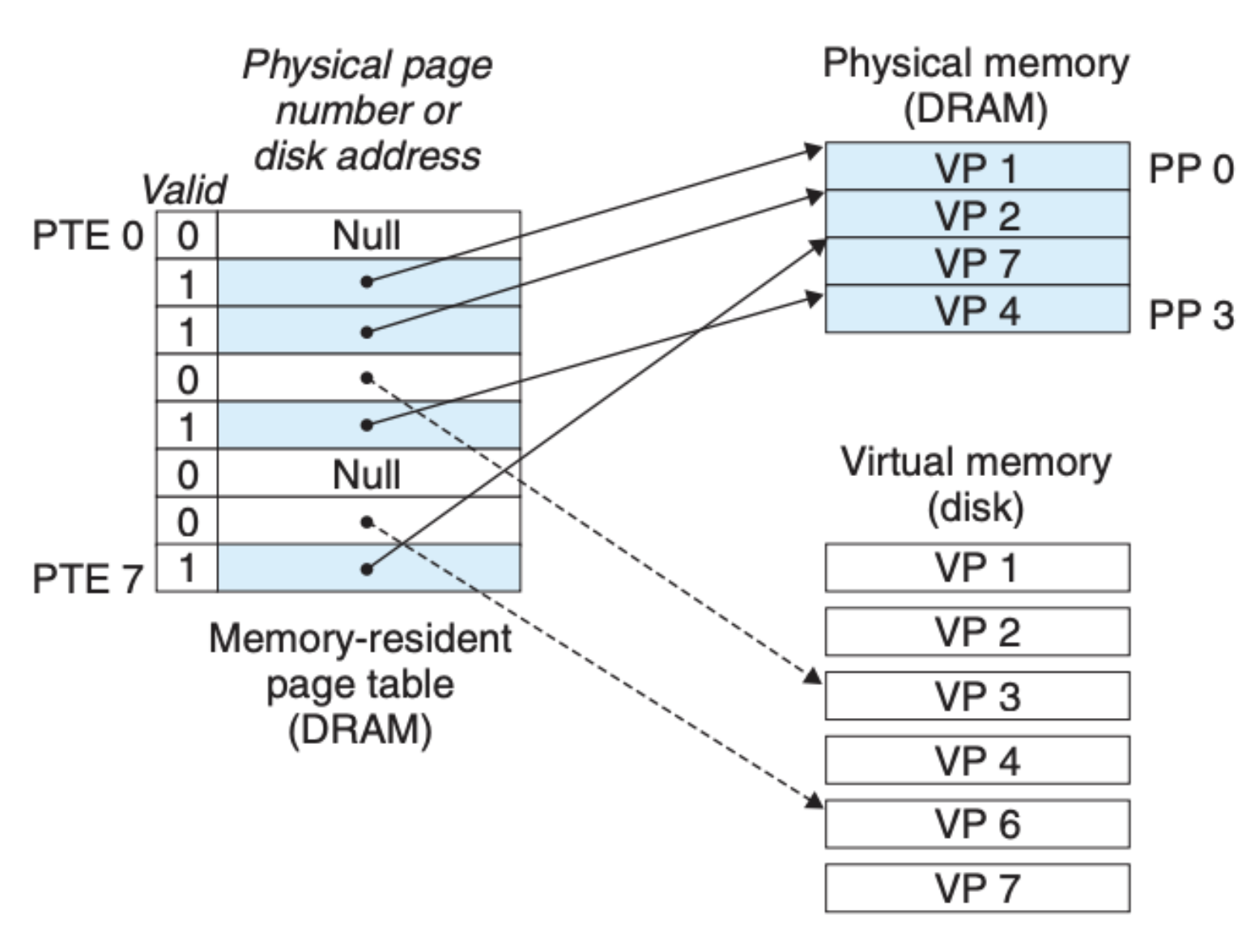
可以看到每个页表是一个页表元素(page table entries,PTE)构成的数组,每个页表元素由有效位和地址单元构成,有效位标明对应的虚拟地址上的数据有没有在物理地址中缓存,这也是我们前面提到的 “缓存” 的情况,另外的两种情况也可以在上图中体现,未分配的地址为空,地址单位为 NULL,未缓存的地址虽然在物理内存中不存在,但是我们可以从硬盘中获取到数据。
这里我们分别基于不同的情况来看看虚拟地址、物理内存以及硬盘是如何关联起来的,首先是缓存命中(page hit):
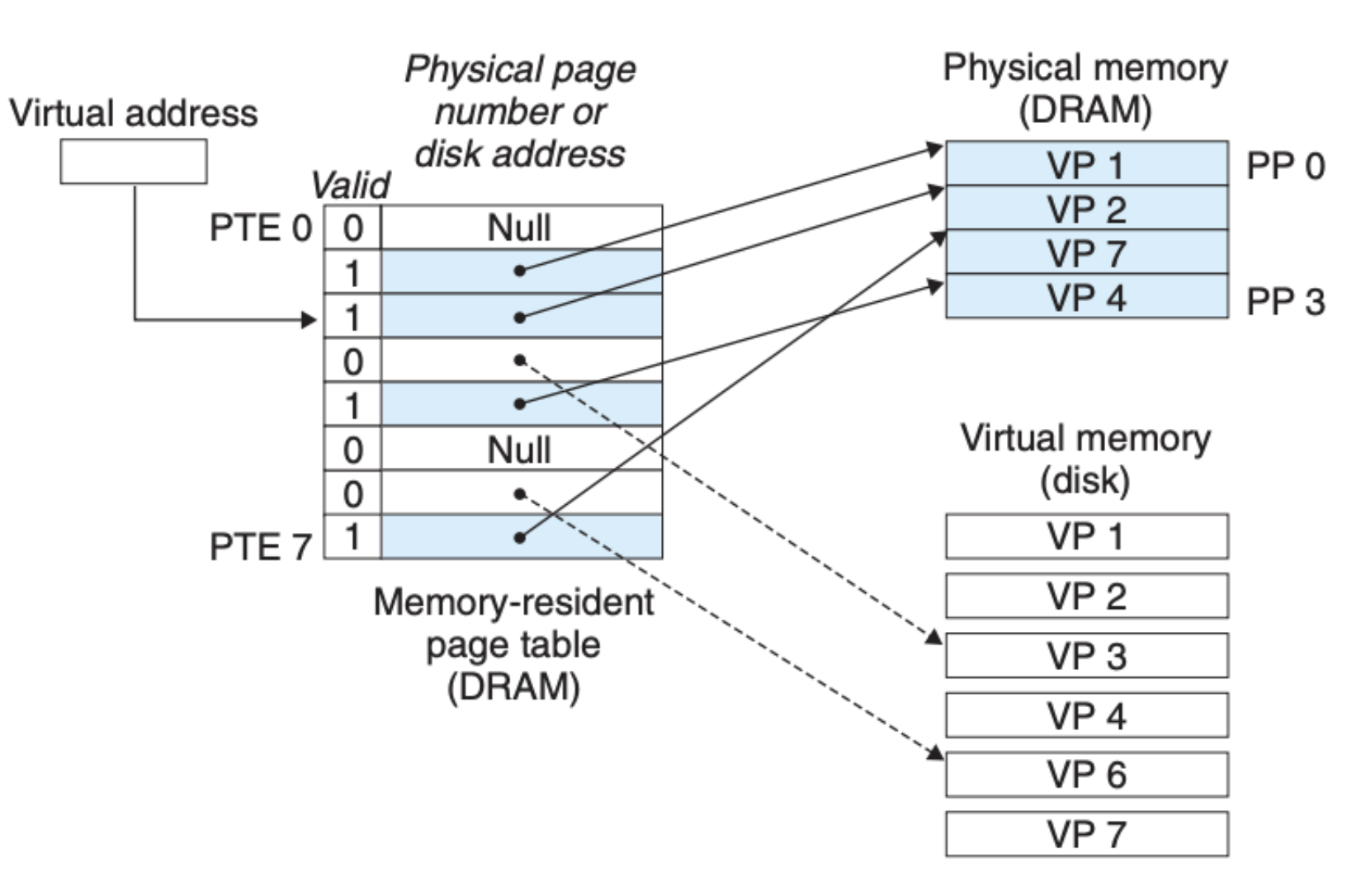
这里我们通过虚拟内存地址对应到页表元素,然后再通过页表元素访问到对应的物理内存地址,最后就可以执行读取或者写入的操作,这也是最为常见的一种情形。
与之对应的就是页缺失(page fault),如下图所示:
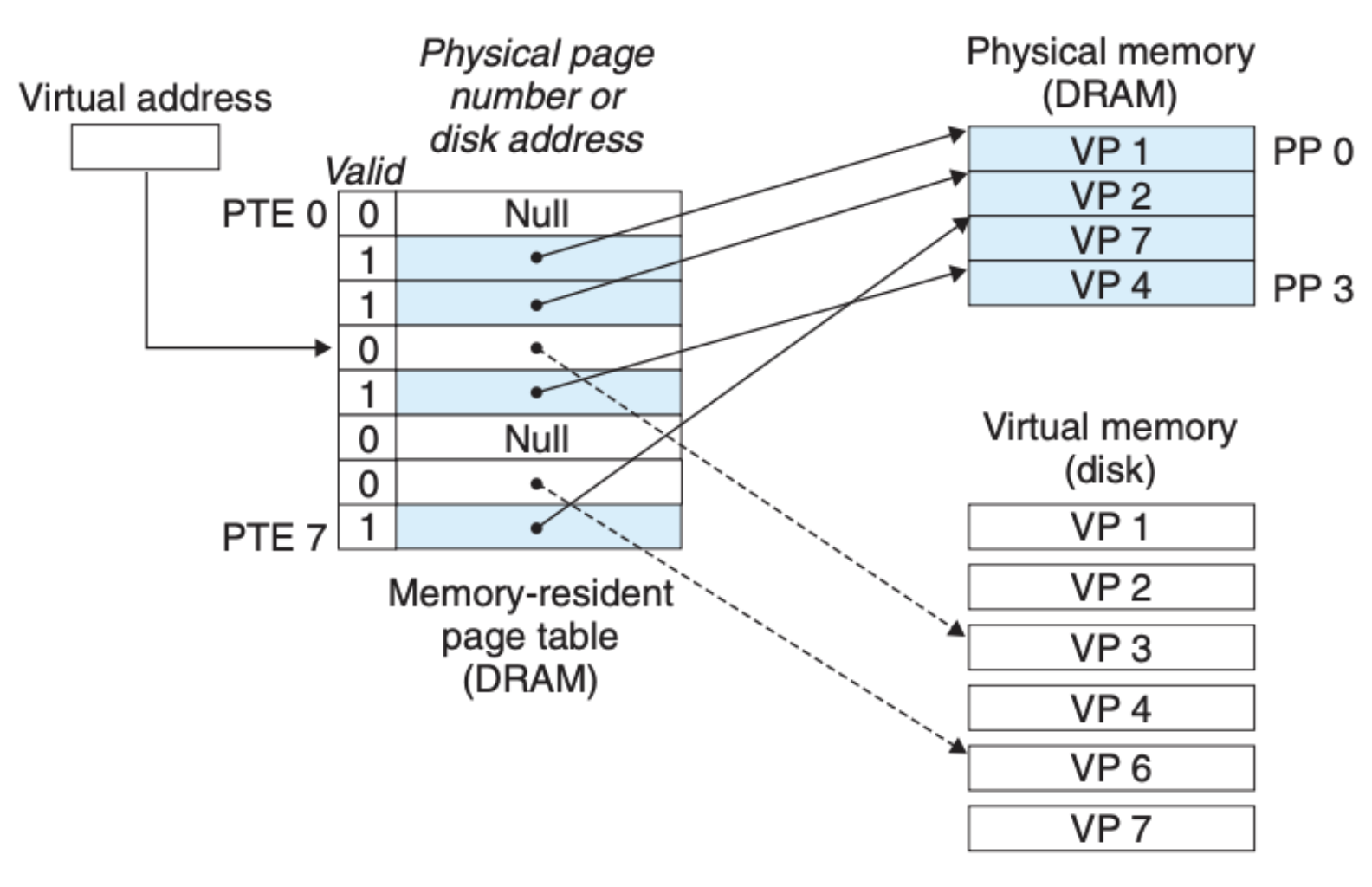
可以看到这里我们访问了一个在内存中没有缓存的地址,这种情况会触发操作系统内核中的处理页缺失的程序,该程序会告知对应的执行单元将硬盘中的数据拷贝到内存中来,如果说内存满了(上面这个情况),那么就覆盖某个地址,完事后就如下图所示:
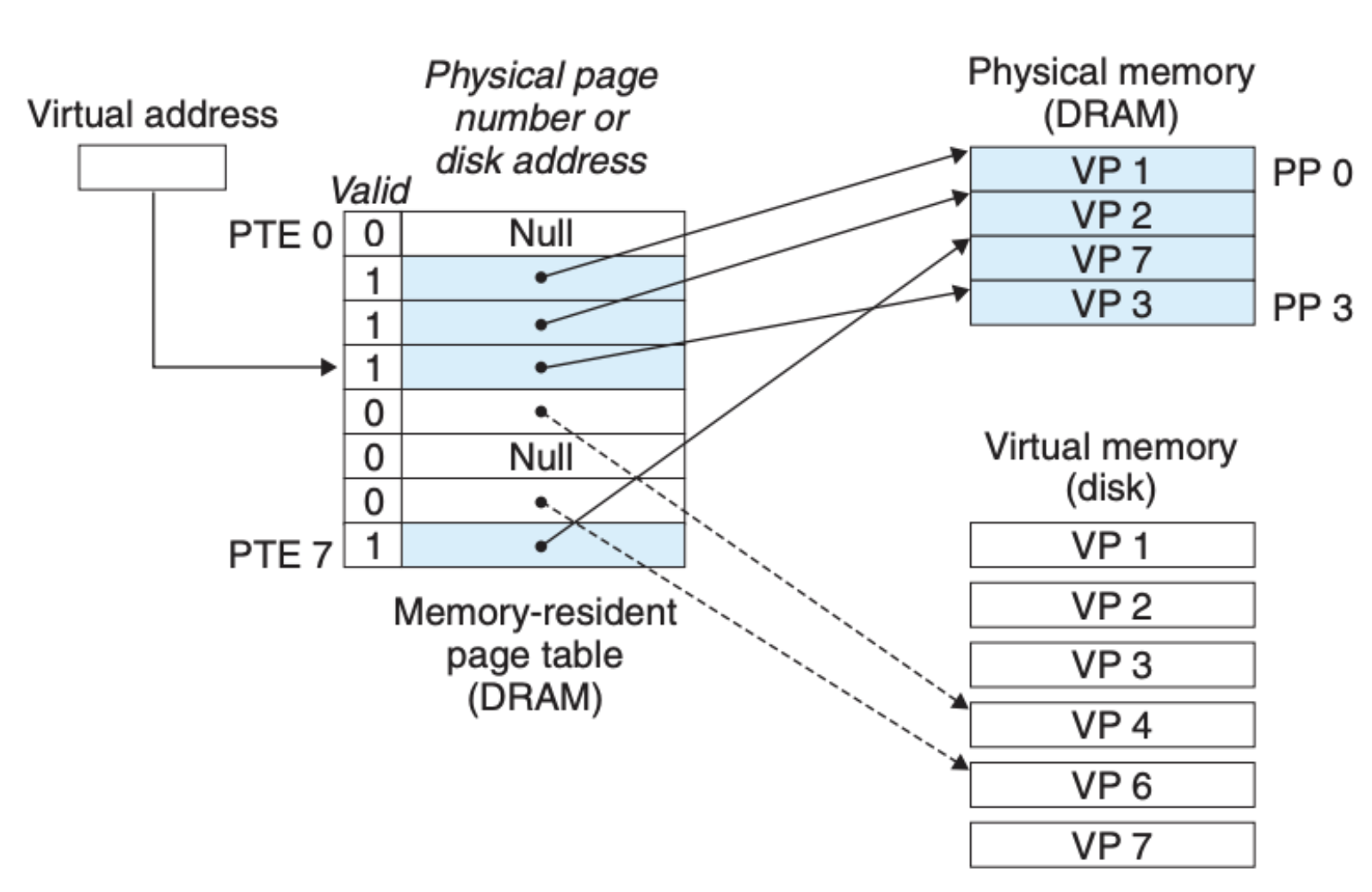
可以看到操作系统内核执行完页缺失的程序后,情况就从 “未缓存” 变成了 “缓存”,这样我们就可以按照前面的页命中的流程来进行数据的读取了。
除了上面这两种情况以外,我们还需要考虑虚拟内存分配的情况,也就是我们需要将页表中的空地址(NULL)关联到指定的硬盘数据,这种情况也是经常发生的,比如我们在 C 程序中通过 malloc 或是 calloc 来分配内存。这其实也很直接,如下图所示:
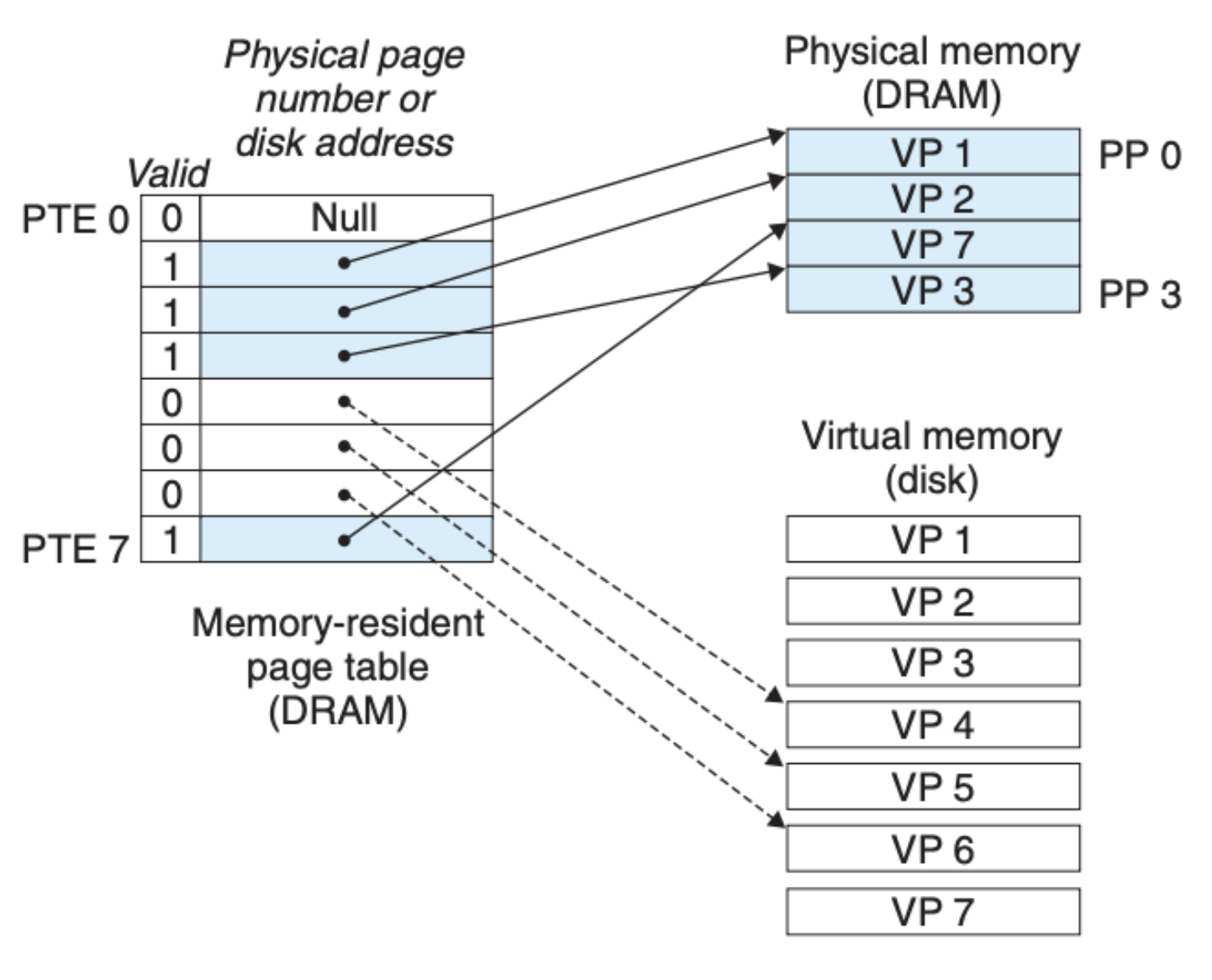
当然了,分配后仅仅是将虚拟地址和硬盘中的地址关联了起来,如果程序读到了这个地址就会触发页缺失,然后物理内存中才会存放这部分数据。
需要特别注意的是,这些图上显示的 VP 并不是我们通常看到的单个内存地址或是单条数据,而是一整个页数据,是一个数据块。每当 CPU 读取内存中的某条数据,包含这条数据的整个页都会被读取进 CPU 模块的高速缓存中,这样 CPU 继续读取该页中的其他数据也不需要重新到内存中获取了,反过来说,如果程序频繁地引用不同页的数据,那么这就会降低缓存命中率,从而影响程序整体的运行效率,这也是我们前面说计算机存储结构时提到的 代码局部性。
内存保护
虚拟内存除了在缓存中帮助协调和管理内存,另一个好处是它可以在内存之上建立一套权限管理机制,更好地保护内存。为什么这一点很重要?因为我们前面提到过,为了保证效率,内存在硬件层面是全关联的,所有的内存单元都没有区别,但是内存又要为不同的程序提供服务,这里就会有些权限上的要求,比如说下面这些要求:
- 用户的程序不能访问操作系统内核的代码和数据结构
- 某个程序的私有内存空间不能被其他的程序所访问
- 共享的库函数是不能被其他程序所修改的
并且,我们知道多个虚拟内存页可以被映射到单个物理内存页,因此我们需要对不同的程序设定不同的虚拟内存权限,这一点可以通过在页表上面增加新的比特位来达成:
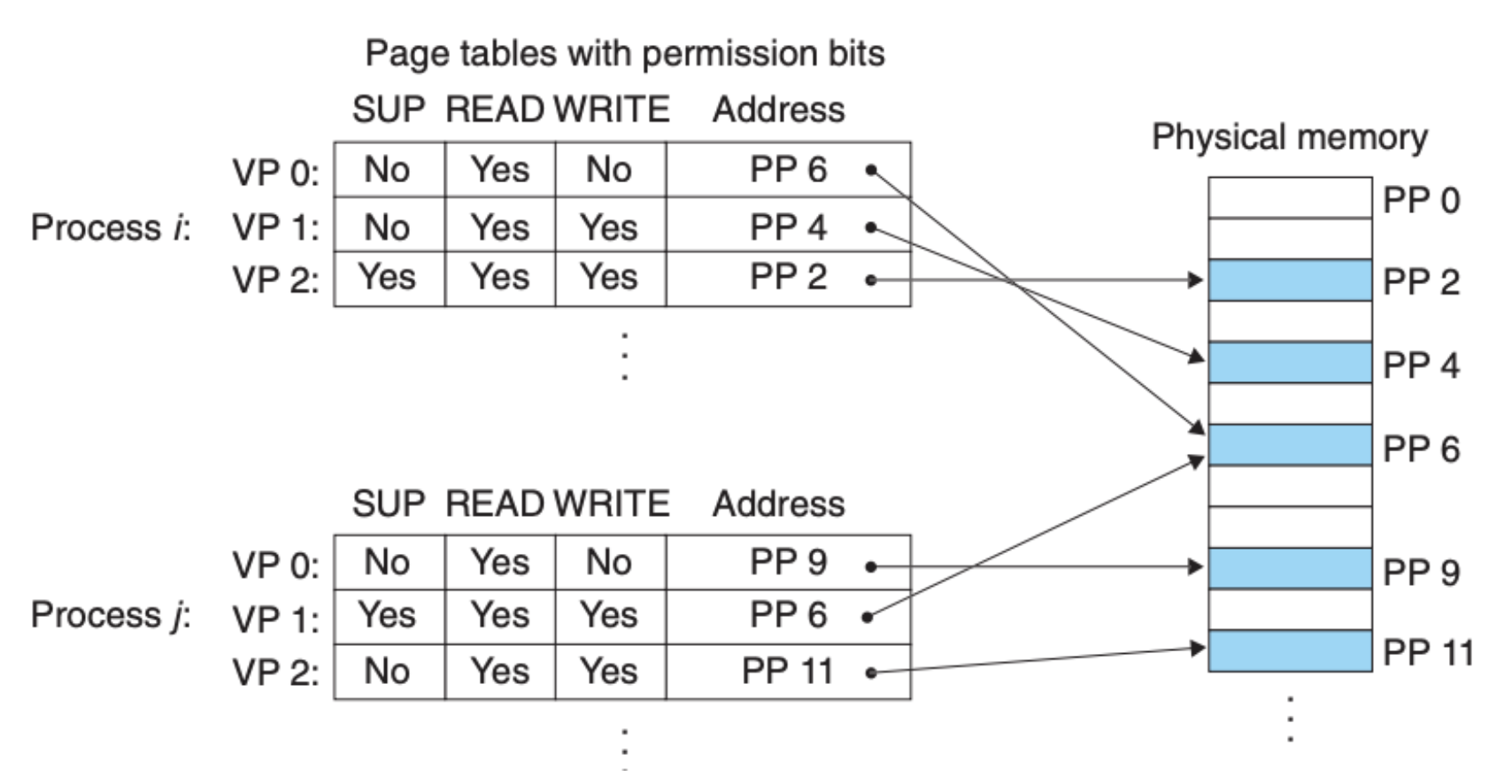
地址转换
明白了虚拟内存的目的以及组成结构,另外一个核心问题就是虚拟内存是如何转化成物理内存的。这里我们先引入一些符号,这样我们后面讲的时候会清晰一些,当然,一开始我们并不需要完全清楚每个符号的具体意义,这在后面都会具体给出,这里只是有个大概的印象就好:
| Symbol | Description |
|---|---|
| Basic parameters | |
| $N = 2^n$ | Number of addresses in virtual address space |
