初识网络编程
概述
这篇文章是对 CSAPP 第十一章的总结。这里有两个重点,一个是网络,另一个是编程,我们需要了解计算机网络的大致结构,这有助于我们理解类似 TCP/IP 这样的核心协议,除此之外,socket 接口是网络编程绕不开的,除了知道这些接口函数的功能之外,我们更需要理解其背后的思想和设计理念,因为这些东西才是本质的,清楚了解了它们,我们才能知其然也知其所以然。
网络
客户端服务器编程模型
客户端服务器模型是计算机网络的基础,结构如下图所示:
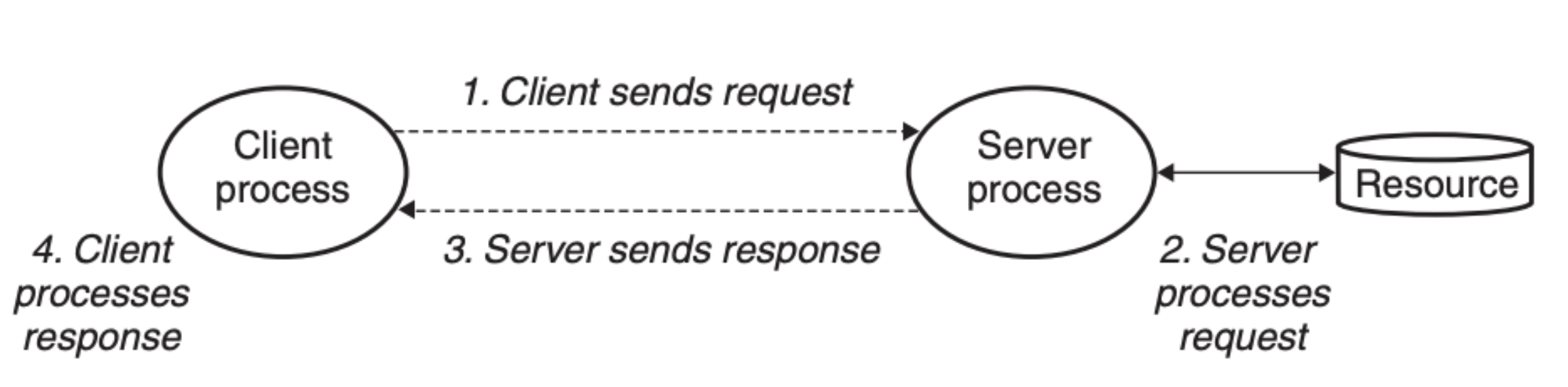
我相信有一些编程基础的人都能看懂上面的模型,但是有一点需要强调,这里的客户端或服务端表示的是进程,而非主机,因为客户端和服务端也可以存在于一台主机上。另外,从这张图我们可以得到以下结论:
- 客户端是请求的发起者
- 服务端是请求的响应者
- 客户端和服务端在图中显示的是 1 对 1 的关系,但是它们也可以扩展成为多对多的关系
- 客户端的重点是依据正确的格式发送请求,并正确地处理请求的结果