| $M = 2^m$ | Number of addresses in physical address space |
| $P = 2^p$ | Page size (bytes) |
| Components of a virtual address (VA) | |
| VPO | Virtual page offset (bytes) |
| VPN | Virtual page number |
| TLBI | TLB index |
| TLBT | TLB tag |
| Components of a physical address (PA) | |
| PPO | Physical page offset (bytes) |
| PPN | Physical page number |
| CO | Byte offset within cache block |
| CI | Cache index |
| CT | Cache tag |
首先,内存地址单元(MMU)是如何进行地址转换的?MMU 获取信息的主要来源是我们前面提到的页表,程序提供的虚拟内存地址被拆分成 VPN 和 VPO 两部分,MMU 通过页表寄存器(PTBR) 定位到当前的页表,然后再利用虚拟内存中的 VPN 部分定位到具体的页表元素,这样我们就可以通过页表元素中存放的 PPN 组合虚拟内存的另外一部分 VPO 来生成物理地址,具体可以参考下图:
![]()
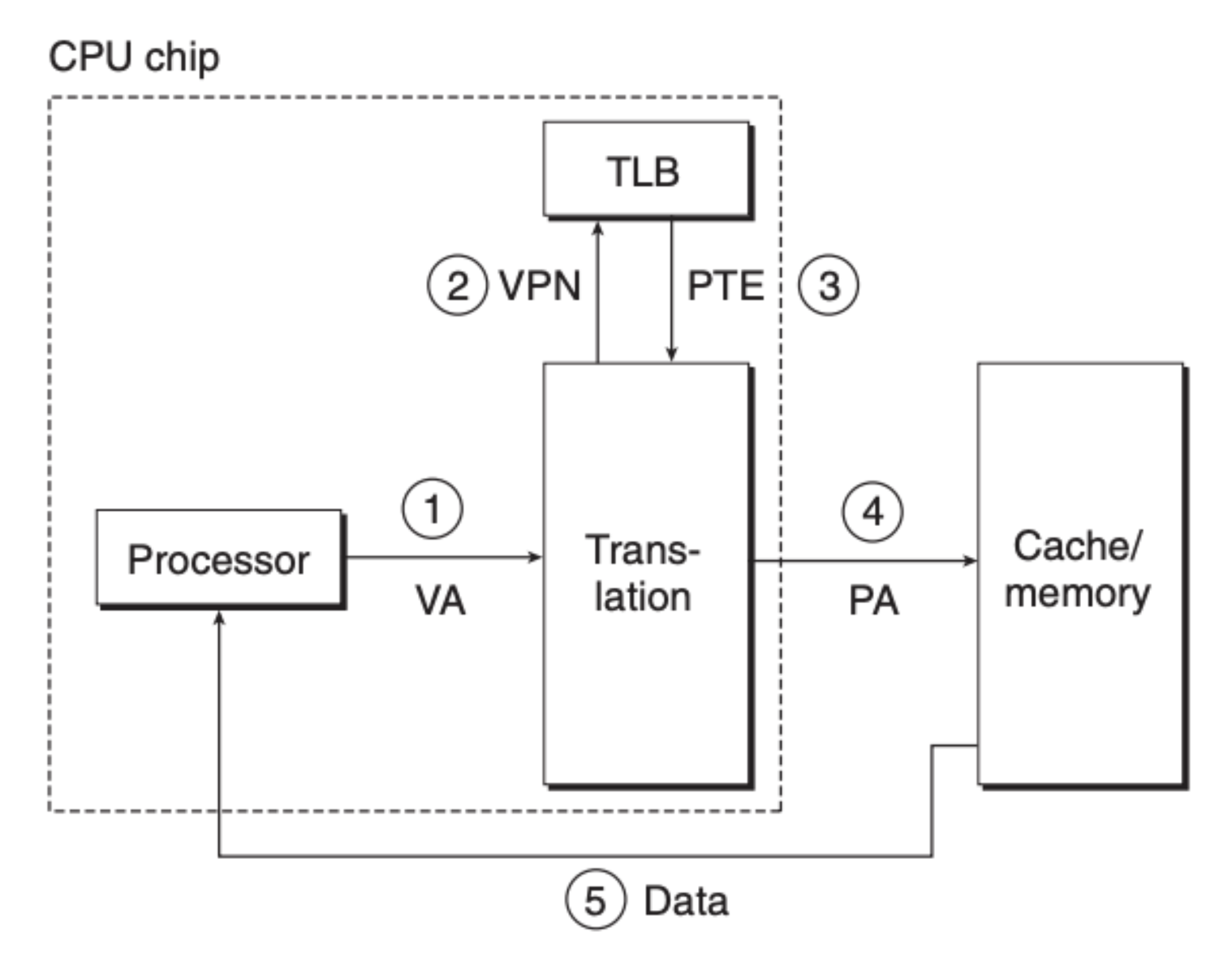
我们再来结合前面说的页命中和页缺失来看看具体步骤,首先是页命中:
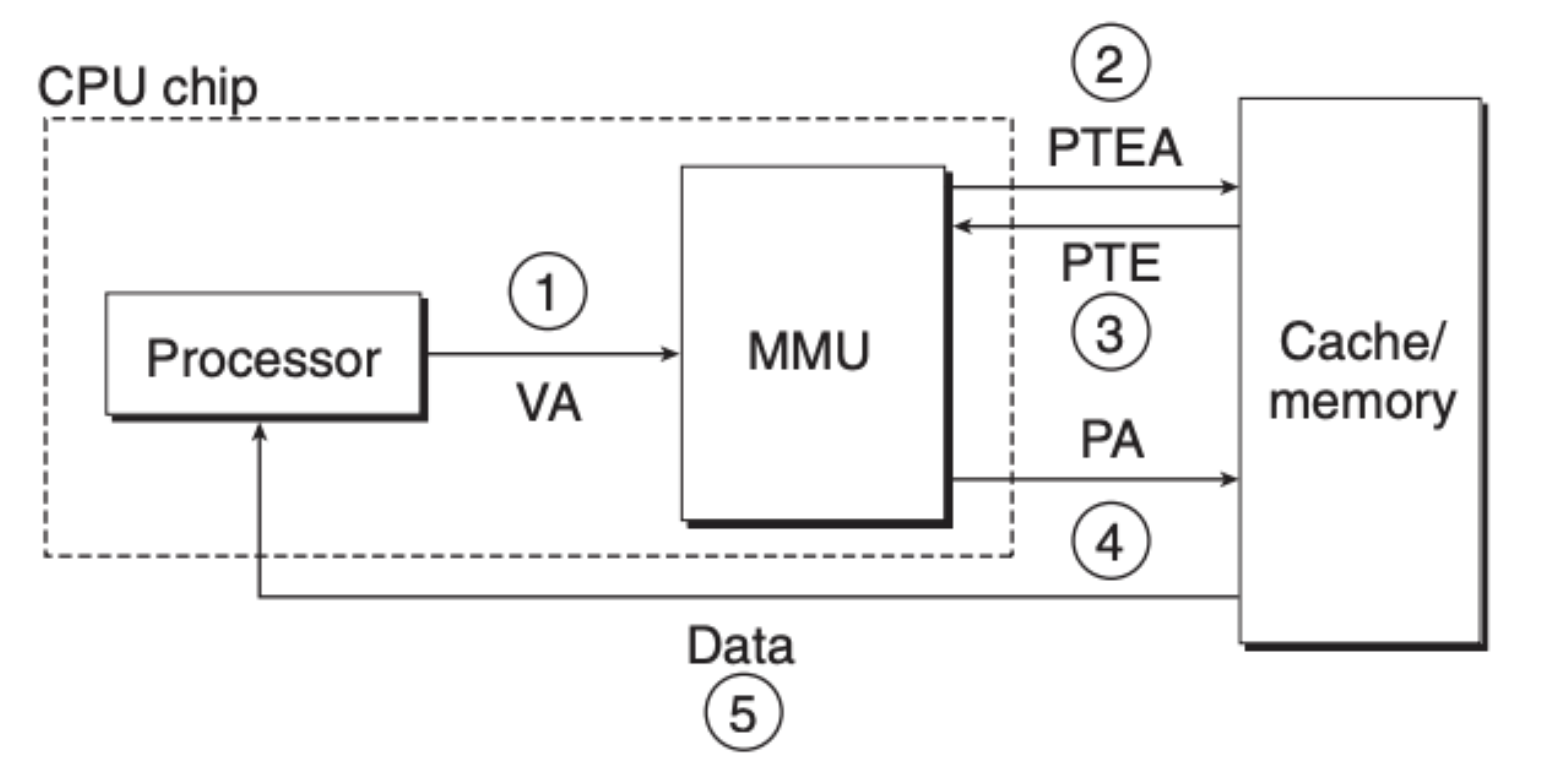
- 第一步,程序将虚拟内存地址交由内存地址单元(MMU)
- 第二步,MMU 通过 PTBR 寄存器定位到页表,并将虚拟内存分成 VPN 和 VPO 两部分,并用 VPN 来定位页表元素
- 第三步,MMU 获取到了页表元素 PTE
- 第四步,MMU 分析 PTE 的有效位,如果有效,组合生成物理地址并请求内存
- 第五步,内存返回数据给 CPU/程序
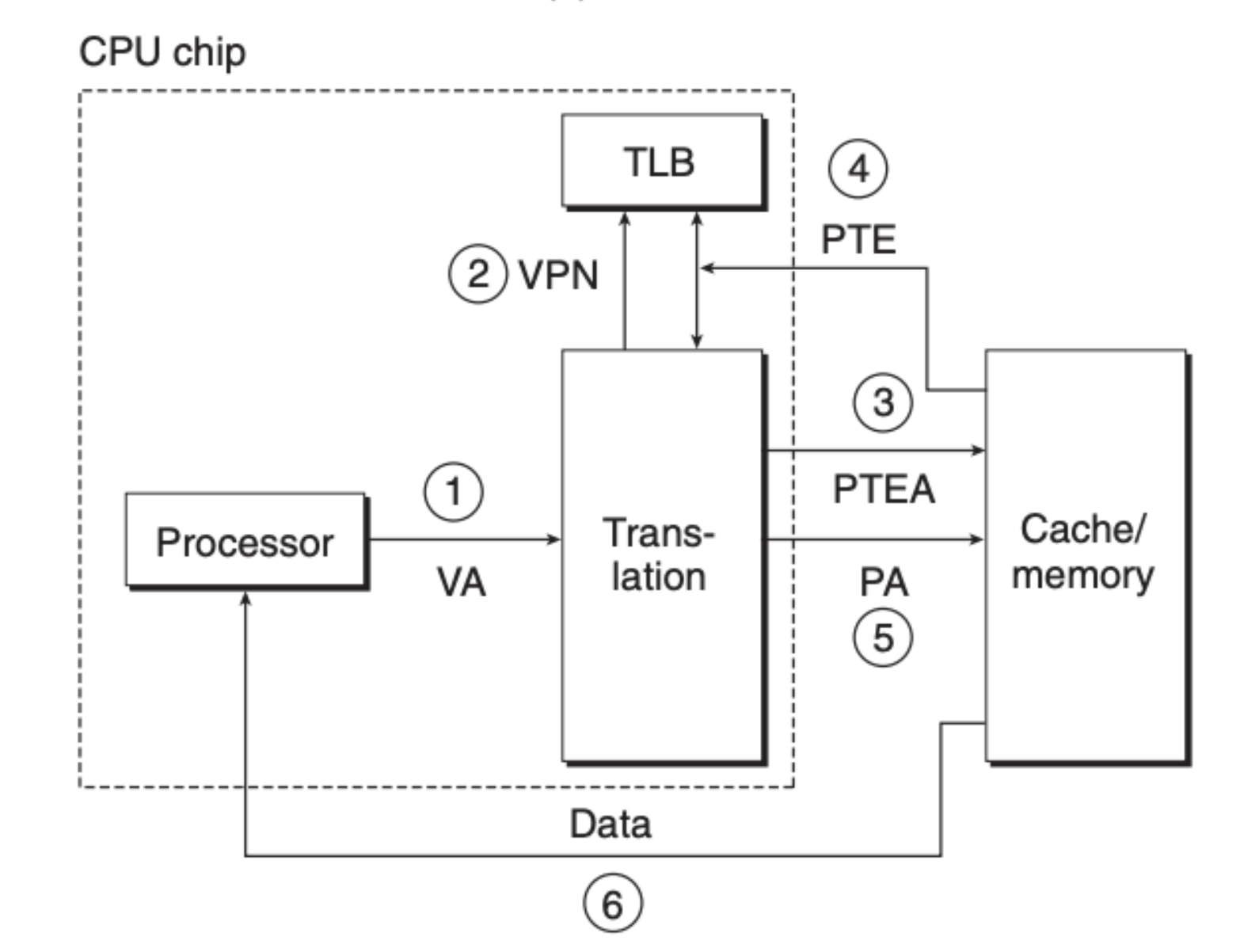
页缺失的话会复杂一些,但也只是在页命中的基础上增加了几个步骤:
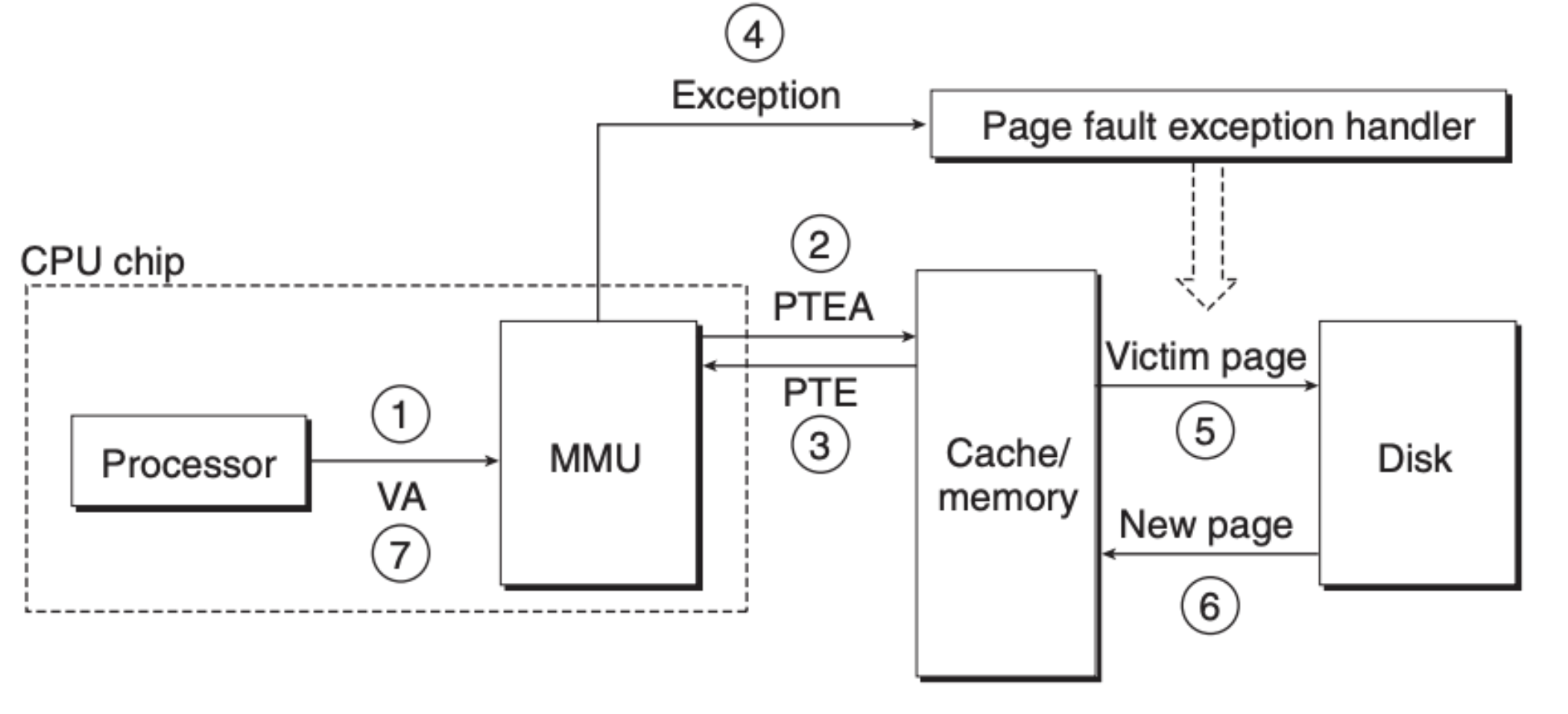
- 第一步,程序将虚拟内存地址交由内存地址单元(MMU)
- 第二步,MMU 通过 PTBR 寄存器定位到页表,并将虚拟内存分成 VPN 和 VPO 两部分,并用 VPN 来定位页表元素
- 第三步,MMU 获取到了页表元素 PTE,发现数据并没有在内存中缓存
- 第四步,MMU 触发操作系统 Page Fault 异常,程序执行权转交到内核,内核运行对应的处理异常的程序
- 第五步,内存向硬盘索取缺失的页数据
- 第六步,硬盘返回对应的数据到内存,内存并告知 CPU
- 第七步,CPU 再重新发送请求到 MMU,此后的步骤就和页命中一样了
考虑高速缓存和 TLB
上面的例子仅仅是考虑了 MMU 和内存,可我们知道,通常来说,CPU 和内存之间都会有多个高速缓存,因此我们也要在原来流程的基础之上将高速缓存考虑进去,大致如下图所示:
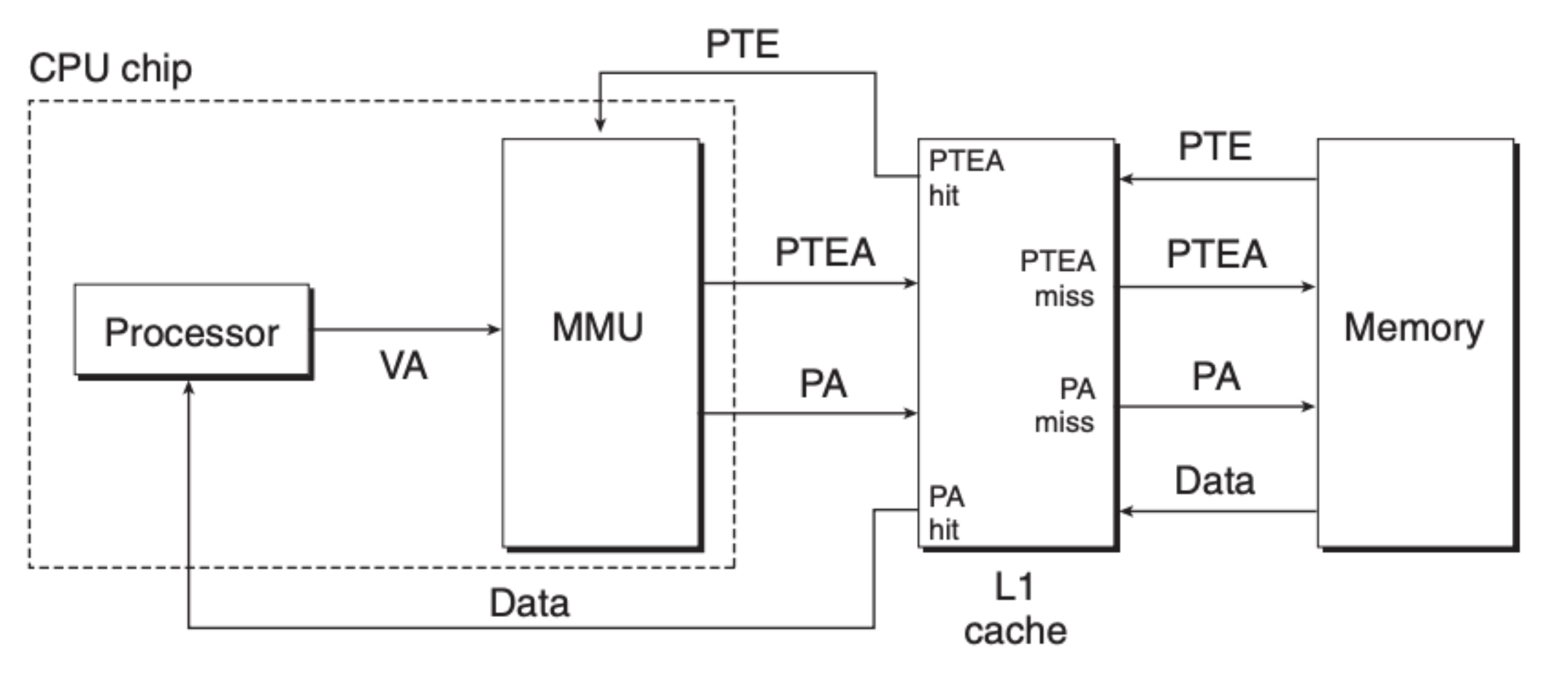
可以看到的是,高速缓存不仅仅帮助缓存最终数据,还缓存了页表元素。通过这样的多级缓存可以有效提升寻址的效率。
按理说,这样的地址转化已经非常高效了,但是高速缓存毕竟是缓存最终内存数据的,而且空间很有限,如果将类似页表这样的中间数据也缓存其中,则会占据比较大的空间,为了进一步优化,我们引入了一个新的单元——Translation lookaside buffer(TLB)。
MMU 可以请求 TLB 并拿到对应的页表元素,TLB 可以看作是对页表元素的一层缓存,具体流程可以参考下面两张图:
TLB 也是基于虚拟内存地址中的 VPN 部分来进行索引的,具体来说 VPN 被拆分成两部分,如下图所示:
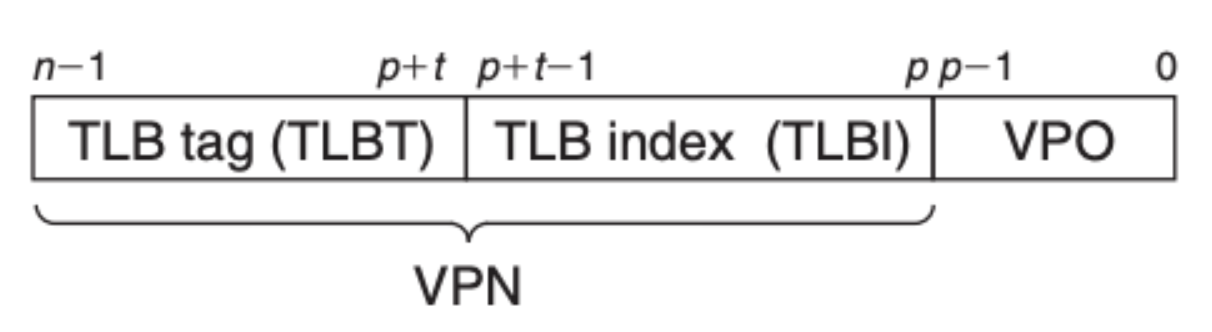
具体的寻址可以参考 CSAPP 的第六章,类似于 SRAM 的寻址。
多级页表
通过上面的讲述,我们知道要想通过虚拟内存定位到物理内存,页表是必不可少。但是页表的大小就成了一个需要考虑的因素,因为页表也是存放在内存中的,同样需要消耗内存资源,如果我们把生成的所有页表数据通通都放在内存中,那么这些中间数据就会造成内存无法存放更多的最终数据,从而使内存的利用率大大下降。
解决这个问题的办法就是多级页表,我们先来看看一个二级页表的结构:
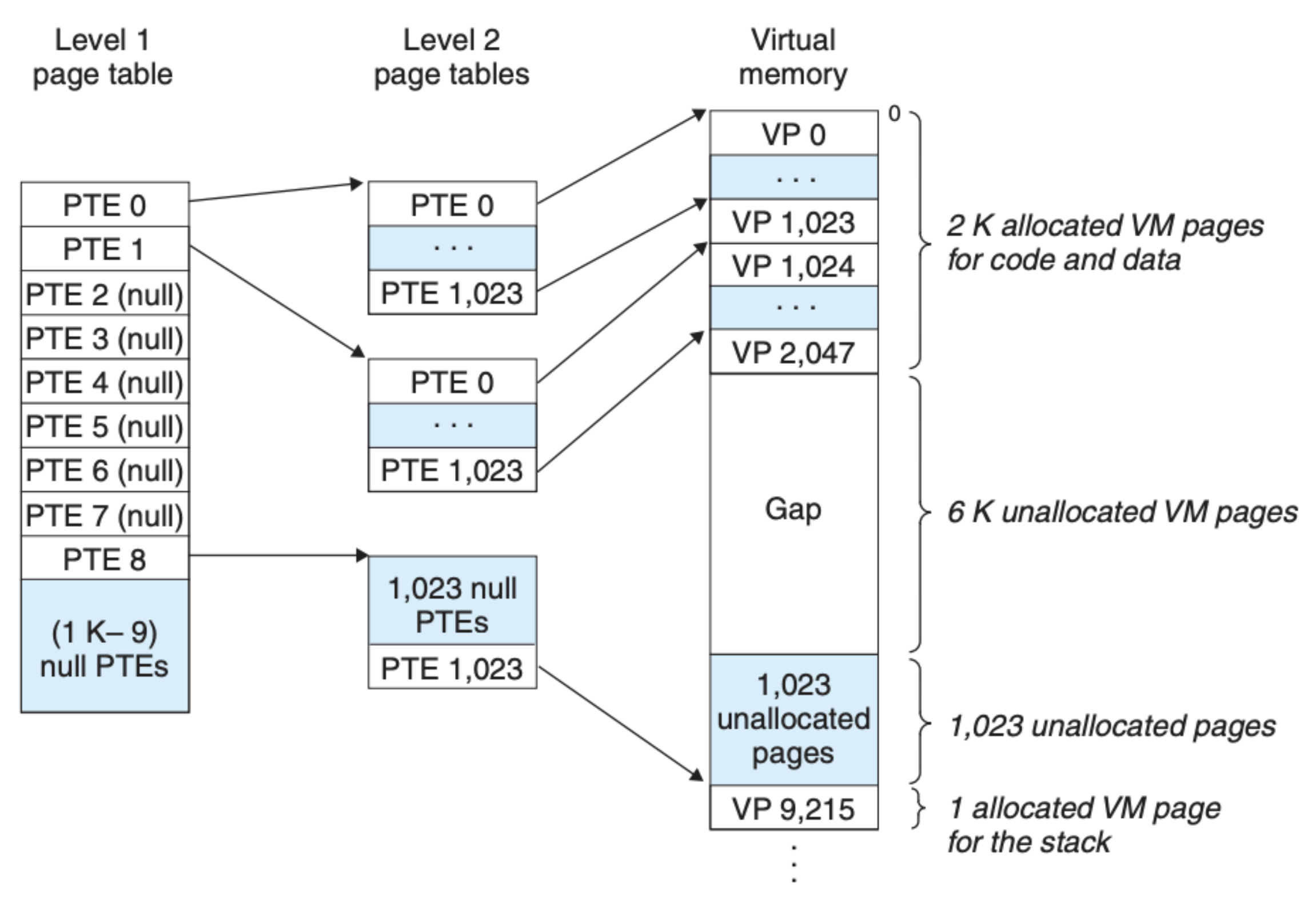
可以看到一级页表中存放的页表元素指向的是二级页表,然后二级页表元素才指向最终的物理内存页。这样的结构又是如何减少资源的呢?这不是又增加了更多的中间数据吗?
多级页表主要通过下面两方面来减少页表数据对内存的开销:
- 可以看到,如果一级页表元素为空(NULL),那么二级页表就没有存在的必要了。内存并不是时时刻刻都是 100% 被占用的(像我现在的个人计算机通常内存的占用率只有 20% 左右),这样就可以大大减少 未分配 的内存在页表中出现的次数
- 我们只需要在内存中缓存一级页表,因为二级页表也是基于一级页表创建出来的,并且很多时候我们可以仅仅缓存使用频率高的二级页表,这样可以有效地降低内存的压力
当然了,在实际情况中我们通常应用的是 k 级页表,如下图所示:
![]()
可能我们会对这个结构的运行效率有质疑,但是 TLB 会帮助我们缓存不同级别的页表数据,现实中真正访问所有级别的页表的情况并不常见,因而效率并没有明显的下降。
实际案例
为了将我们上面讲的东西串起来,这里我们来看一个实际的案例。假设虚拟内存和物理内存的大小如下所示:
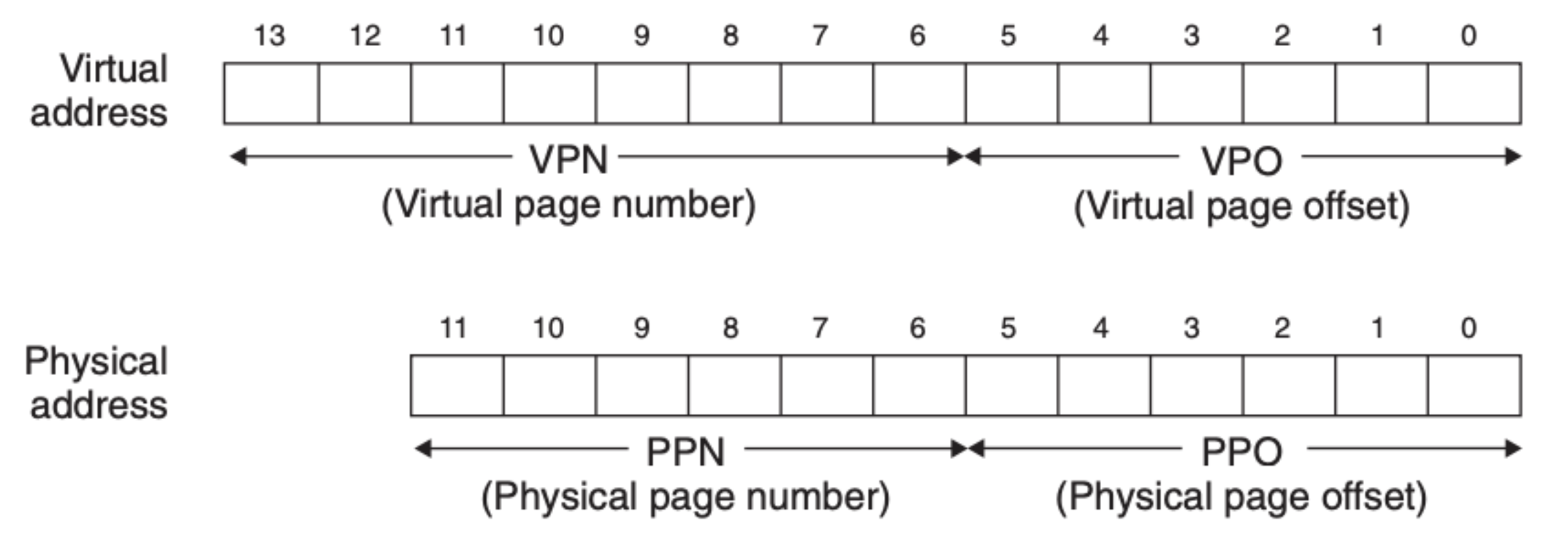
我们假设每页的大小是 64 字节,另外 TLB 的情况如下图所示:
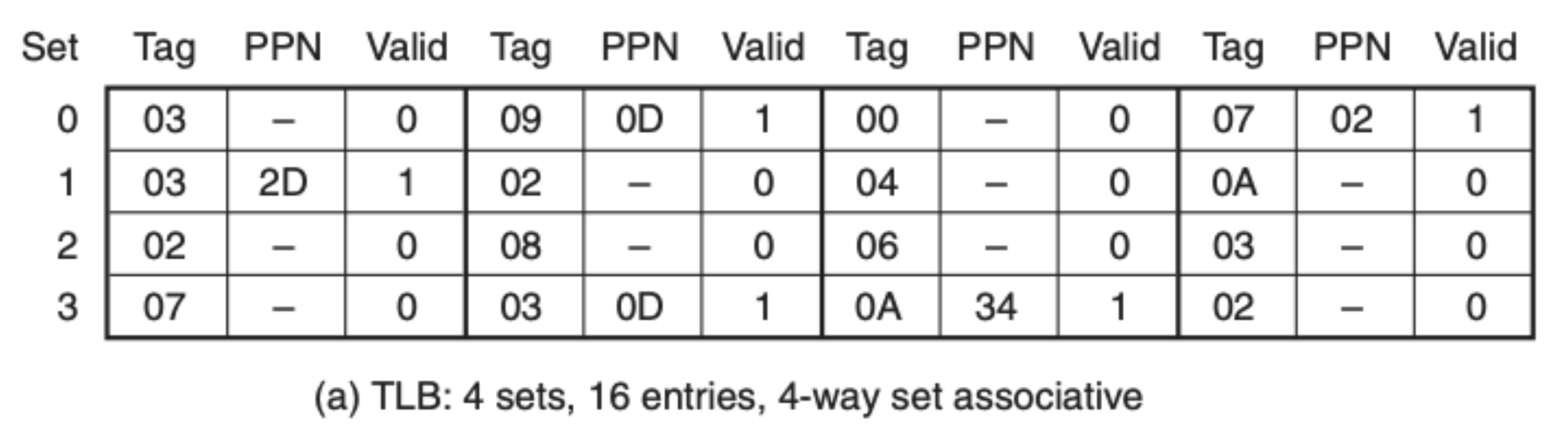
还有页表:
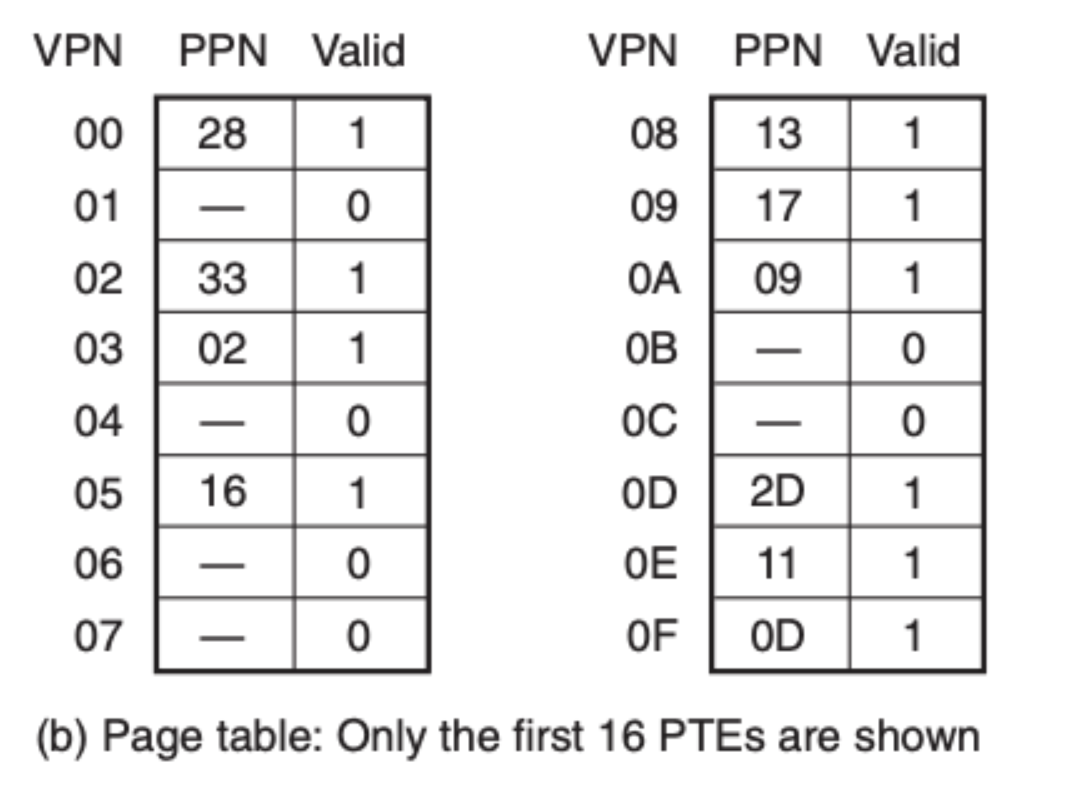
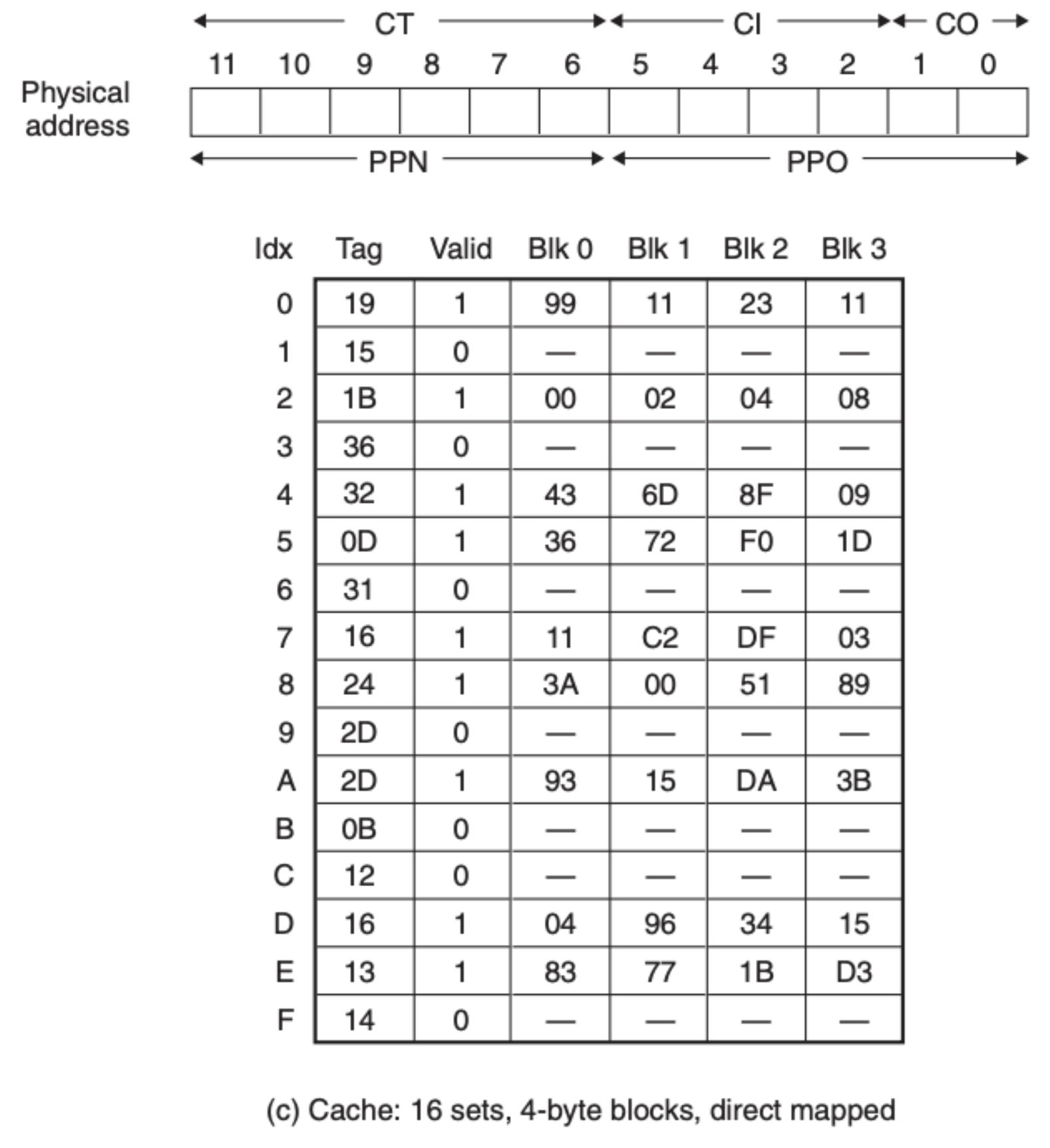
最后是内存:
现在假设说程序需要读取虚拟地址为 0x03d4 处的数据,首先内存地址单元(MMU)会发送请求到 TLB,TLB 会根据虚拟地址的 VPN 部分进行寻址,具体如下图所示:
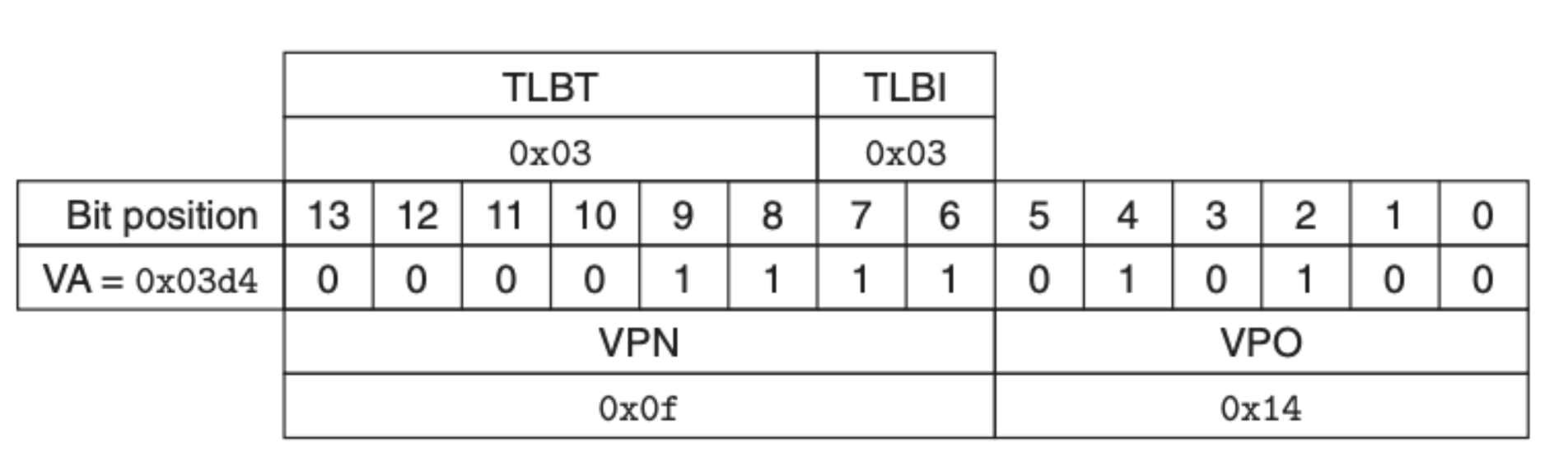
可以看到在 TLB 中的是缓存了页表元素的,我们直接可以拿到 PPN,为 0x0D,然后我们在就可以得到物理地址,通过物理地址来找到数据:
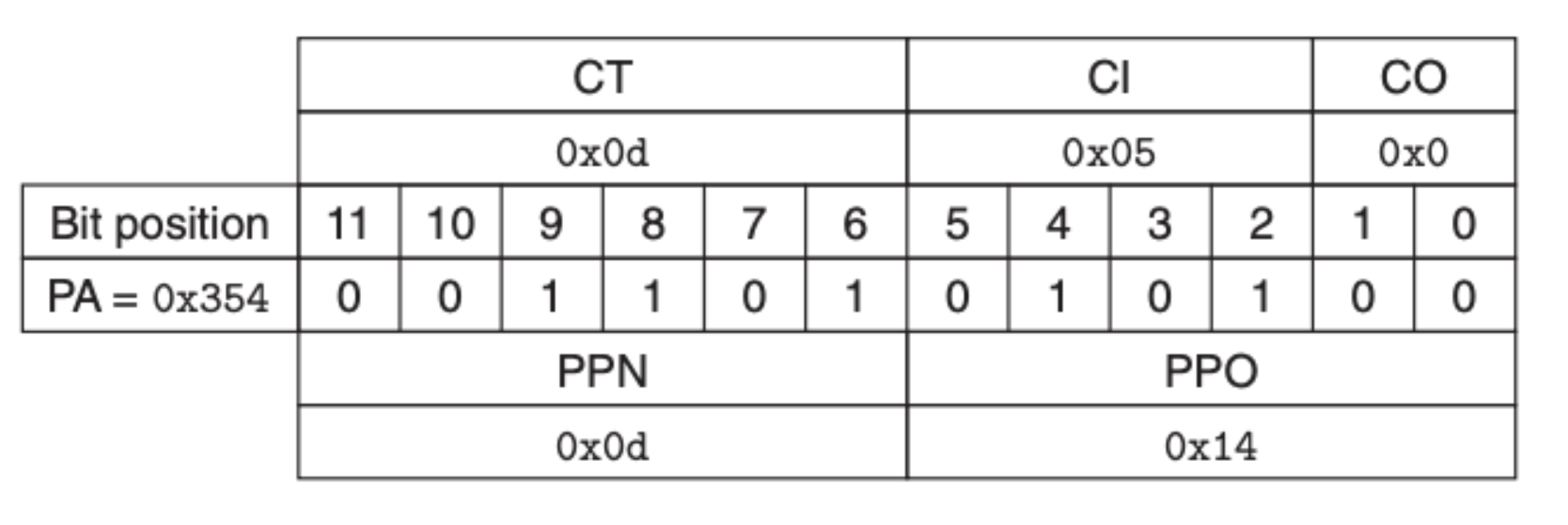
我们通过 CI 定位到索引,然后在通过 CT 和 CO 找到我们要的数据——0x36。当然了,这里 TLB 是命中的,如果没有命中的话我们还需要去到页表中获取 PPN,另外这只是一个简化版,我们并没有考虑 CPU 模块内的高速缓存,考虑的话过程还是一样的,前面已经介绍过,这里就不过多赘述。
Intel i7 的内存系统
上面说的这些内容都是原理性的,可能我们会觉得离我们有些远,这里我们来看看 Intel i7 CPU 模块的结构图:
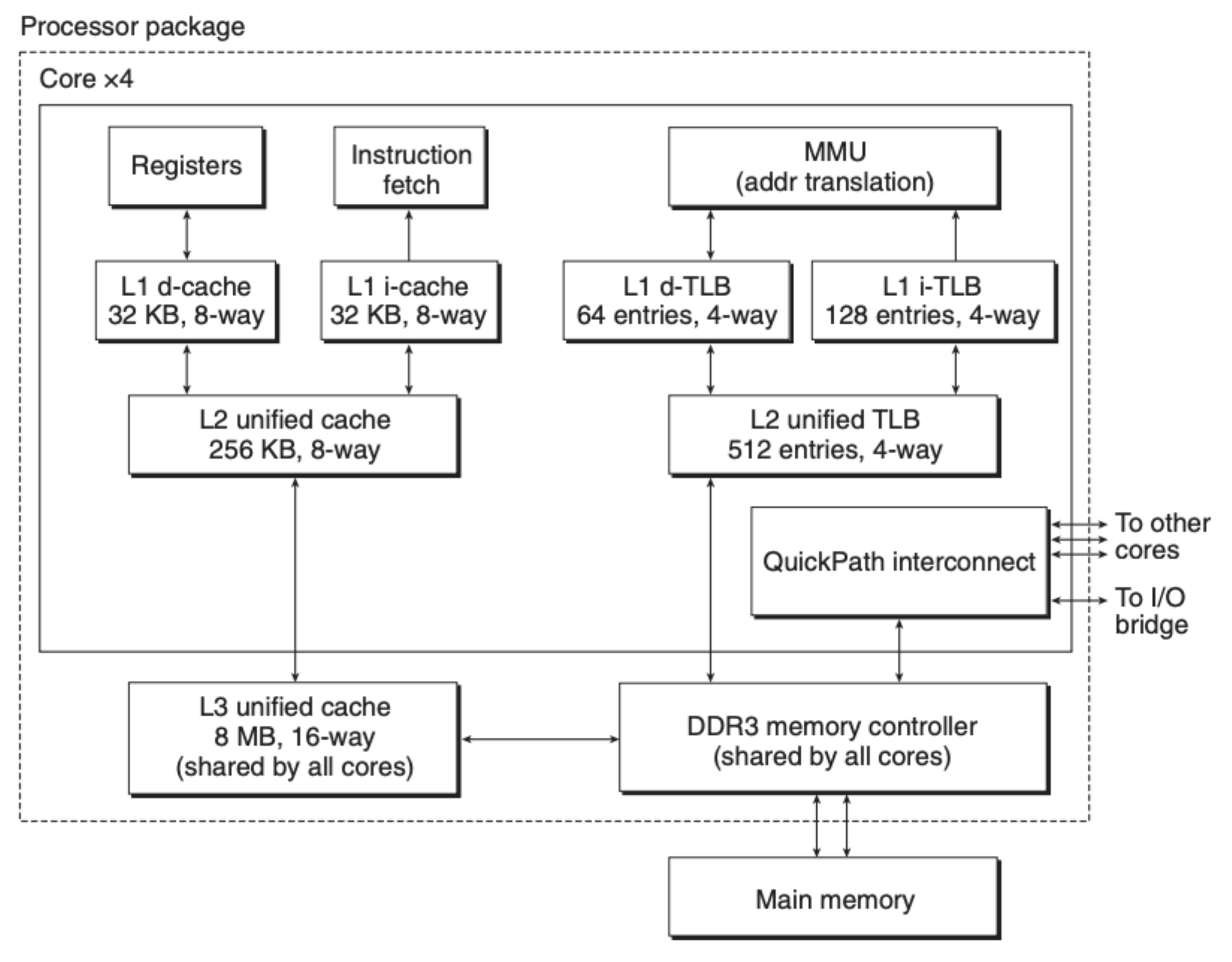
首先 i7 处理器有四个核,每个核内部都有着一样的架构,对于指令和数据这边,有两个直接的 L1 级高速缓存,一个负责缓存数据,另一个负责缓存指令,这之下是 L2 和 L3。另外一边是我们关注的 MMU 模块,下面也是同样带了两个L1 高速缓存,两个 L1 后面接的是 L2,这些高速缓存就是我们前面提到的 TLB。整个 CPU 模块又是通过内存控制器与 CPU 外的内存进行数据交换。