- 服务端的重点是依据请求来提供对应的服务,并按照正确的格式进行响应
这里 4,5 需要依赖于客户端和服务端之间拟定的接口,以及选择的网络协议。这就好像是两个人面对面交谈,其中一个人(客户端)问问题,另一个人(服务端)作解答,两个人都需要用双方能听得懂的语言来传达信息,这样信息才会被正确理解。当然,例子归例子,这个模型远没有人与人交谈复杂,它限定了一方只会问问题,另一方只会作解答,更重要的是,解答的一方往往只看问题(请求)不看人,而正常的人与人的交流中,双方都可以是提问者,并且问题的回答内容有很大程度的不确定性。
客户端服务器编程模型之所以重要是因为所有的网络应用都是基于这个模型,只不过它们在此之上所依赖的协议会有所不同。
网络结构
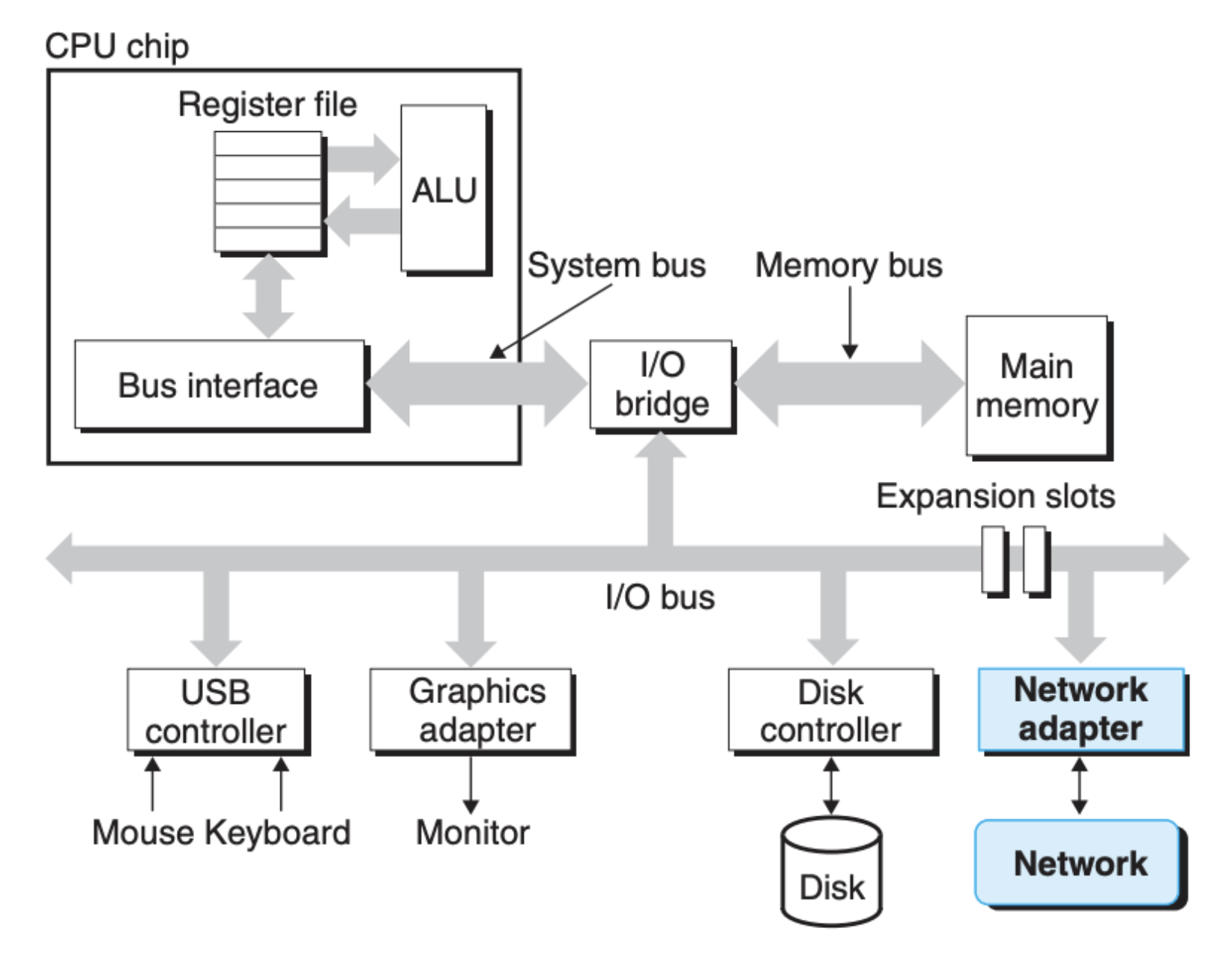
既然两台计算机能够互相交流,那么它们之间必定存在一个可以传递信息的媒介,我们由里到外来看看这个结构的大致情况。首先,在单个计算机的内部存在一个网络的 I/O 接口(关于 I/O,可以回看 前面一篇文章),这个接口负责对外信息的传递和接收,如下图所示:
多台主机可以通过集线器(Hub)构成一个以太网段(Ethernet segment),如下图所示:
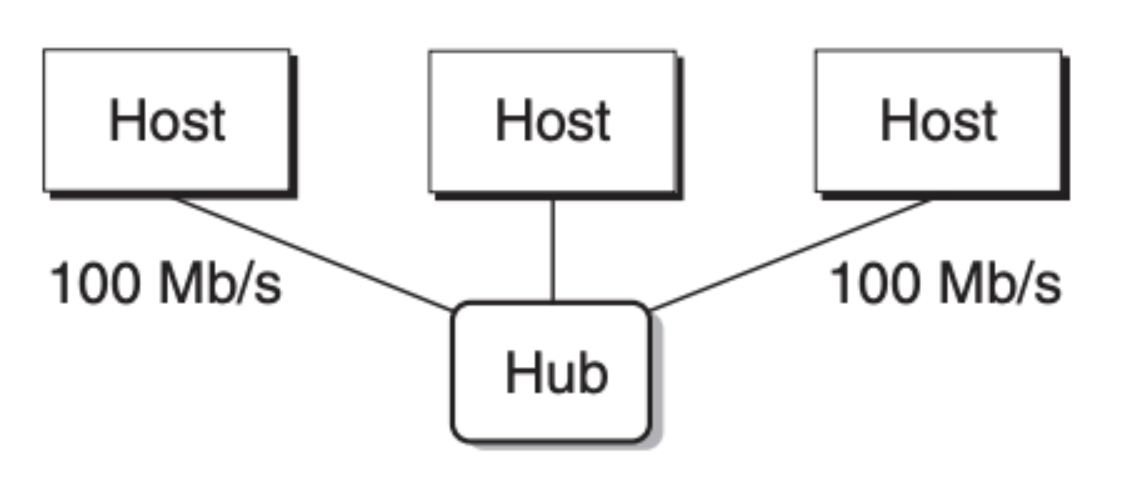
需要注意的是,集线器会不加分辨地将一端的收到的数据复制到其他所有端口上,因此这里的每台主机(Host)都能看到每个位。
多个以太网段又可以被网桥(bridge)来连接形成较大的局域网(LAN):
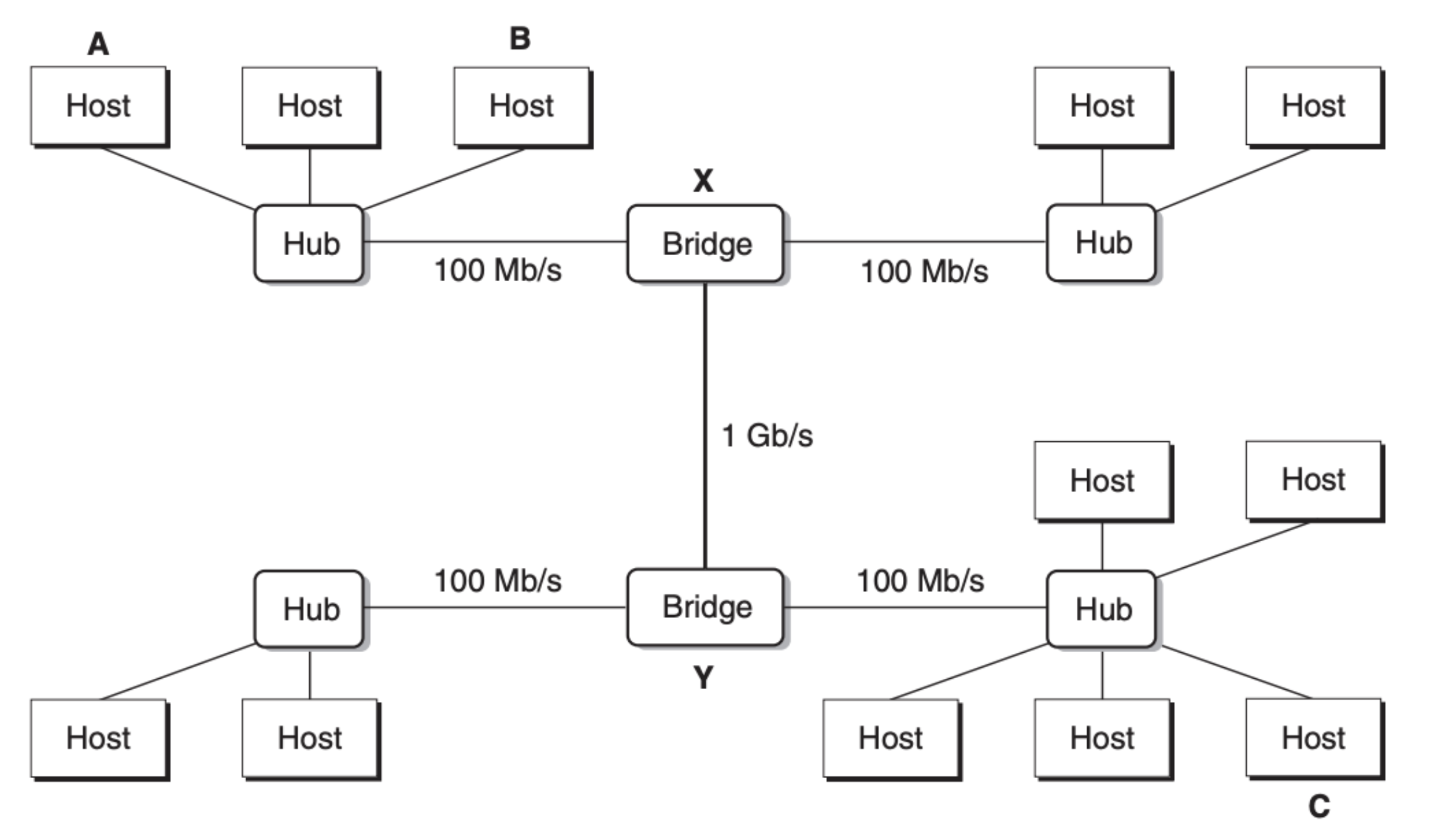
一个局域网可以有很多网桥,网桥中运行着一些智能的分布式算法,它们会根据传过来的数据决定传递的方向。
局域网可以被特定的主机——路由器(router)相连而形成广域网(WAN):
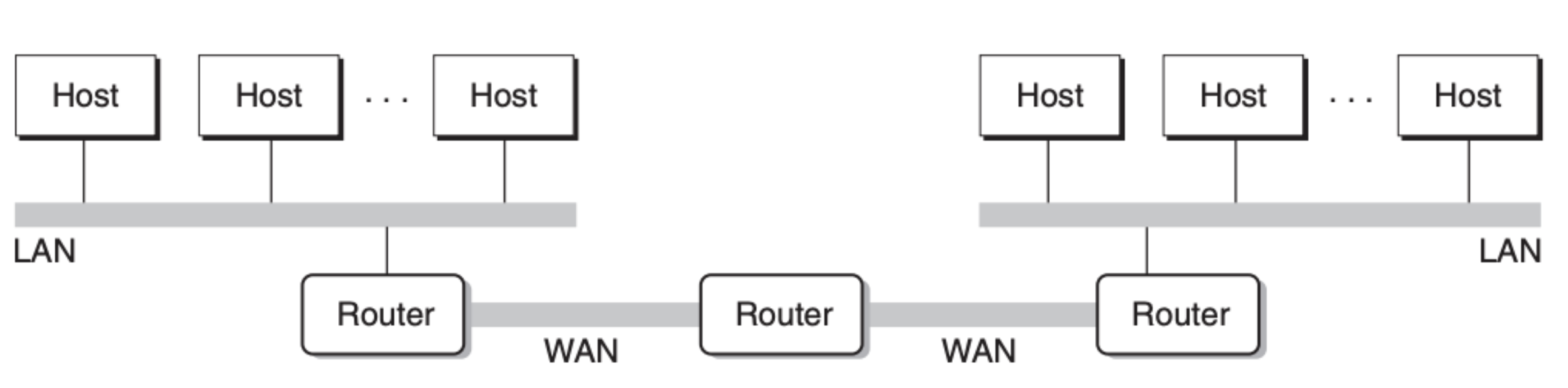
通过这种层层连接的方式,整个网络会变的非常的庞大,但是又可以很灵活,这里的灵活体现在每一层可以使用完全不同的技术或是结构,比如主机的操作系统不受限制、集线器连接的主机数量不受限制、局域网的结构不受限制等等。