那地址转换又是如何进行的呢?下图可以很好说明问题:
![]()
CPU 模块中的 MMU 会将虚拟内存地址交由 TLB,如果 TLB 中缓存了对应的 PPN,我们就可以直接获取到物理地址,然后将物理地址发送到 L1 级高速缓存进行数据读取。如果 TLB 中未缓存对应的信息,我们就会去到页表中进行查找,i7 系统采用了四级页表,最终我们可以通过页表获得物理地址,剩下的步骤和前面一样。如果 L1 级高速缓存中有我们要的数据,将直接返回给 CPU,如果 L1 级高速缓存中没有我们要的数据,则请求又会发送到 L2,L3 以及内存,最后还有可能到硬盘,当然这是我们不希望频繁发生的。需要注意的是,计算机存储系统是一个层级结构,每一层只会和其上下两层进行交流,并且每一层只会接受上层的请求,(如有必要)向下层发送请求。逻辑也很直接,如果请求的数据存在就直接返回,如果不存在,将请求发给下层,并将下层传上来的结果进行缓存,然后再发回给上层,直到 CPU。
Linux 中的虚拟内存系统
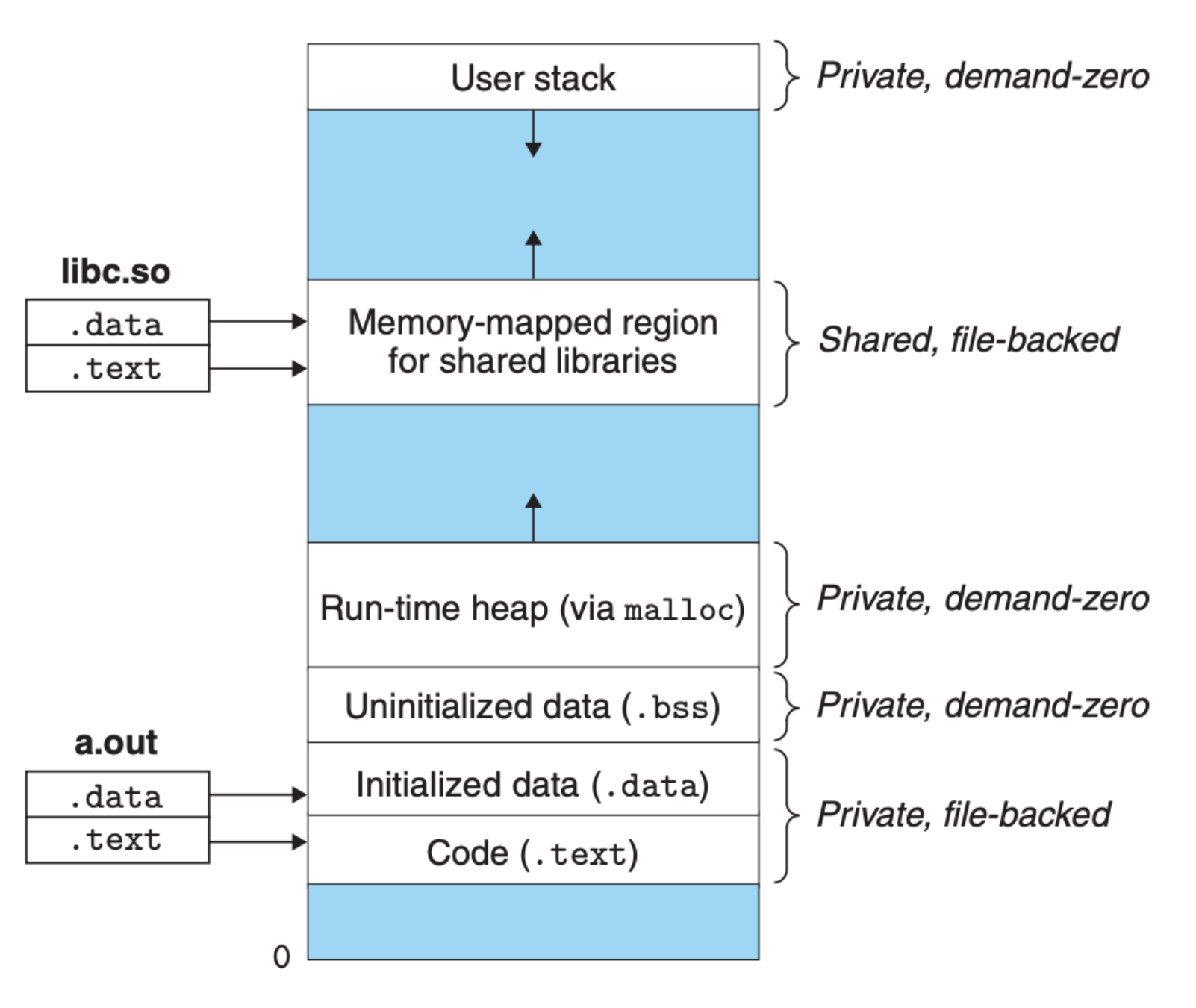
我们知道了虚拟内存是如何转化为物理内存的,可是在编程中我们常常接触到的都是类似 malloc 和 calloc 这样的内存分配函数,为了把这个与函数栈作区分,我们把它称之为堆内存,但是不管是堆还是栈,它们都是存放在内存以及上述我们提到的存储系统中的。有了虚拟内存,在软件层面我们就可以分区了,也就是说所有的进程都有着统一的区域划分,Linux 中进程的虚拟内存结构图大致如下图所示:
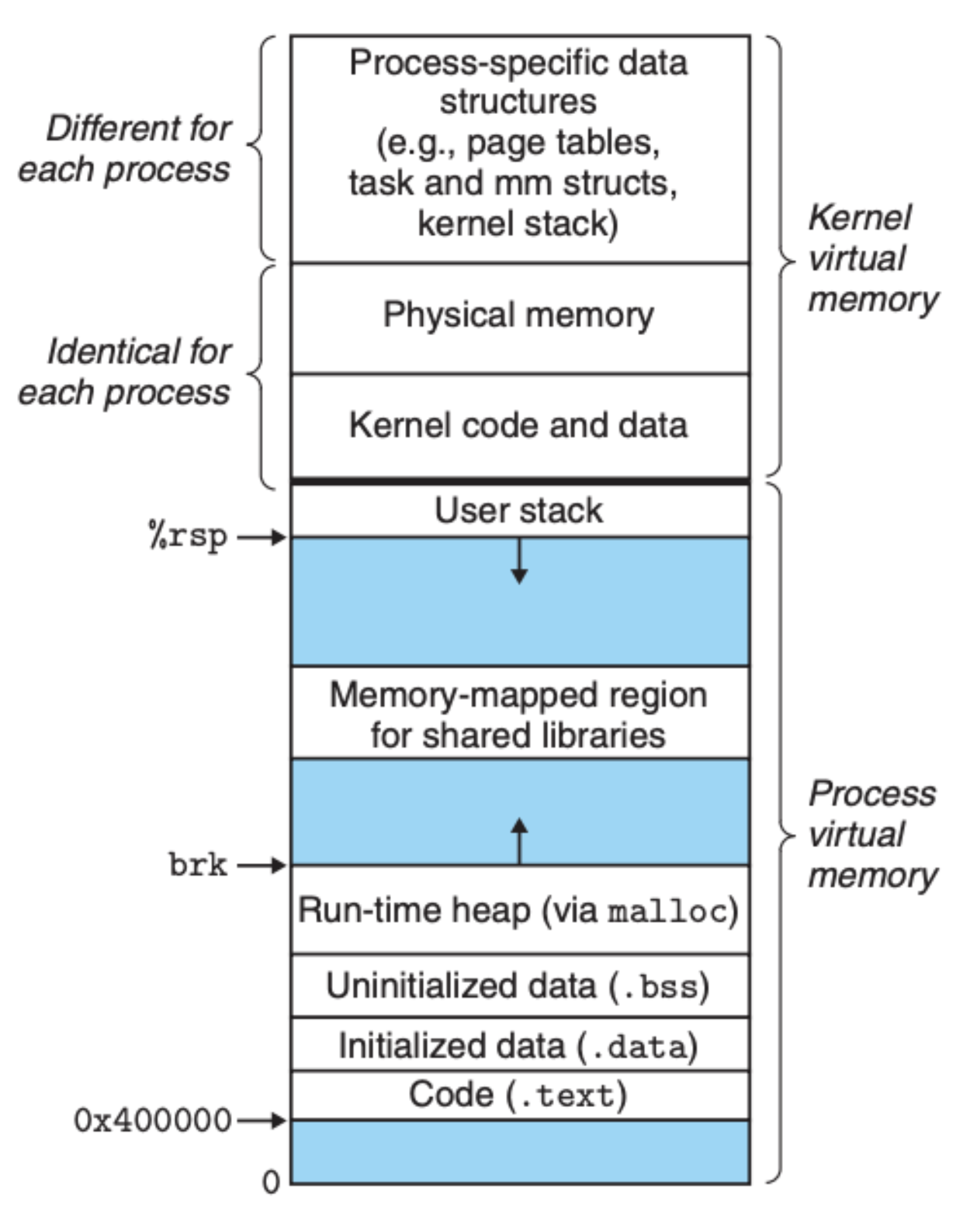
因为每个进程都有着相同的虚拟地址结构,每个进程只需要考虑并管理好自己的虚拟内存,不需要考虑其他进程,这样内存的管理和使用都变得简单了。另外,可以看到 Linux 中的用户栈和堆都是在进程运行时动态变化的,对于栈,我们已经在 CSAPP 第三章 介绍过,这里就不过多赘述。在实际开发中,很多时候我们不太需要去考虑函数栈,但堆内存的使用却是我们需要重点考虑的,因为这会直接影响到内存的使用效率,特别是使用类似 C 和 C++ 这样的编程语言,我们还需要手动释放内存。基于这些原因,我们就非常有必要知道在虚拟内存下,操作系统是如何管理和分配堆内存的。
虚拟内存结构
Linux 系统中的虚拟内存结构如下图所示:
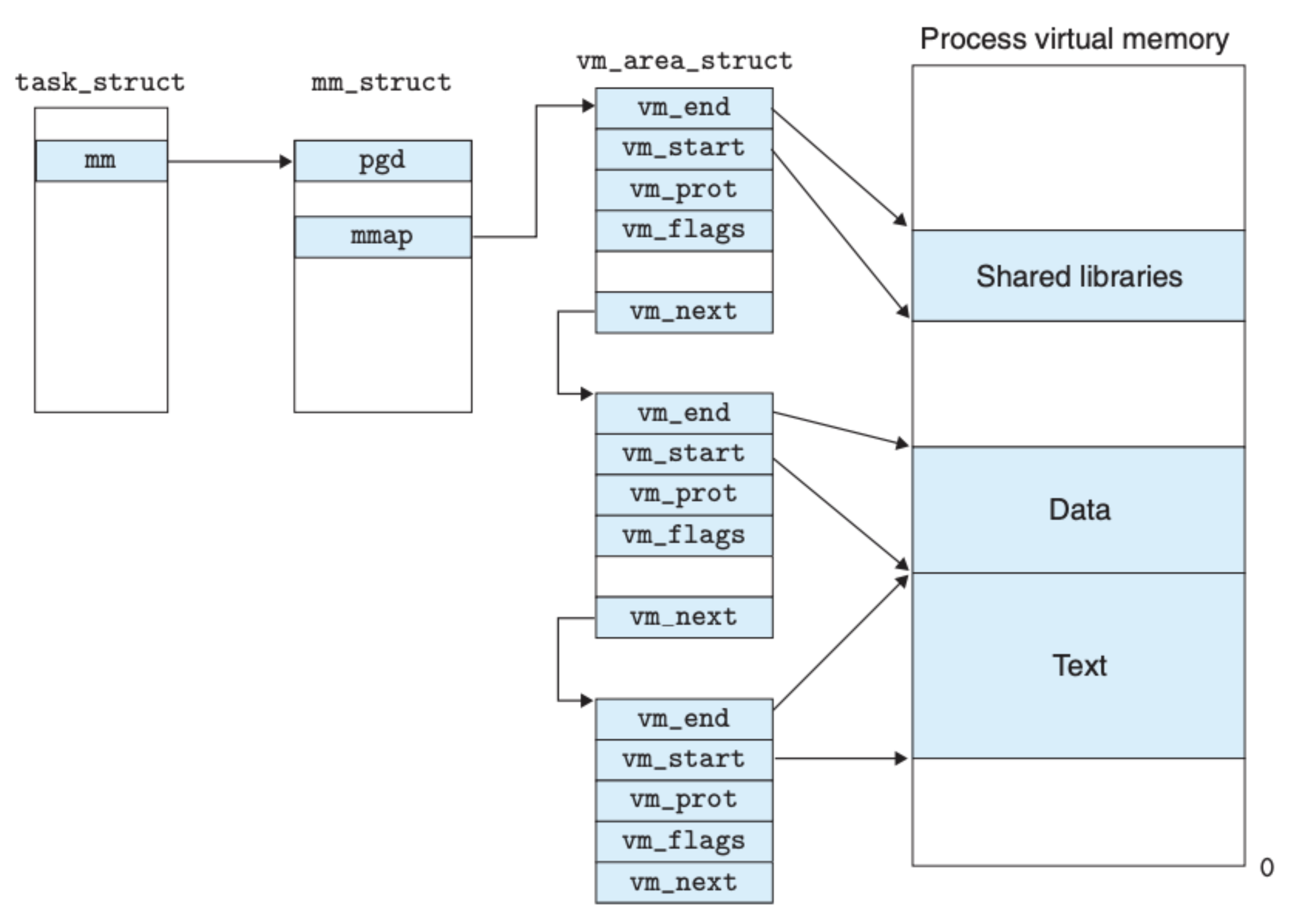
task_struct 中包含了操作系统内核运行程序所需要的所有信息,比如进程 ID,可执行对象文件、用户栈等等。pgd 指向的是一级页表,用于将虚拟内存地址转化为物理地址,这里的重点是 mmp 指向的 vm_area_struct 结构,Linux 系统用区域(area)来管理虚拟内存,一个区域可以被理解成是被分配后的连续的虚拟内存页,并且这些页相互之间存在关联,在这样的结构下,每个区域之间也是可以有间隙的,vm_area_struct 中存放的信息如下:
vm_start:指向区域的开始地址vm_end:指向区域的结束地址vm_prot:标明区域中页的读写权限vm_flags:标明区域中页是某个进程私有的还是共享的vm_next:指向下一个区域
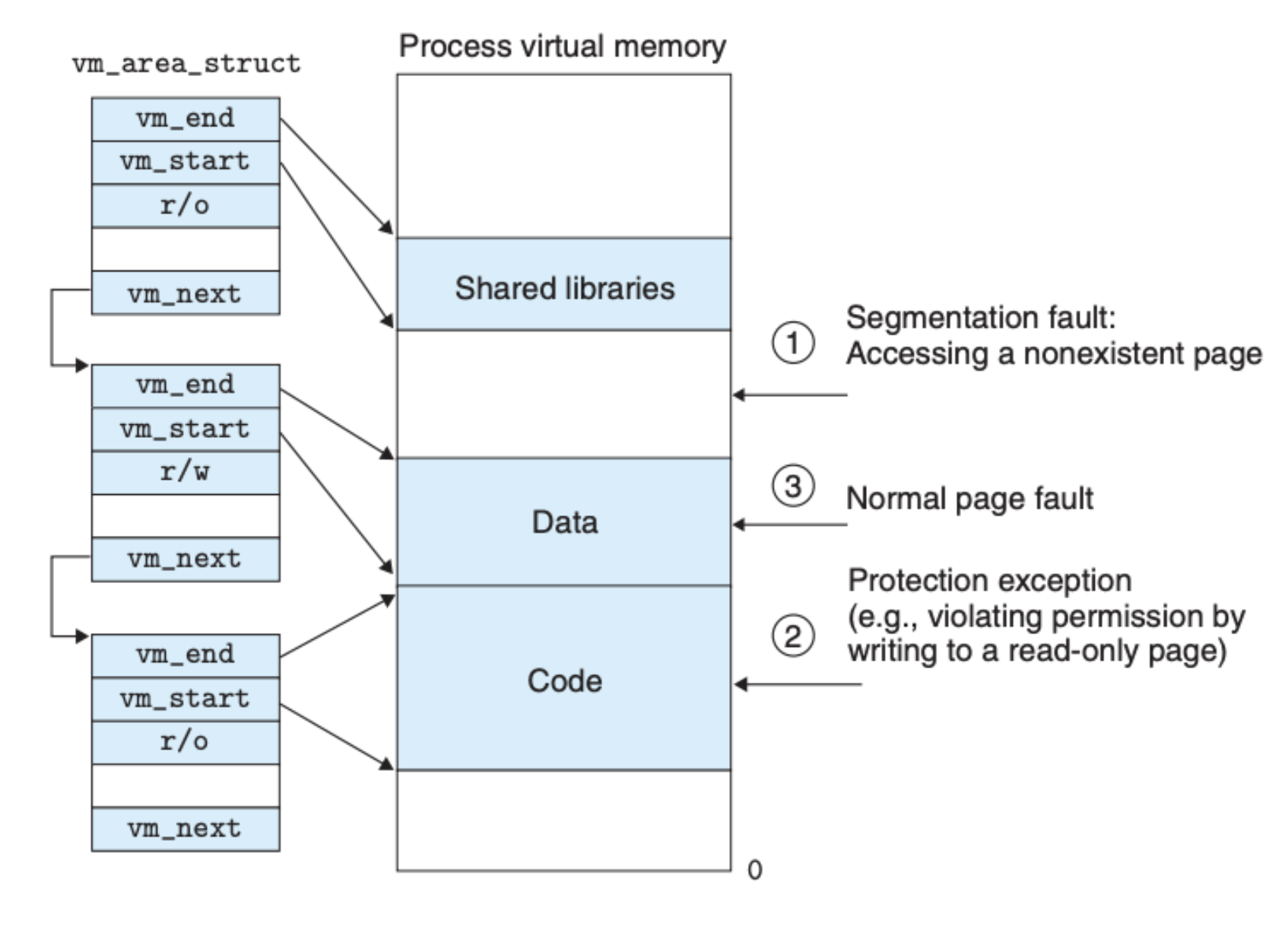
我们前面提到的页缺失(Page Fault)的处理也是基于这个结构,页缺失异常的处理大致如下:
- 处理函数会遍历所有的区域结构,将虚拟内存地址和所有区域的
vm_start和vm_end比较,由此可以得出输入的地址是否有效,如果无效,直接触发 segmentation fault 错误,程序将被强制退出执行,如果有效,就会去到下一步 - 在上面的遍历中,处理程序还会检查有关访问页的权限问题,如果权限不符,将会触发 protection exception 错误,程序也会被强制退出
- 到了这里,操作系统内核就确认虚拟内存地址有效,将会发送指令到内存,让内存去硬盘读取数据
下图可以很好地说明页缺失处理中的错误:
内存映射
我们知道内存只是计算机运行时缓存数据的地方,数据总归是要持久化保存在硬盘或磁盘中的,内存映射就是为了将虚拟内存和硬盘中持久化的数据关联起来。在之前的 链接 中我们提到了目标文件,其实文件是 Linux 系统中对数据进行封装的一个概念,因而内存映射其实就是将虚拟内存和对应的文件进行映射,也就是我们前面说到的区域(area)会和文件进行映射。
一旦一个虚拟页面被初始化了,它就在一个由内核维护的专门的交换文件(swap file)之间换来换去,交换空间限制着当前运行着的进程能够分配的虚拟页面的总数。
除此之外,一个被映射到虚拟内存区域的文件可以是共享的,也可以是进程私有的。比如下面这张图反映的就是共享文件的映射:
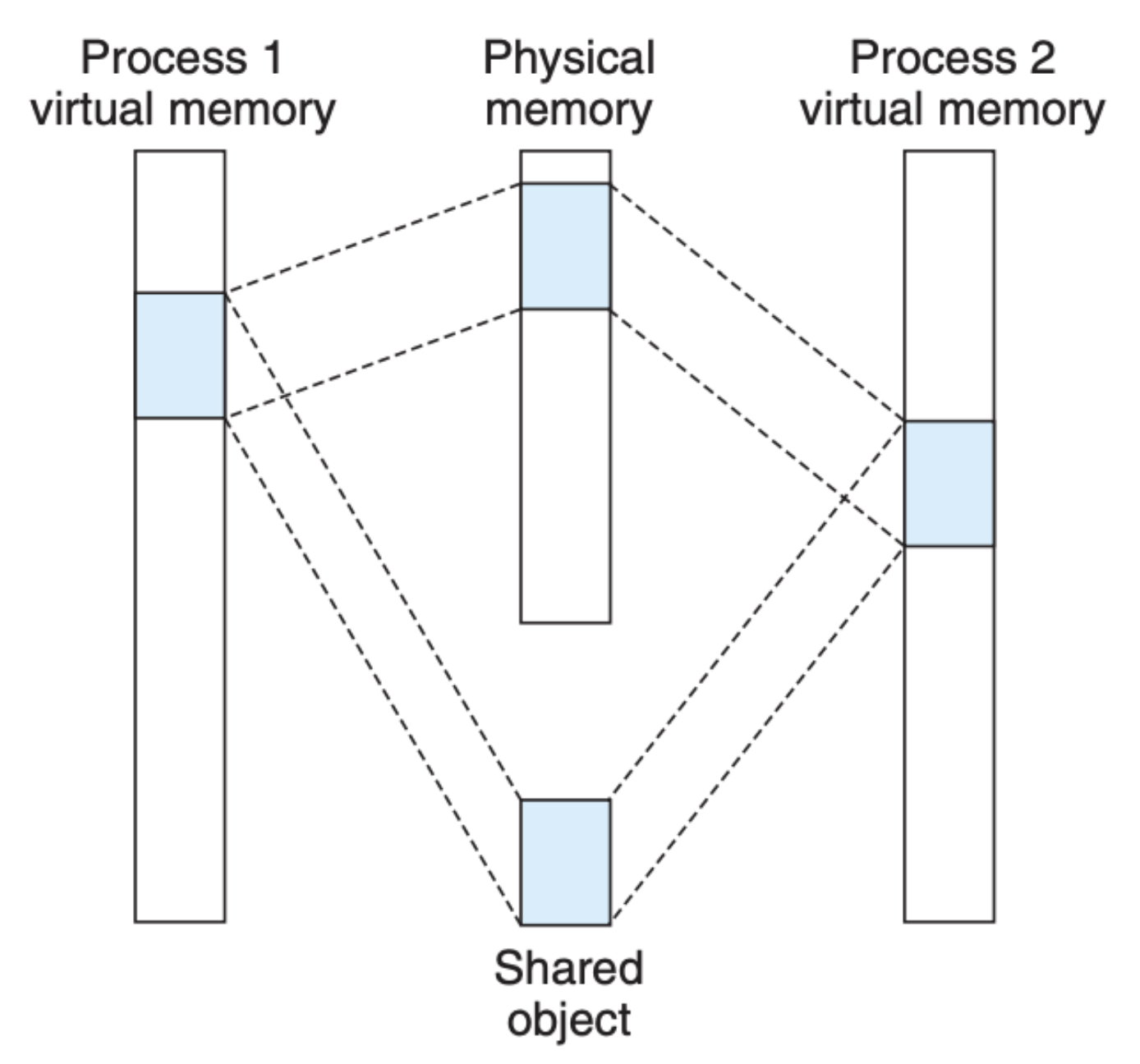
因为是共享的,任意一个共享进程都可以直接更改内存,硬盘上的文件内容也会被随之更改,更改的信息会被其他共享成员(进程)看到,这个很容易理解。但是麻烦的是私有文件,我们知道很多文件会被频繁引用,比如说动态库,要做到私有,意味着每个进程都需要独立的一份文件,这样每个进程修改文件均不会影响到其他进程关联的文件,可问题是这会造成资源的极大浪费。
为了解决这个问题,Linux 采取了 写时拷贝(copy-on-write) 的办法,也就是私有映射和共享映射在刚开始的时候都是一样的,所有进程也都是映射到一个文件(内存区域)上:
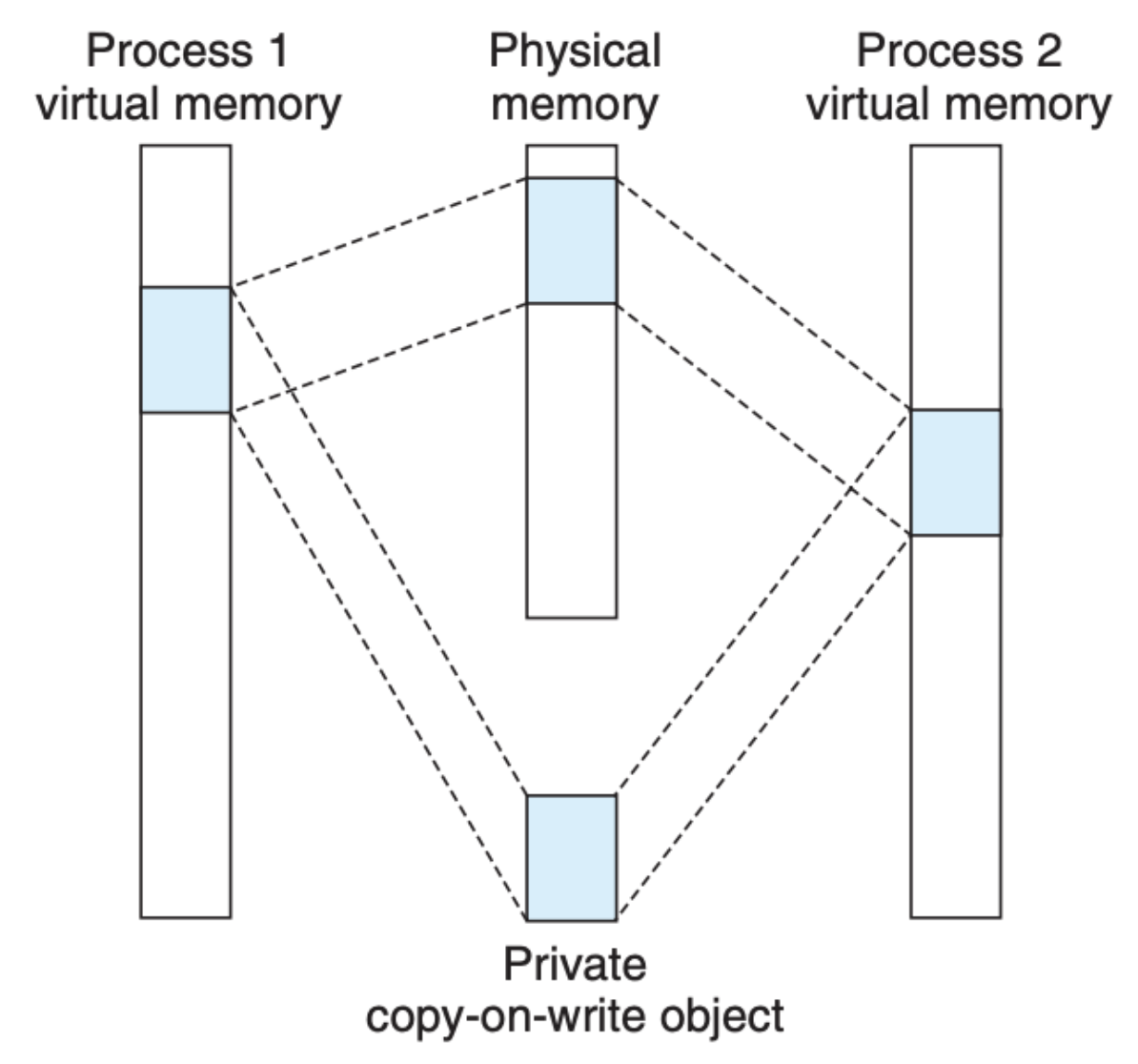
但是当某个进程尝试着更改文件,拷贝就会发生,拷贝仅仅是针对这个进程,其他进程不受影响,并且只有更改的部分会被拷贝:
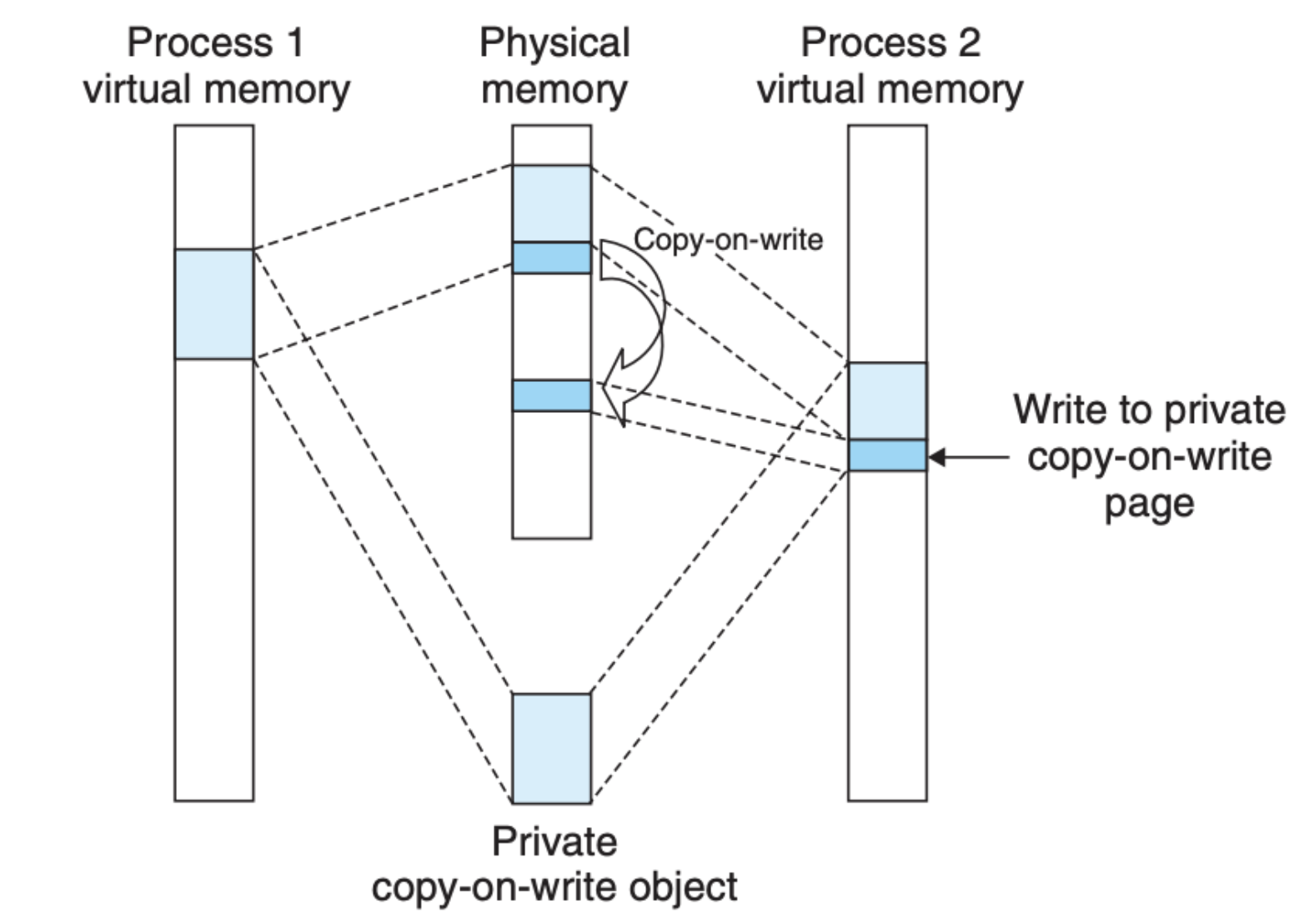
在这种机制下,有限的内存资源得到了更高效的利用。
fork 函数
在前面的 文章 中我们重点介绍了 fork 函数,用于 Linux 系统中的进程创建。我们提到过,新创建的子进程的数据全部是从父进程拷贝过来的,具体来说,父进程的 mm_struct、vm_area_struct 和页表都会被子进程 “拷贝”,页表中的页会被标记为只读,区域也会被标记为私有,如有更改会采取前面提到的 写时拷贝(copy-on-write) 的策略。
execve 函数
execve 函数也是之前 文章 介绍过的,主要负责加载和运行程序。在虚拟内存系统下,execve 的执行有下面几个和虚拟内存相关的步骤:
- 删除当前进程中的区域数据结构(
vm_area_struct) - 为将要执行的进程创建私有区域
- 为将要执行的进程映射共享区域
- 重新设定程序指针(Program Counter,PC),将程序的执行转接到需要执行的程序中
具体的虚拟内存结构如下:
内存映射函数
用户可以通过调用 mmap 来手动将虚拟内存区域映射到目标文件:
1
2
3
4
5
#include <unistd.h>
#include <sys/mman.h>
// Returns: pointer to mapped area if OK, MAP_FAILED (−1) on error
void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
函数的输入参数有点多,下图可以很好地概括:
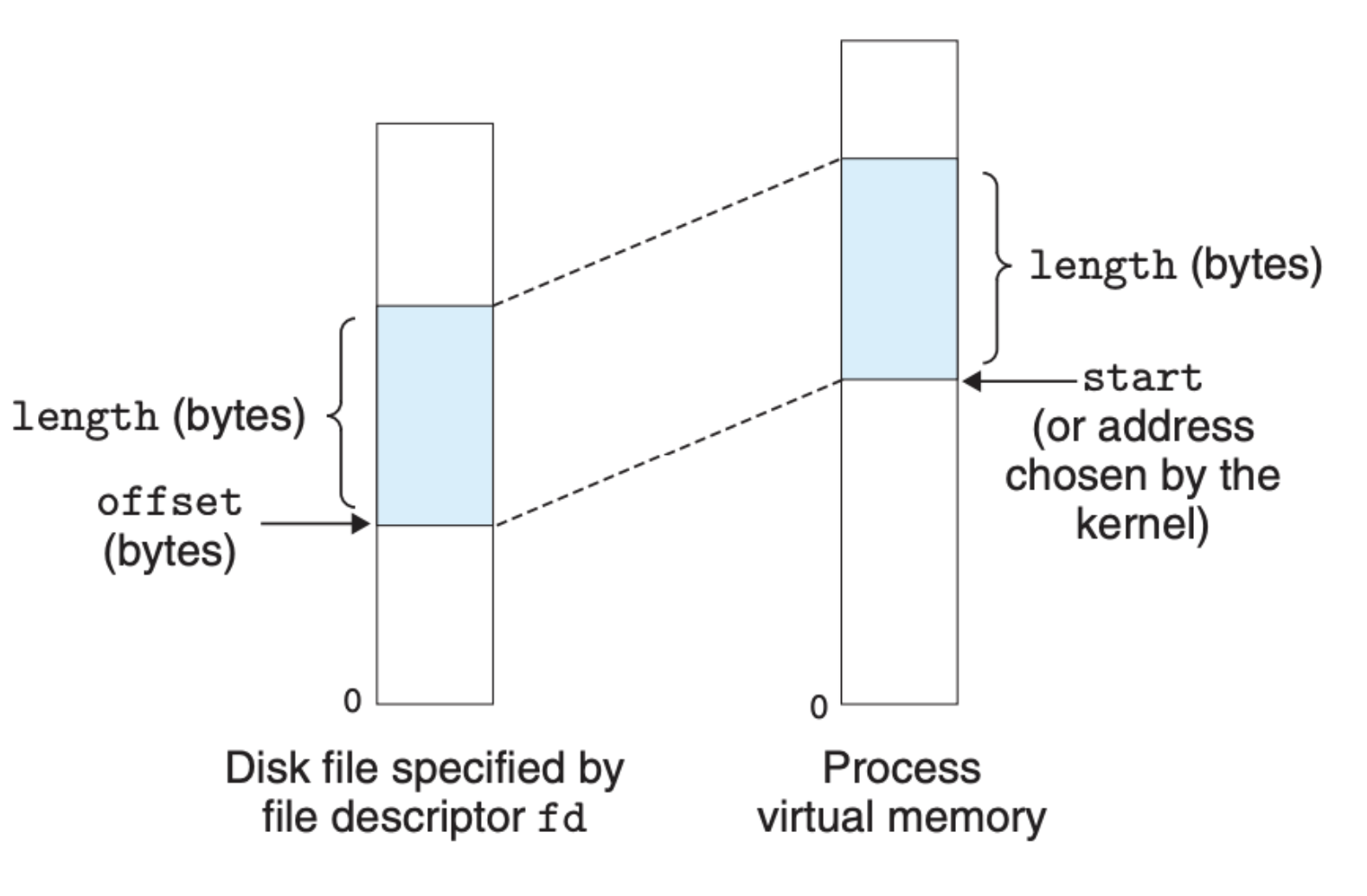
mmap 函数会让操作系统内核创建一个新的虚拟内存区域,并将该区域映射到 fd 标识的目标文件中的一段连续空间上。上面的 prot 参数表示的是访问权限,对应于虚拟内存结构中的 vm_prot。
另外,如果创建的虚拟内存不再被使用,我们也可以使用 munmap 来对其删除:
1
2
3
4
5
#include <unistd.h>
#include <sys/mman.h>
// Returns: 0 if OK, −1 on error