在上述的硬件结构下,两个主机是如何交流的呢?下图可以清晰地展现这个过程:
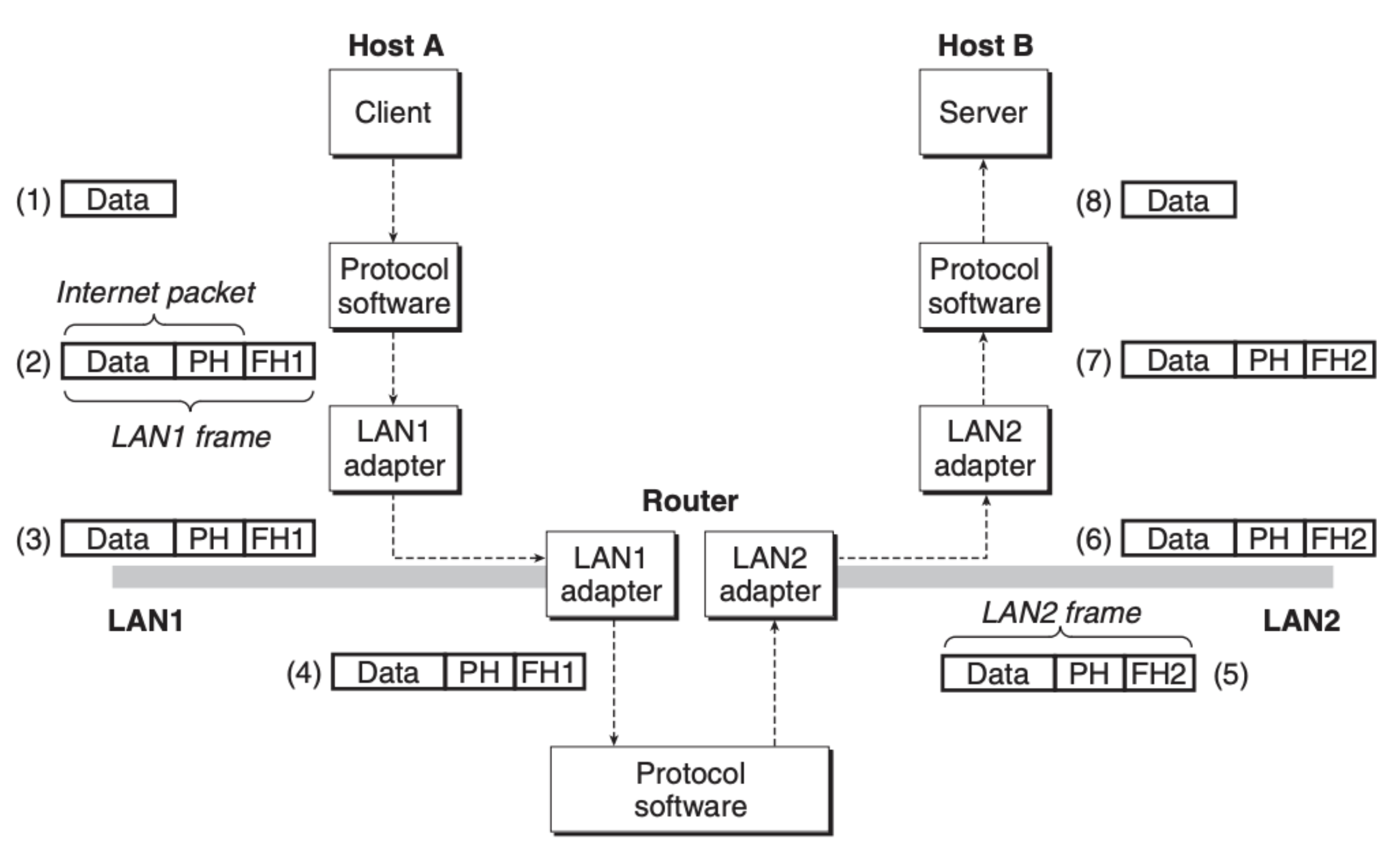
这里的核心就是对数据帧(frame)进行封装,添加额外的信息,这些信息在数据传递的过程中帮助定位到目的地,比如上图中 LAN1 和 LAN2 本来是不兼容的局域网,但是通过路由器的转化,信息依旧可以正常地传输。
IP
IP(Internet Protocol)可以说是互联网最基础的协议了,IP 地址标识了某个主机的位置,上面讲的网络结构中的路由器会根据数据帧中的 IP 地址来决定推送的方向。但是 IP 协议并不可靠,也就是说当数据帧发生丢失,或是被复制成多份,接收端并不会知晓。因而,单靠 IP 协议并不能保证双方信息的有效性和可靠性。TCP 协议就是为了解决这个问题的,它构建于 IP 协议之上,为两个进程之间提供双向的可靠连接。另外还有一个 UDP 协议,这个协议仅仅是将 IP 协议进行延伸,让数据帧能够在进程之间传递,而不仅仅是主机之间。