int munmap(void *start, size_t length);
动态内存分配
mmap 比较复杂,需要传入大量的参数,并且我们还需要考虑如何分配虚拟内存,这对用户并不友好,我们需要另外一种动态分配内存的机制,这个机制管理的虚拟内存常常被称之为 堆内存:
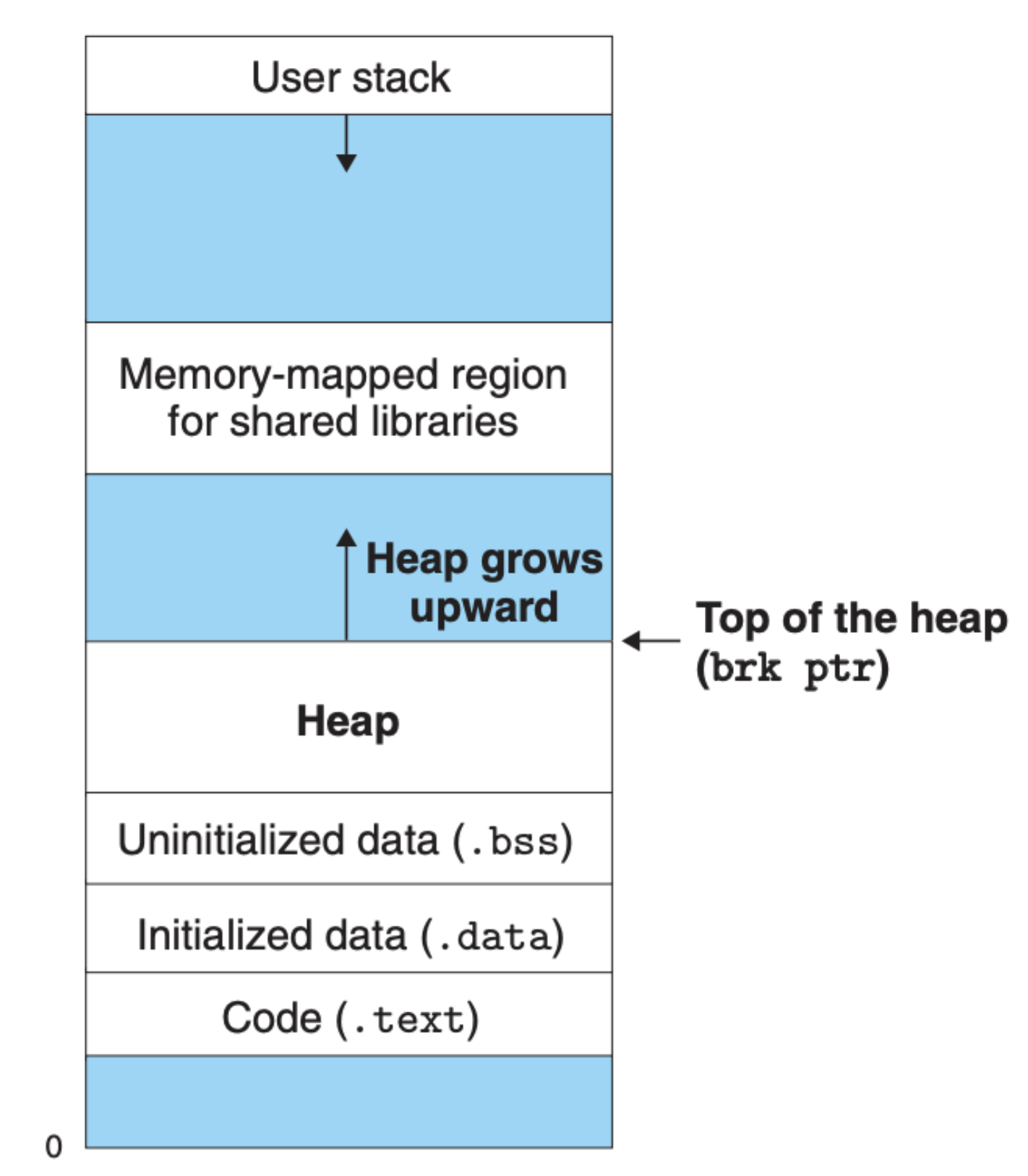
可以看到堆内存的大小是动态的,可增可减,另外对于堆内存主要存在以下两种分配机制:
- 显性分配:用户程序需要帮忙维护堆内存,比如说在 C 语言中,C 程序需要使用
free函数释放分配了但是不会再使用的堆内存 - 隐性分配:分配器会帮忙查看分配了但是不会被再次使用的堆内存,对其进行释放,这种分配器常常被称为 垃圾回收器(garbage collectors)
在 C 语言中,malloc 和 free 用于堆内存的分配和回收:
1
2
3
4
5
6
7
#include <stdlib.h>
// Returns: pointer to allocated block if OK, NULL on error
void *malloc(size_t size);
// Returns: nothing
void free(void *ptr);
在 32 位系统中,malloc 返回的虚拟内存地址永远是 8 的倍数,64 位系统中,永远是 16 的倍数,原因是 malloc 分配的内存块需要为可能包含在这个块内的任何数据对象类型做对齐,因为这个设定的存在,很多时候会存在碎片,比如下面这个例子:
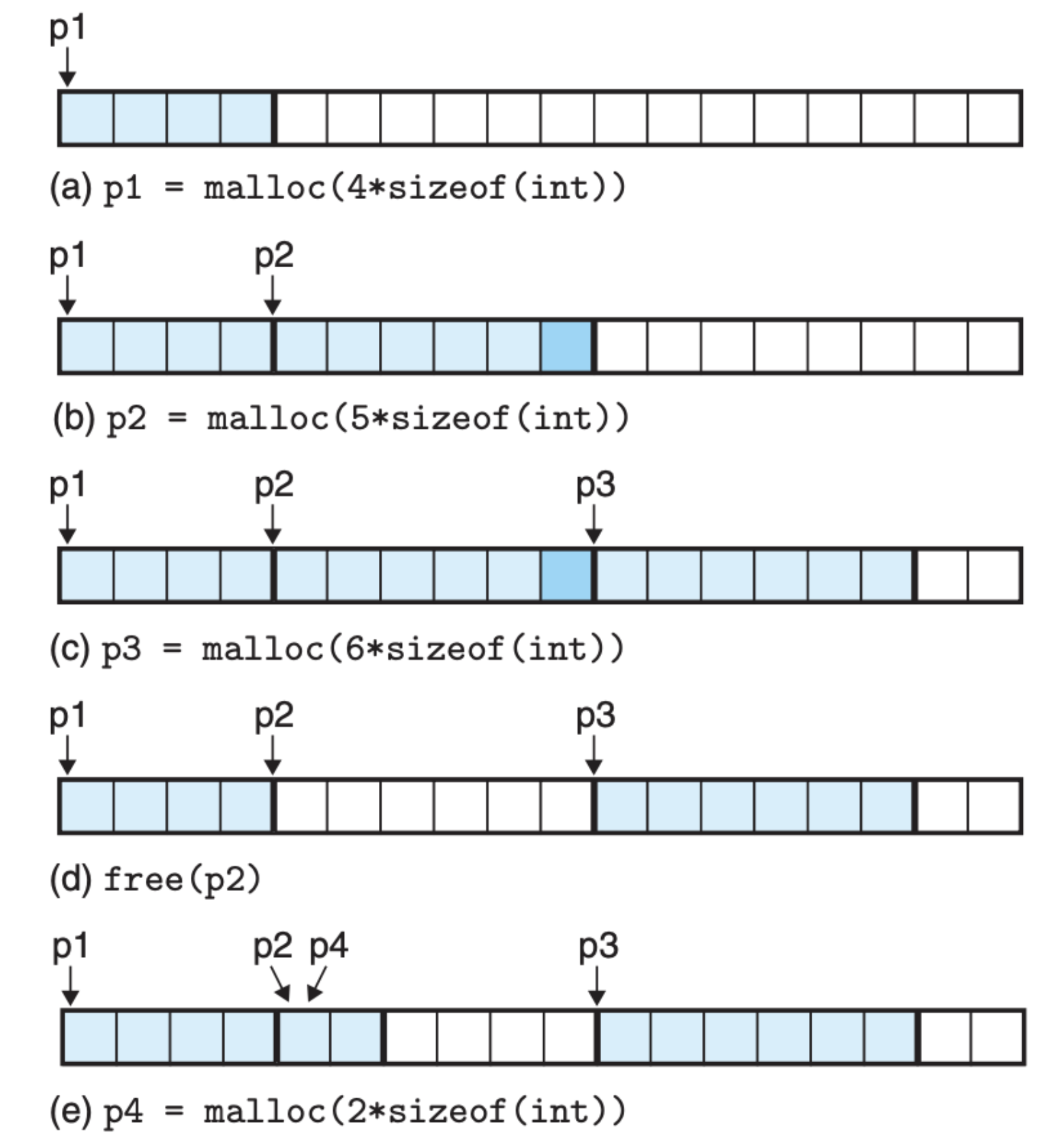
p2 指向的内存块仅仅使用了 5 * 8 = 40 字节的虚拟内存空间,但是为了对齐多分配了 8 字节的空间,这 8 字节的空间是被浪费掉的。另外,从这个图中我们也可以看到,p2 被释放后依然指向着被释放的空间,这部分空间会被 malloc 重新利用。
堆内存分配器
堆内存分配器一直是编程语言设计的核心,甚至它在一定程度上决定了一门编程语言的效率和友好程度,我们都知道 Java 的垃圾回收是让其区别于 C 和 C++ 的重要机制,因为有着自动回收机制(隐性分配器),Java 语言相比于 C 和 C++来说要友好许多。那如何设计一个堆内存分配器呢?我们先来看看类似于 C 和 C++ 这种显性分配器,总的来说有下面几点要求:
- 堆内存能够处理任何请求,包括无效的输入、边界和错误的情况等等
- 必须能立即响应
- 仅仅使用堆区虚拟内存
- 遵守对齐机制
- 不会无缘无故修改已分配的内存
注意,上面说的这些是底线和原则,即使一个分配器满足了上面这些要求,也只能说该分配器可以正常运作,但是并代表该分配器的性能。分配器的性能主要从时间和空间来衡量:
- 时间上,我们希望分配器执行分配和释放操作的时间越短越好,这样分配器效率更高
- 空间上,我们希望分配器在完成一系列分配和释放操作,用到的虚拟内存越少越好
当然了,很多时候我们都是在二者之上做权衡。分配器绕不开的一个问题就是碎片化,比如上面的那个例子,不过这种碎片化仅仅是为了内存对齐导致的,不会太严重。另外一种碎片化是基于输入输出的,比如说刚开始的时候程序分配了 100 块的内存,每块大小为 16 字节,总共就消耗了 1600 字节的连续空间,这之中的某些使用完后就被释放了,假如说其中的 640 字节的空间被释放掉了,这个时候需要分配 320 字节的 连续 空间,按理说被释放的空间就完全足够了,不需要再继续扩充堆内存,但是问题是这释放的 640 字节是不连续的,是碎片化的,大概率还是不满足条件,所以分配器只好继续扩充堆内存。可以看到这种情况会造成堆内存的巨大浪费,我们需要在设计之初的时候就考虑进去。
对分配器进行优化,下面这些问题都是设计分配器的核心问题:
- 如何跟踪被释放的内存?
- 在分配内存时,如何选择一个被释放的内存区块?
- 当一个被释放的区块被用来分配内存后,如何处理剩下的区块空间?
- 我们应该如何处理释放后的区块?
隐式空闲链表
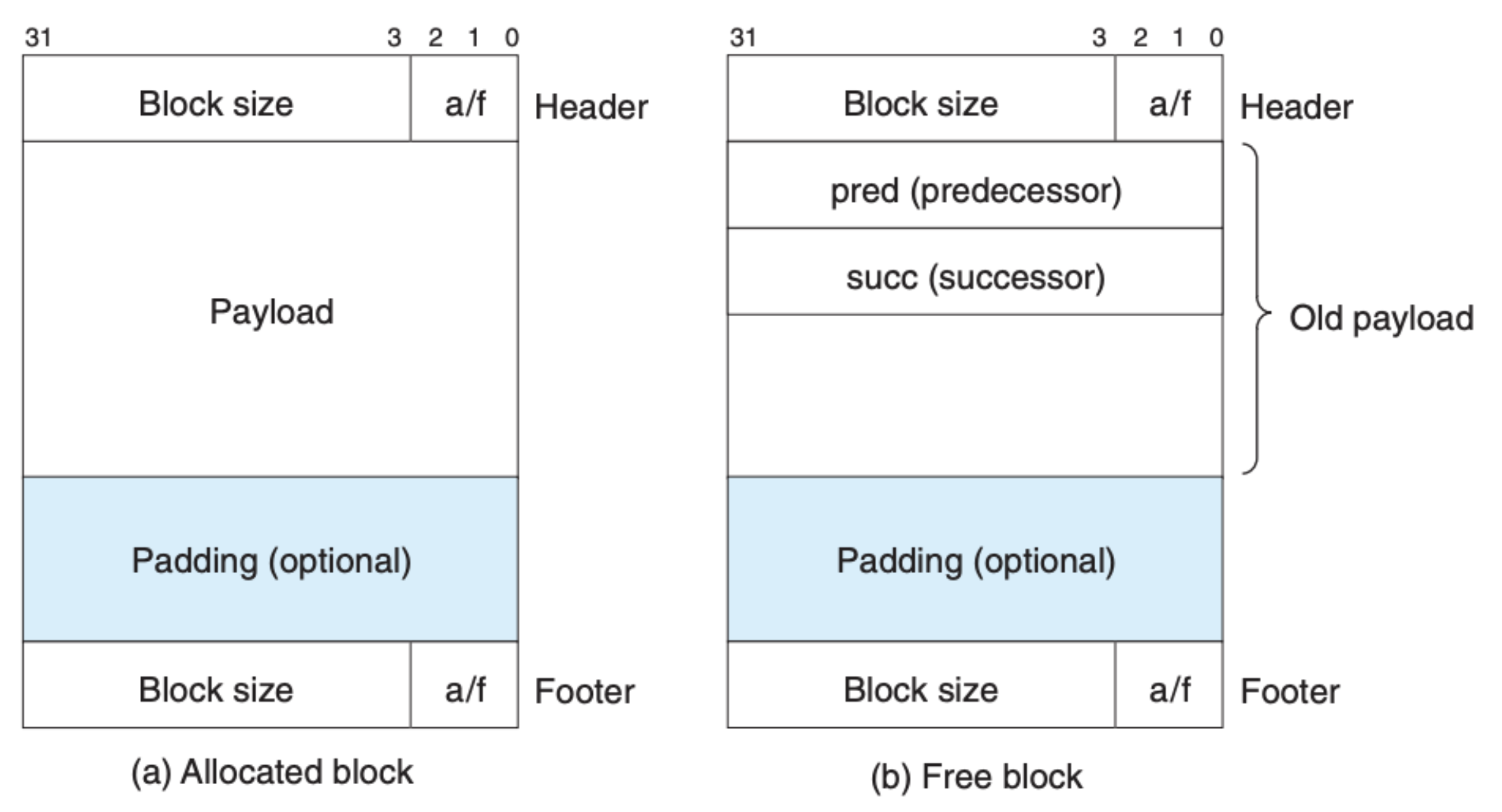
我们应该如何标记一块堆内存呢?一种简单的方式就是使用 隐式空闲链表(Implicit Free Lists),区块的结构大致如下:
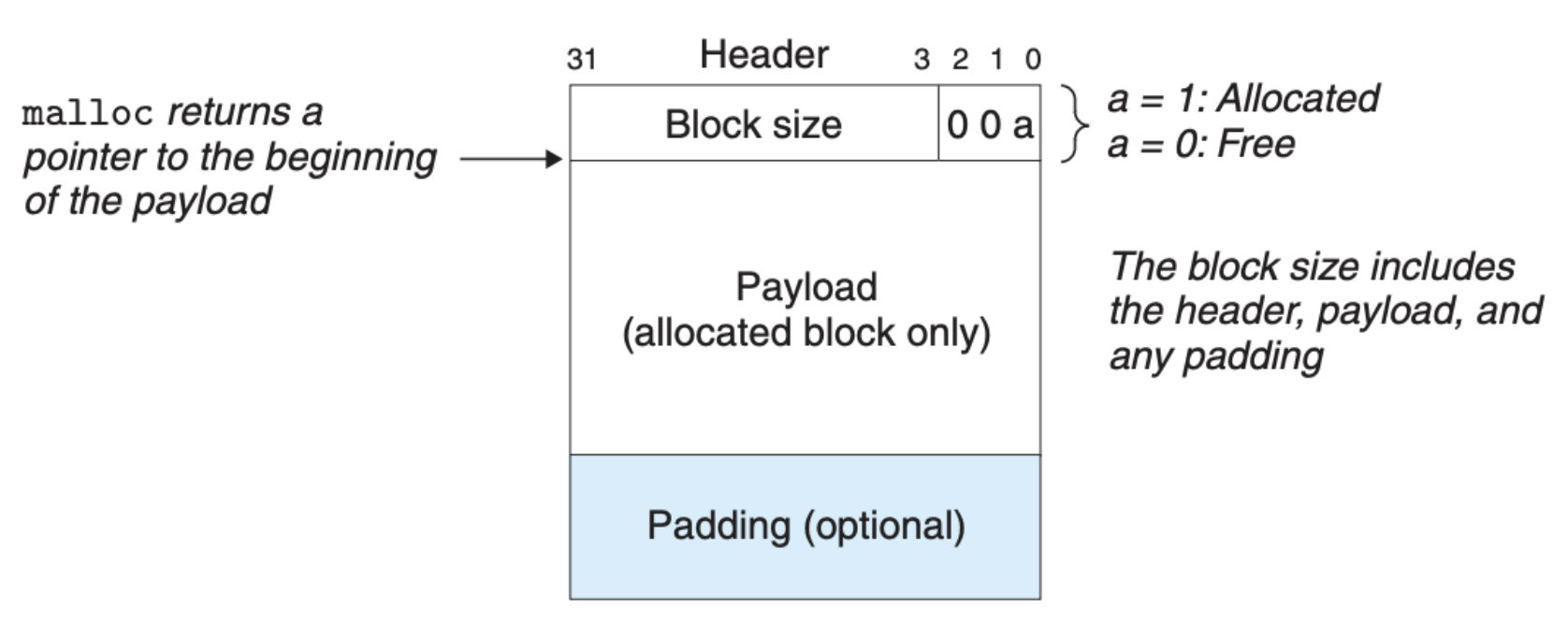
该区块用了四个字节来存储区块的基本信息,比如区块大小、以及该区块是否被分配。图中的 Padding 表示的是对齐区域。下图就是一个基于隐式空闲链表的例子:

每个区域与另外一个区域的头相连,这个结构比较直观,但是缺点是区块只包含自身的信息,我们往往需要花费线性的时间进行遍历以找到符合条件的区块。基于这个结构,我们来讨论下内存分配时的一些策略。
首先是如何确定要分配的区域,最简单的方式是 first fit,就是从头遍历直到找到了符合条件的区域。除此之外,我们也可以使用 best fit,把所有区块都遍历一遍,然后选择最优的(符合条件的最小区块),还有一种方式是从上次分配的区域开始继续向后寻找,这就是 next fit。
当我们定位到了符合条件的区域,这里还有一个优化——分割区域,也就是说如果分配并不会占用区域中的所有空间,那么我们可以把这部分剩余的空间分割出来形成一个新的区域,这样可以使空间利用率最大化。
另外,当我们释放内存时可能出现两个连续的区块连在一起,比如下图这样:

这里我们可以考虑把两个大小为 16 的区块合并,下次分配时这部分区域的利用率更高,这样可以减少碎片化。合并也有着一些细节,一般来说有下面两种合并:
- 立即合并,也就是当释放区块的时候,如果相邻区块没有分配出去,那么就直接合并
- 延迟合并,在释放区块的时候不考虑合并,而是等到以后分配时再考虑合并,比如说如果分配失败,那么再检查是否有需要合并的区块
这两种方式都有着各自的优缺点,立即合并简单粗暴并且每次合并都能在常数级时间完成,但是有些时候立即合并会造成区块的反复合并与分割,这也会对性能造成影响。往往高效的分配器都会将上述两种方式结合起来应用,而不是单单只使用一种方式。
由于隐式空闲链表中的区块都是相互独立的,虽然我们可以根据当前区块的大小定位到下一个区块,但是我们定位到前一个区块,这就给合并造成了困难。为了合并,我们必须每次都从头到尾对区块进行遍历,这对分配器的性能造成了影响。为此,我们可以在每个区块中加上脚标,如下图所示:
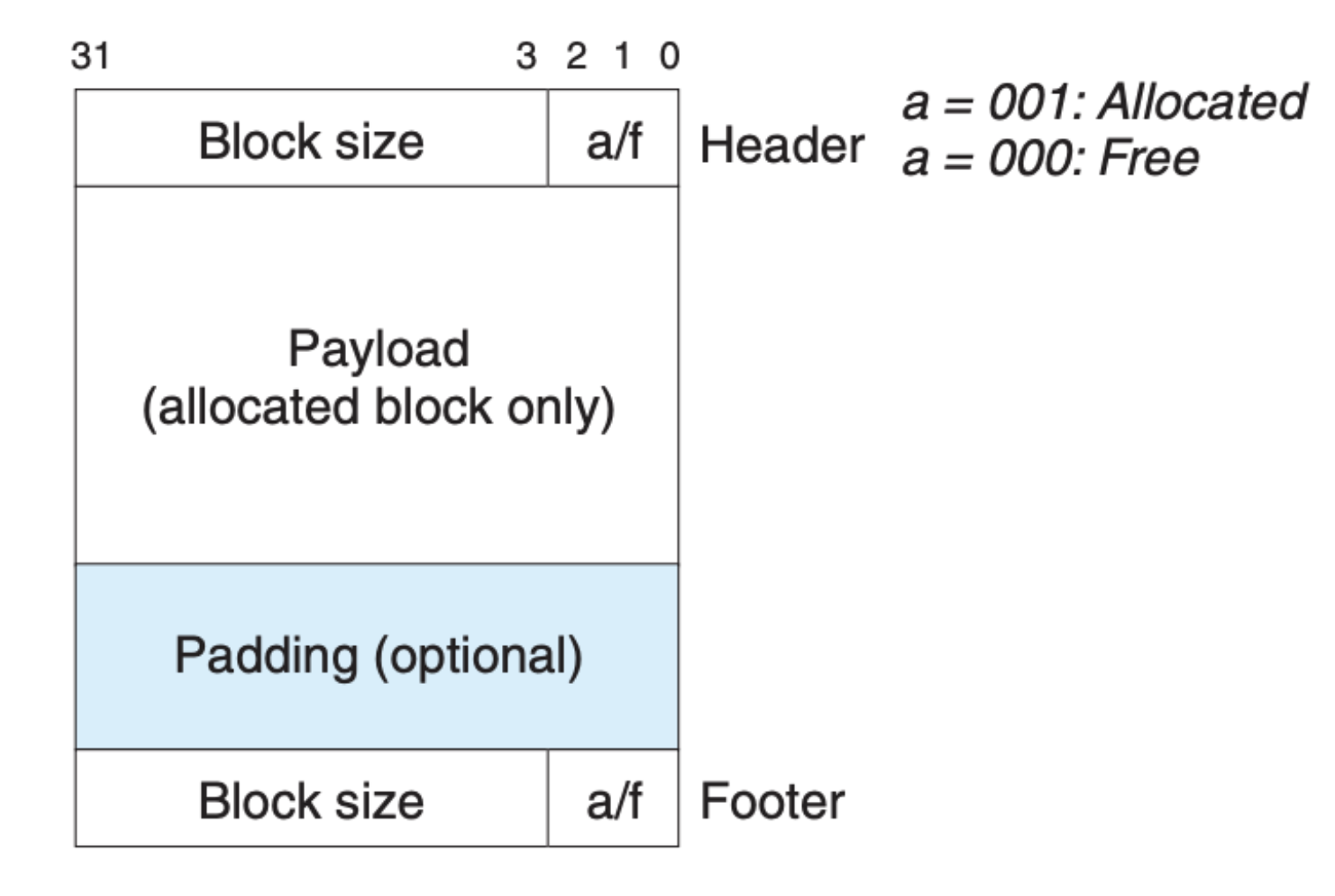
这样当前区块就可以根据前一个区块的脚标来获知这个区块是否被分配以及区块的大小,合并就会变得容易许多,当然因为脚标也和区块头一样,占据了一定的空间,当应用中有很多小的区块时,这会有许多虚拟内存空间的浪费。我们可以考虑做个简单的优化,因为如果前一个区块已经分配了我们就不需要考虑合并,也就不需要知道区块大小,换句话说已经分配了的区块不需要脚标,只有未被分配的区块需要脚标,这里我们需要在每个区块的头中用一个比特位来标识上一个区块是否被分配,这样我们就可以节省很大一部分空间。
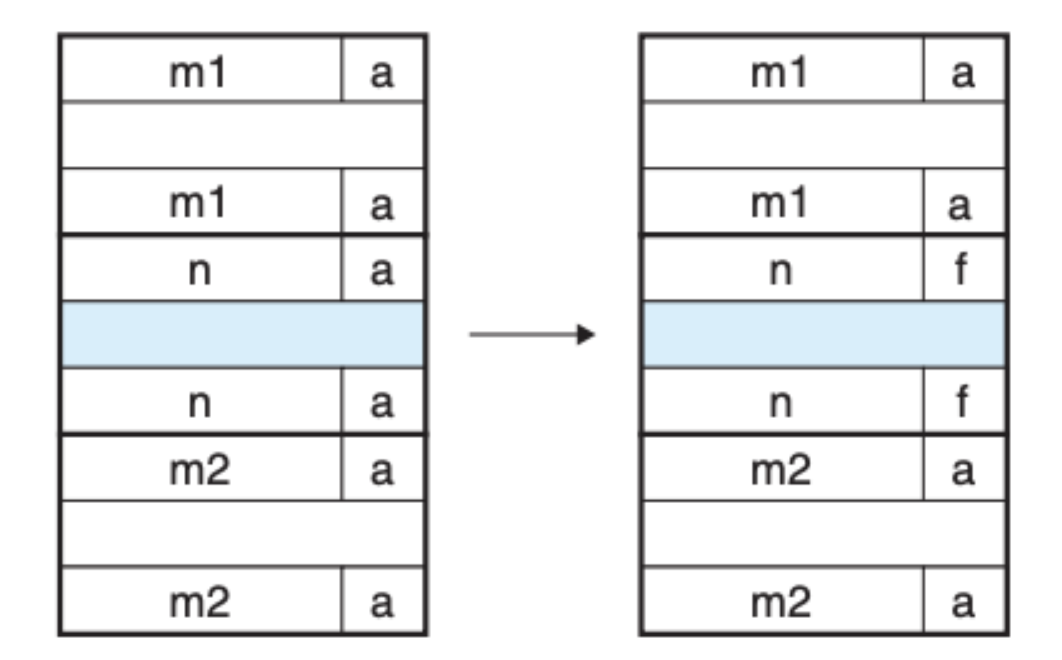
合并无非就下面四种情况,首先是前一个区块和后一个区块都是分配出去的,这里我们不需要做任何操作,直接释放并重新标记当前区块即可:
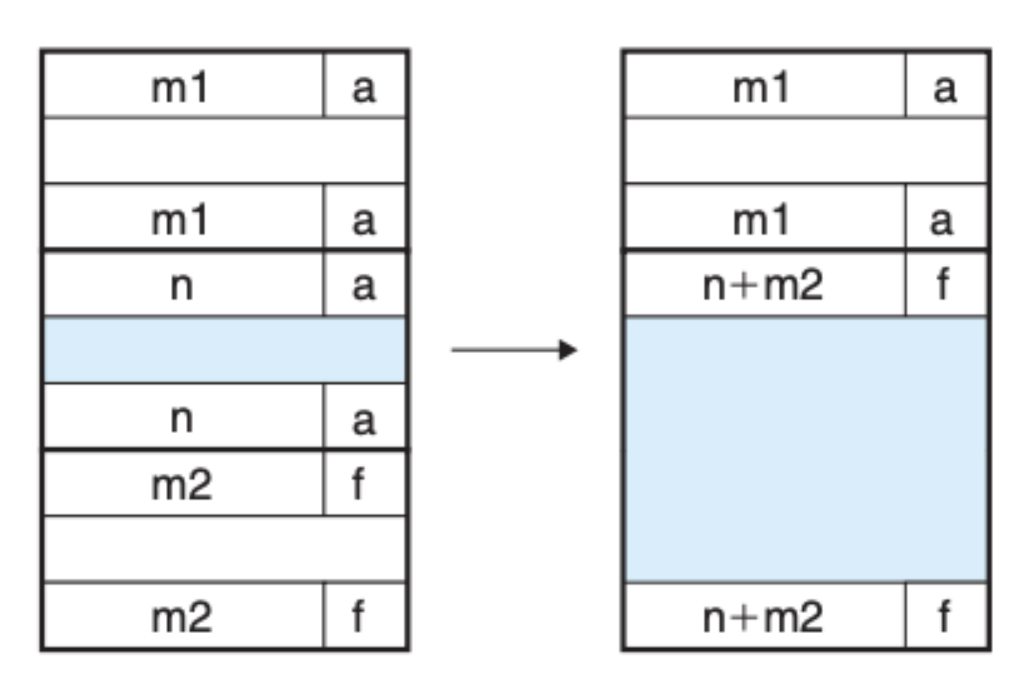
第二种情况,后一个区块是空闲的,前一个区块是分配的,这样就将后两个区块合并起来:
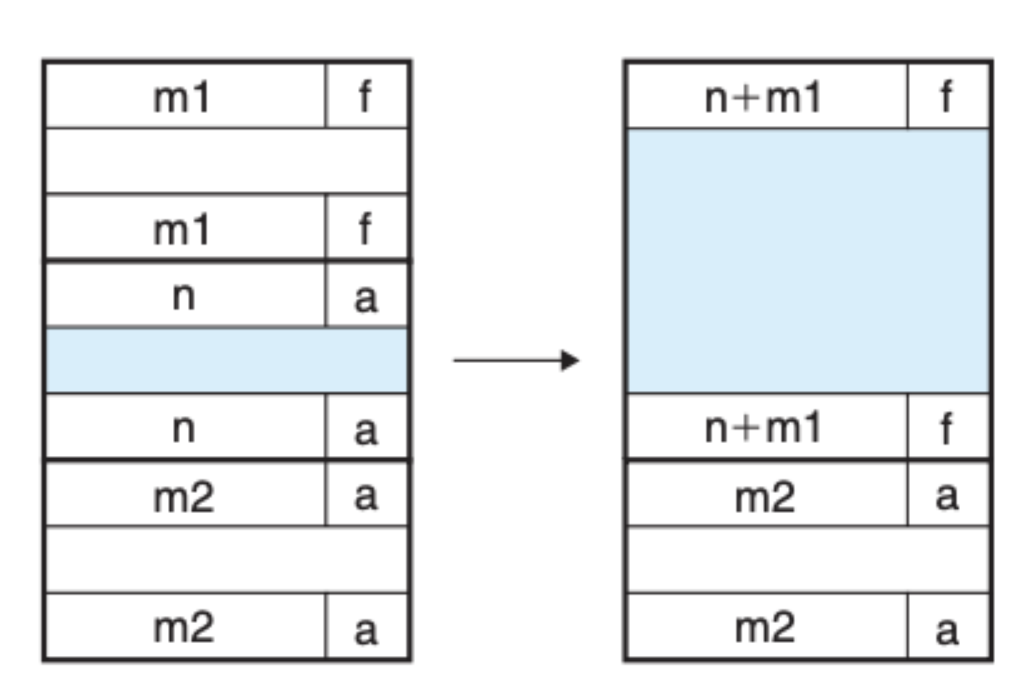
第三种情况,前一个区块是空闲的,后一个区块是分配的,这样就将前两个区块合并起来:
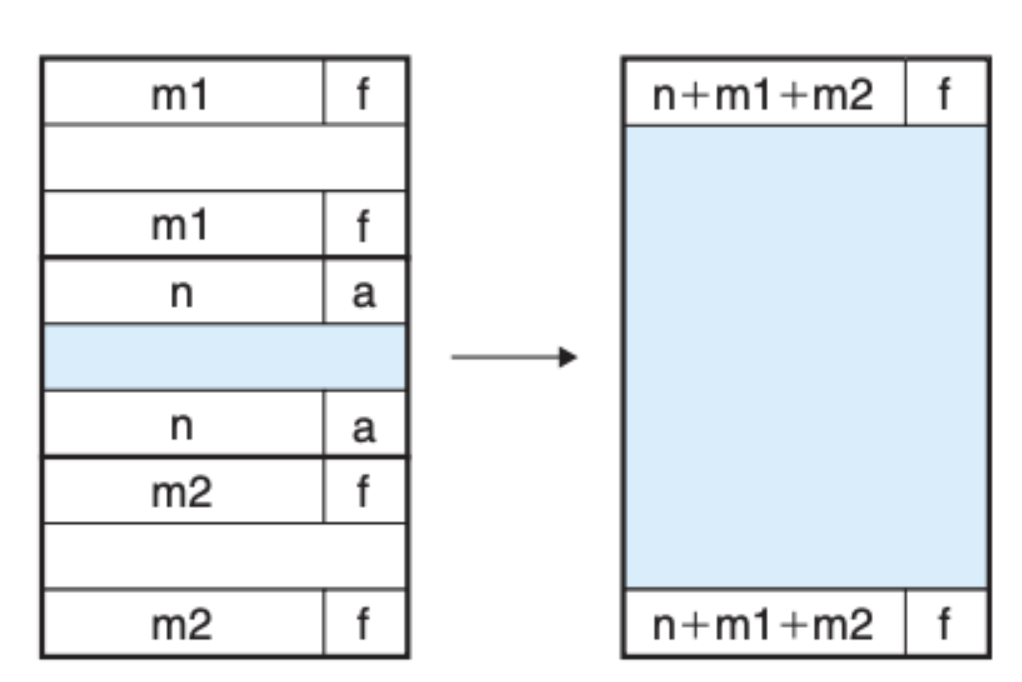
第四种情况,前后两个区块都是空闲的,直接将这三个区块都合并起来:
基于上面讨论的这些,我们可以实现一个简单的分配器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
/* Basic constants and macros */
#define WSIZE 4 /* Word and header/footer size (bytes) */
#define DSIZE 8 /* Double word size (bytes) */
#define CHUNKSIZE (1<<12) /* Extend heap by this amount (bytes) */
#define MAX(x, y) ((x) > (y)? (x) : (y))
/* Pack a size and allocated bit into a word */
#define PACK(size, alloc) ((size) | (alloc))
/* Read and write a word at address p */
#define GET(p) (*(unsigned int *)(p))
#define PUT(p, val) (*(unsigned int *)(p) = (val))
/* Read the size and allocated fields from address p */
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLOC(p) (GET(p) & 0x1)
/* Given block ptr bp, compute address of its header and footer */
#define HDRP(bp) ((char *)(bp) - WSIZE)
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
/* Given block ptr bp, compute address of next and previous blocks */
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp) - WSIZE)))
#define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp) - DSIZE)))
/* Private global variables */
static char *mem_heap; /* Points to first byte of heap */
static char *mem_brk; /* Points to last byte of heap plus 1 */
static char *mem_max_addr; /* Max legal heap addr plus 1*/
/*
* mem_init - Initialize the memory system model
*/
void mem_init(void) {
mem_heap = (char *)Malloc(MAX_HEAP);
mem_brk = (char *)mem_heap;
mem_max_addr = (char *)(mem_heap + MAX_HEAP);
}
/*
* mem_sbrk - Simple model of the sbrk function. Extends the heap
* by incr bytes and returns the start address of the new area. In
* this model, the heap cannot be shrunk.