下图展示了基于一个互联网应用的软硬件组织:
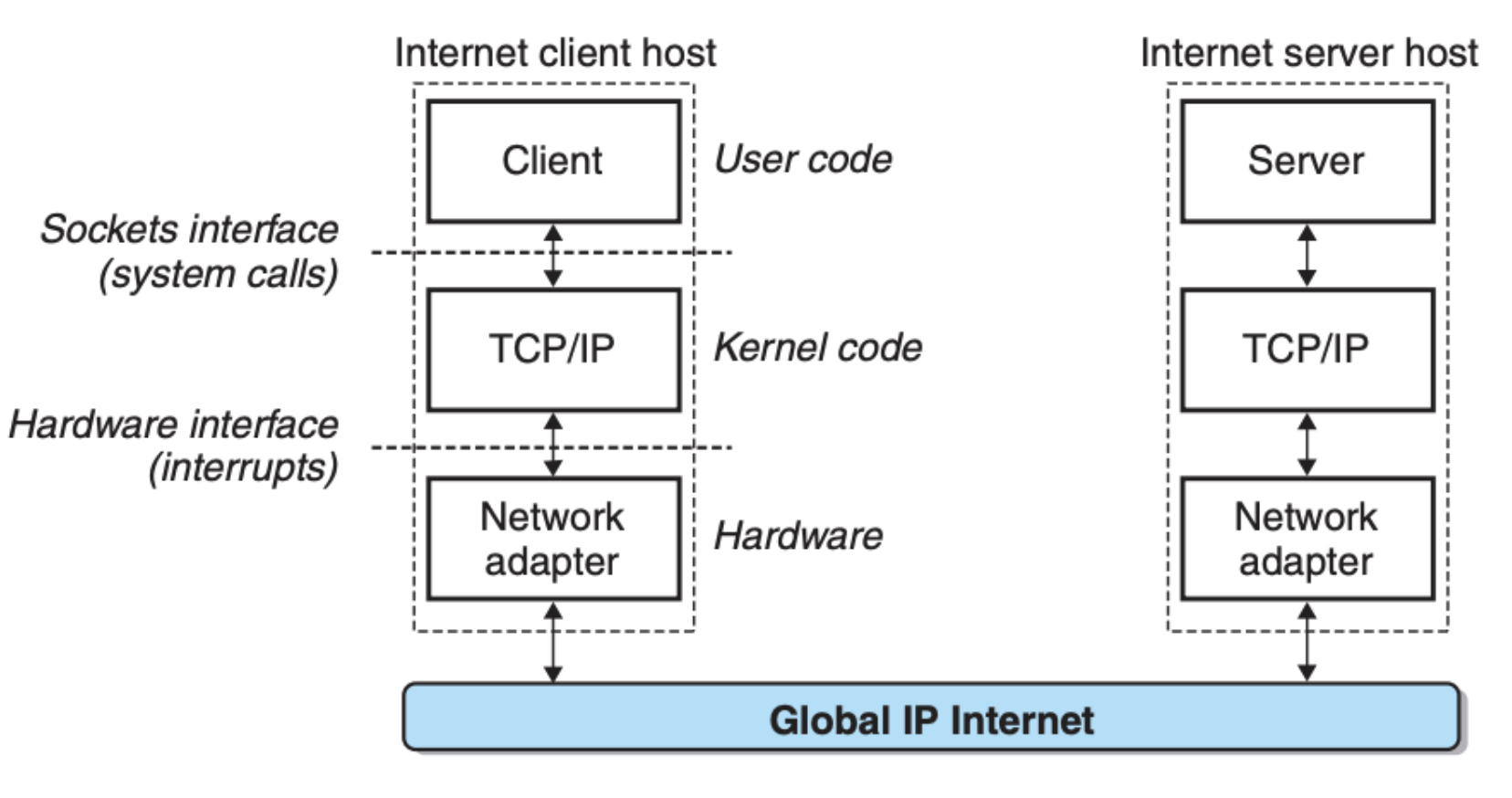
可以看到,跟网络协议(TCP/IP)相关的代码运行于操作系统内核中,用户的程序需要借助套接字接口(Sockets interface)来调用这些代码。因而,如果要构建网络应用,学习并了解这些套接字接口则是必要的。在说这个之前,我们先来看看关于 IP 的一些定义。
网络程序将 IP 地址存放于一个如下所示的结构体中:
1
2
3
4
/* IP address structure */
struct in_addr {
uint32_t s_addr; /* Address in network byte order (big-endian) */
};
现在看来,更合理的做法是将 IP 地址定义成一个标量,而非结构体,但是现在要改是很难的,因为已经有大量的应用是基于此来构建的。