*/
void *mem_sbrk(int incr) {
char *old_brk = mem_brk;
if ( (incr < 0) || ((mem_brk + incr) > mem_max_addr)) {
errno = ENOMEM;
fprintf(stderr, "ERROR: mem_sbrk failed. Ran out of memory...\n");
return (void *)-1;
}
mem_brk += incr;
return (void *)old_brk;
}
// mm_init creates a heap with an initial free block
int mm_init(void) {
/* Create the initial empty heap */
if ((heap_listp = mem_sbrk(4*WSIZE)) == (void *)-1)
return -1;
PUT(heap_listp, 0); /* Alignment padding */
PUT(heap_listp + (1*WSIZE), PACK(DSIZE, 1)); /* Prologue header */
PUT(heap_listp + (2*WSIZE), PACK(DSIZE, 1)); /* Prologue footer */
PUT(heap_listp + (3*WSIZE), PACK(0, 1)); /* Epilogue header */
heap_listp += (2*WSIZE);
/* Extend the empty heap with a free block of CHUNKSIZE bytes */
if (extend_heap(CHUNKSIZE/WSIZE) == NULL)
return -1;
return 0;
}
// extend_heap extends the heap with a new free block
static void *extend_heap(size_t words) {
char *bp;
size_t size;
/* Allocate an even number of words to maintain alignment */
size = (words % 2) ? (words+1) * WSIZE : words * WSIZE;
if ((long)(bp = mem_sbrk(size)) == -1)
return NULL;
/* Initialize free block header/footer and the epilogue header */
PUT(HDRP(bp), PACK(size, 0)); /* Free block header */
PUT(FTRP(bp), PACK(size, 0)); /* Free block footer */
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); /* New epilogue header */
/* Coalesce if the previous block was free */
return coalesce(bp);
}
// mm_free frees a block and uses boundary-tag coalescing to merge it with any adjacent free blocks in constant time
void mm_free(void *bp) {
size_t size = GET_SIZE(HDRP(bp));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
coalesce(bp);
}
static void *coalesce(void *bp) {
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
size_t size = GET_SIZE(HDRP(bp));
if (prev_alloc && next_alloc) { /* Case 1 */
return bp;
} else if (prev_alloc && !next_alloc) { /* Case 2 */
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size,0));
} else if (!prev_alloc && next_alloc) { /* Case 3 */
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
} else { /* Case 4 */
size += GET_SIZE(HDRP(PREV_BLKP(bp))) +
GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
return bp;
}
// mm_malloc allocates a block from the free list
void *mm_malloc(size_t size) {
size_t asize; /* Adjusted block size */
size_t extendsize; /* Amount to extend heap if no fit */
char *bp;
/* Ignore spurious requests */
if (size == 0)
return NULL;
/* Adjust block size to include overhead and alignment reqs. */
if (size <= DSIZE)
asize = 2*DSIZE;
else
asize = DSIZE * ((size + (DSIZE) + (DSIZE-1)) / DSIZE);
/* Search the free list for a fit */
if ((bp = find_fit(asize)) != NULL) {
place(bp, asize);
return bp;
}
/* No fit found. Get more memory and place the block */
extendsize = MAX(asize,CHUNKSIZE);
if ((bp = extend_heap(extendsize/WSIZE)) == NULL)
return NULL;
place(bp, asize);
return bp;
}
显式空闲链表
隐式空闲链表简单直接,每个区块不需要存放过多的额外信息,缺点是每次分配都需要把所有区块遍历一遍,但是因为有区块分割与合并,很多时候我们基本不需要关注被分配的区块,我们只需要关注未分配的区块,或许我们可以考虑在区块中添加一些辅助信息,让我们在分配时只考虑未分配的区块,也就是显式空闲链表:
分配的区块还是和隐式空闲链表一样,未分配的区块中多了两个指针分别指向前一个未分配的区块和后一个未分配的区块。虽然未分配的区块中使用了额外的信息,但是这并没有对整体资源造成浪费,因为分配的区块中并没有这些信息,这些信息不会占据实际存放的数据(payload)的空间。
当然,显式空闲链表也是存在问题的,因为未分配的区块需要足够大才能存放的下这些额外信息,区块的最小空间不能太小,这会在一定程度上造成碎片化。
分离的空闲链表
不管是隐式还是显式,区块中或多或少都会使用额外的辅助信息,而且每次分配的时或多或少都需要对现有区块进行遍历。另外一种截然不同的设计思路是,将区块按照大小进行分组,每组只含有相同或相近大小的区块,这样在分配时我们可以通过需要分配的大小直接定位到区块组中的区块,省去了遍历,配分时会非常高效,而且区块中也不需要存放诸如头标、脚标这样的辅助信息。
这种结构的一大缺点就是可能造成大量的内存碎片化,因为我们并不清楚一个应用程序会如何调用分配器,每次需要分配多大的内存,每种分配大小的占比是多少等等,因而单纯的分离链表的优势并不明显,往往这种结构需要结合前面的隐式空闲链表和显式空闲链表来使用。
我们还是会根据区块大小来分组,不过每组都是一个隐式空闲链表或显式空闲链表,这样往往遍历的时间会大大降低,另外在这个组合结构中也是有分割与合并机制来降低内存的碎片化,像是 C 中的标准库函数就是应用类似的方式。
垃圾回收
前面我们所讲的堆内存分配器都是需要应用程序手动调用类似 malloc 和 free 这样的函数对的空间进行分配和回收,然而为了简化应用程序,很多编程语言都有着更加自动化机制,也就是应用程序不需要考虑内存的分配和回收,分配还好说,大小可以根据应用程序要创建的数据结构来计算得出,麻烦的是回收。
分配器必须保证回收的内存不会被应用程序再次引用,垃圾回收机制将内存看作是一个有向图,如下所示:
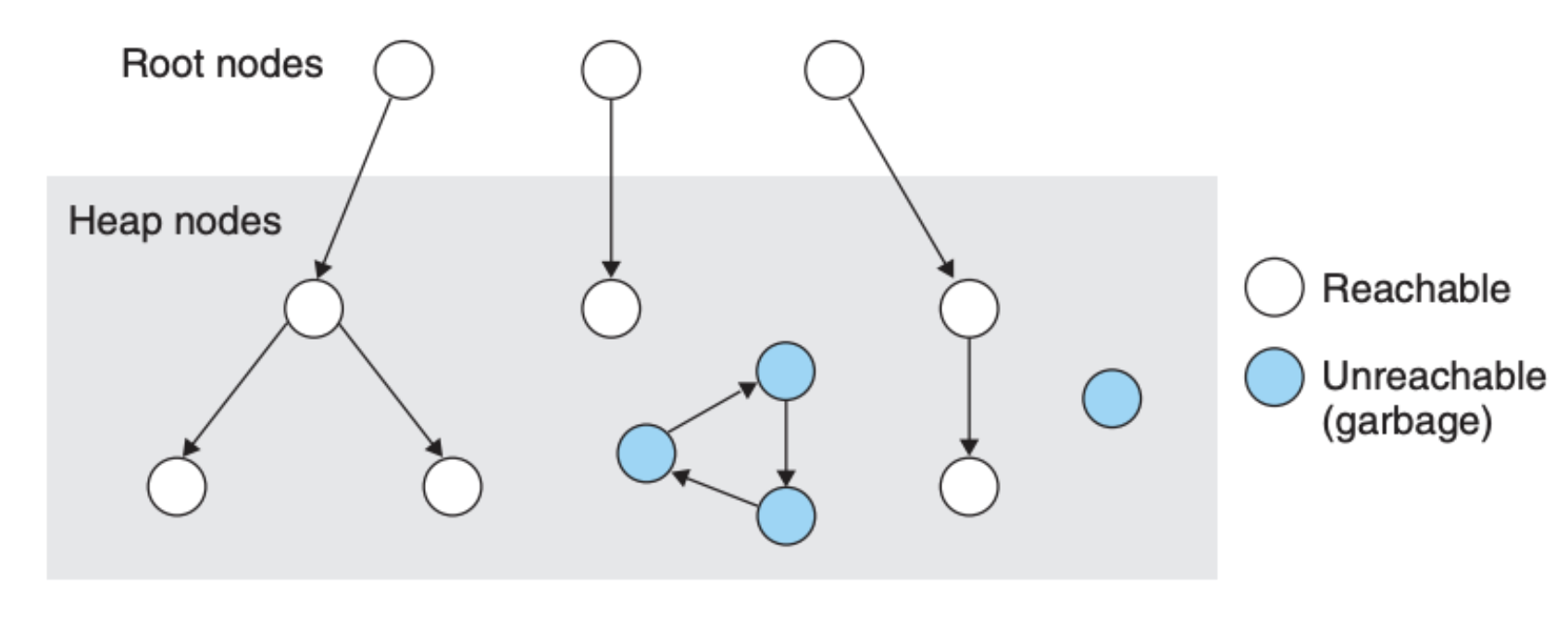
图中的 Root nodes 对应的是指向内存区域的指针,比如说是存放在寄存器中的内存地址,Heap nodes 对应的是存放在内存中的数据,如果说内存区域的数据块没有被内存外的指针所引用(图中蓝色节点),那么这部分内存区域理论来说是可以被回收(释放)的。
类似 Java 这样的语言,对应用如何创建和使用指针有严格的控制,它的垃圾回收机制可以精确维护上图,因此也能够回收所有的 Unreachable 区域。然而类似 C 这样的语言,它的回收机制无法精确维护上图,因而它的回收机制是保守型的,也就说不会遗漏任何的 Reachable 数据,但是有可能有些 Unreachable 的数据也被标记为 Reachable,比如某个 Reachable 的节点不再被 Root nodes 引用,但是节点的标记并没有马上改变。
C 中的保守型垃圾回收机制大致如下:
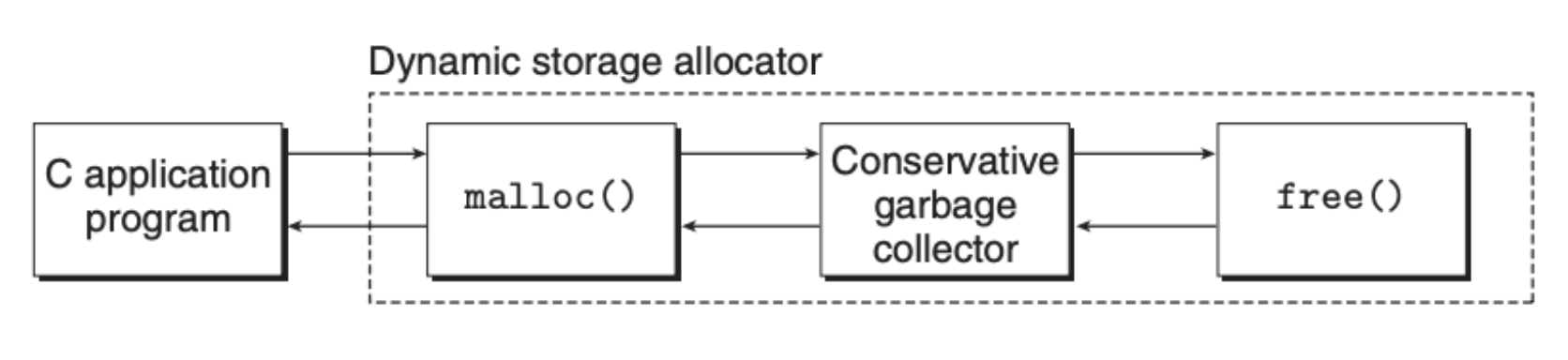
这里的核心思想是回收器来替代应用程序调用 free 函数。
常见的回收机制是 Mark&Sweep,回收机制分为两个阶段,在标记(Mark)阶段中标记所有可到达节点(Reachable),紧接着是清理(Sweep)阶段,这个阶段要做的事就是清理(释放)没有被标记的节点(Unreachable)。下面两个伪函数可以很好地表达这个思想:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
void mark(ptr p) {
if ((b = isPtr(p)) == NULL)
return;
if (blockMarked(b))
return;
markBlock(b);
len = length(b);
for (i=0; i < len; i++)
mark(b[i]);
return;
}
void sweep(ptr b, ptr end) {
while (b < end) {
if (blockMarked(b))
unmarkBlock(b);
else if (blockAllocated(b))
free(b);
b = nextBlock(b);
}
return;
}
下图是这个机制运作的例子:
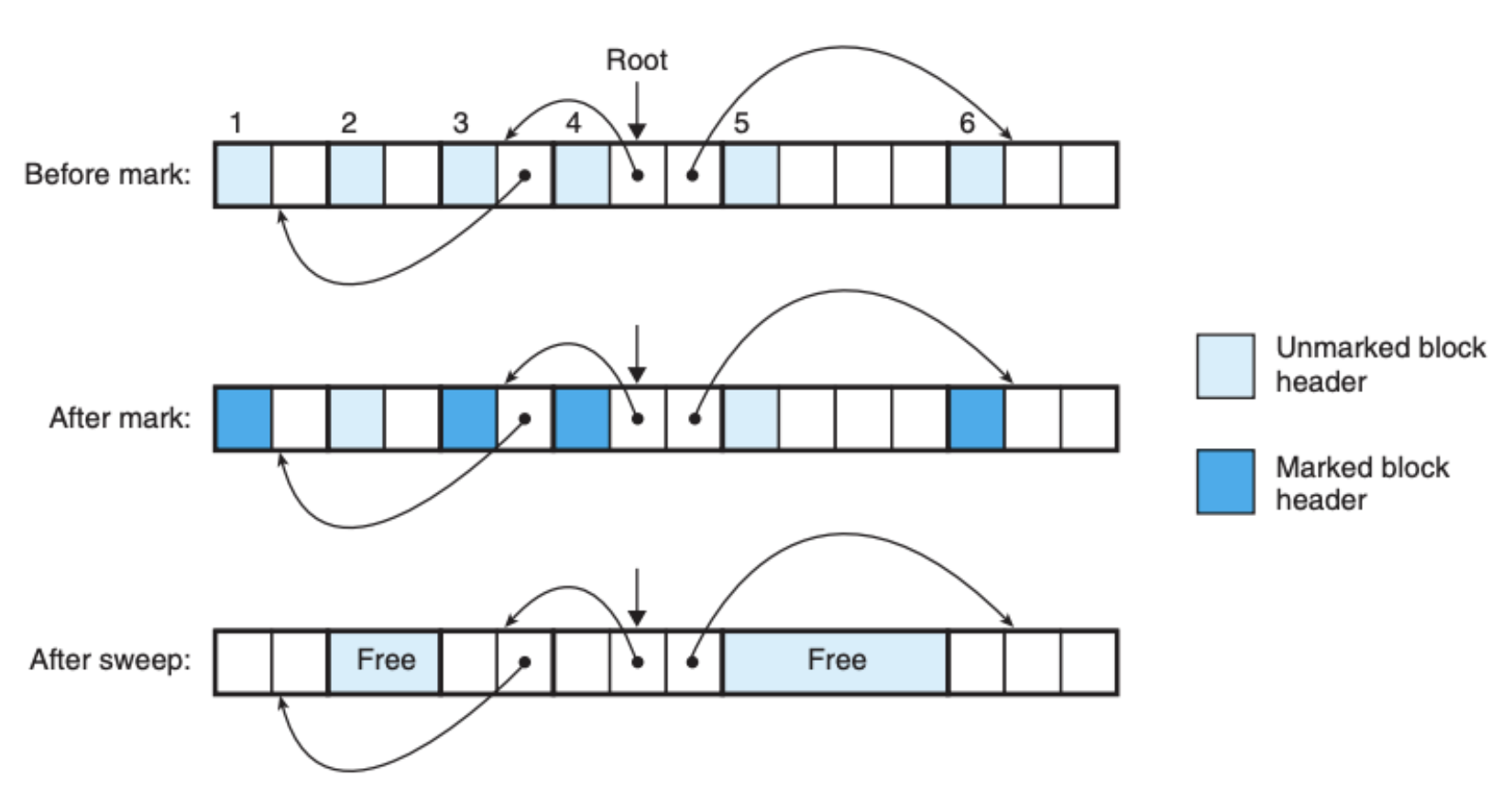
这种方式比较适合类似 C 这样的语言,因为它不需要移动任何的区块。但是 C 中的 Mark&Sweep 是保守型的,首先 C 并没有在内存中标记数据类型,所以伪代码中的 isPtr 没法 100% 确定它的输入是指针类型或是其他类型。另外,即使我们确认一个数据的类型是指针,我们也无法得出这个指针指向的数据是存在于被分配的区块中,也有可能它指向的是已经被释放的区块。后者好解决,无非存储额外的信息,但是前者是编程语言的特性,没法很好地解决,这也就是为什么 C 这样的语言一直都需要应用程序来管理虚拟内存,没法完全自动化。
C 中常见的内存错误
错误的解引用:
这种错误常常发生在函数传参中,错误地将地址当成数据,或是将数据当成地址,例子:
1
2
3
4
5
// Wrong
scanf("%d", val)
// Correct
scanf("%d", &val)
读取没有初始化的内存
malloc 函数仅仅是分配内存,并没有初始化内存,例子:
1
2
3
4
5
6
7
8
9
/* Return y = Ax */
int *matvec(int **A, int *x, int n) {
int i, j;
int *y = (int *)Malloc(n * sizeof(int)); // A correct implementation would use calloc here
for (i = 0; i < n; i++)
for (j = 0; j < n; j++)
y[i] += A[i][j] * x[j];
return y;
}
允许缓存区溢出
很多时候我们在栈内存中定义了一个固定大小 buffer 数组,但是在使用的时候我们并没有考虑它的大小,因为 C 中不会检查数组大小,用超了没有错误提示,并且可能会覆盖其他栈内存,从而造成更加严重的后果:
1
2
3
4
5
void bufoverflow() {
char buf[64];
gets(buf); // To fix this, we would need to use the fgets function, which limits the size of the input string
return;
}
假设指针与其指向的区块有着同样的大小
例子:
1
2
3
4
5
6
7
8
/* Create an nxm array */
int **makeArray1(int n, int m) {
int i;
int **A = (int **)Malloc(n * sizeof(int)); // correct is ...Malloc(n * sizeof(int *))
for (i = 0; i < n; i++)
A[i] = (int *)Malloc(m * sizeof(int));
return A;
}
引用一个指针而不是它所指向的数据
例子:
1
2
3
4
5
6
7
int *binheapDelete(int **binheap, int *size) {
int *packet = binheap[0];
binheap[0] = binheap[*size - 1];
*size--; /* This should be (*size)-- */
heapify(binheap, *size, 0);
return(packet);
}
错误理解指针运算
例子:
1
2
3
4
5
int *search(int *p, int val) {
while (*p && *p != val)
p += sizeof(int); /* Should be p++ */
return p;
}
引用不存在的变量
很多 C 语言初学者不理解栈的特性和运作,会写出类似下面这样的程序:
1
2
3
4
int *stackref() {
int val;
return &val;
}
因为一个函数执行完成后,其在栈上的空间(包括函数所创建的局部变量)就会被释放,这个内存空间很有可能被其他的函数所使用,上面的例子中的 stackref 函数返回一个被释放掉的地址,这显然存在着问题。
引用已经被释放的内存
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
int *heapref(int n, int m) {
int i;
int *x, *y;
x = (int *)Malloc(n * sizeof(int));
.
. // Other calls to malloc and free go here
.
free(x);
y = (int *)Malloc(m * sizeof(int));
for (i = 0; i < m; i++)
y[i] = x[i]++; /* Oops! x[i] is a word in a free block */
return y;
}
内存泄漏
例子:
1
2
3
4
void leak(int n) {
int *x = (int *)Malloc(n * sizeof(int));
return; /* x is garbage at this point */
}
总结
总的来说虚拟内存为计算机存储系统提供了三个重要的能力:
- 自动缓存最近使用过的存放在硬盘或是内存中的空间
- 简化了内存管理、链接、进程间的数据共享、进程的内存分配以及程序的加载
- 虚拟内存通过在页表中引入权限位来简化内存保护机制
这三方面都是计算机高效运作所不可或缺的。