另外,为了统一,IP 地址均是按照网络的字节顺序(大端模式)来进行编码的,而我们知道,每个操作系统会存在不同的大小端模式,为此,Unix 系统提供了下列转换函数:
1
2
3
4
5
6
7
8
9
#include <arpa/inet.h>
// Returns: value in network byte order
uint32_t htonl(uint32_t hostlong);
uint16_t htons(uint16_t hostshort);
// Returns: value in host byte order
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);
你可能会觉得,IP 地址不应该是字符串吗?表示称字符串不是更直接也更清晰吗?问题在于,字符串仅仅是方便人的阅读,其中包含了很多无效信息(主要是分割符 .),另外会占用更多的空间,也不方便计算机的处理。关于如何转换的,这里举一个例子,比如对于 IPv4 128.2.194.242,会被转化成 0x8002c2f2,仔细观察不难发现规律,IP 中的每个区段对应于无符号整数的一个字节。当然,Unix 系统也提供了对应的转化函数来方便编程:
1
2
3
4
5
6
7
#include <arpa/inet.h>
// Returns: 1 if OK, 0 if src is invalid dotted decimal, −1 on error
int inet_pton(AF_INET, const char *src, void *dst);
// Returns: pointer to a dotted-decimal string if OK, NULL on error
const char *inet_ntop(AF_INET, const void *src, char *dst, socklen_t size);
另外,因为 IP 很难记,并不便于使用,我们在输入网址的时候并不会输入 IP,输入的是 IP 对应的域名。域名其实是一个如下图所示的树形层级结构:
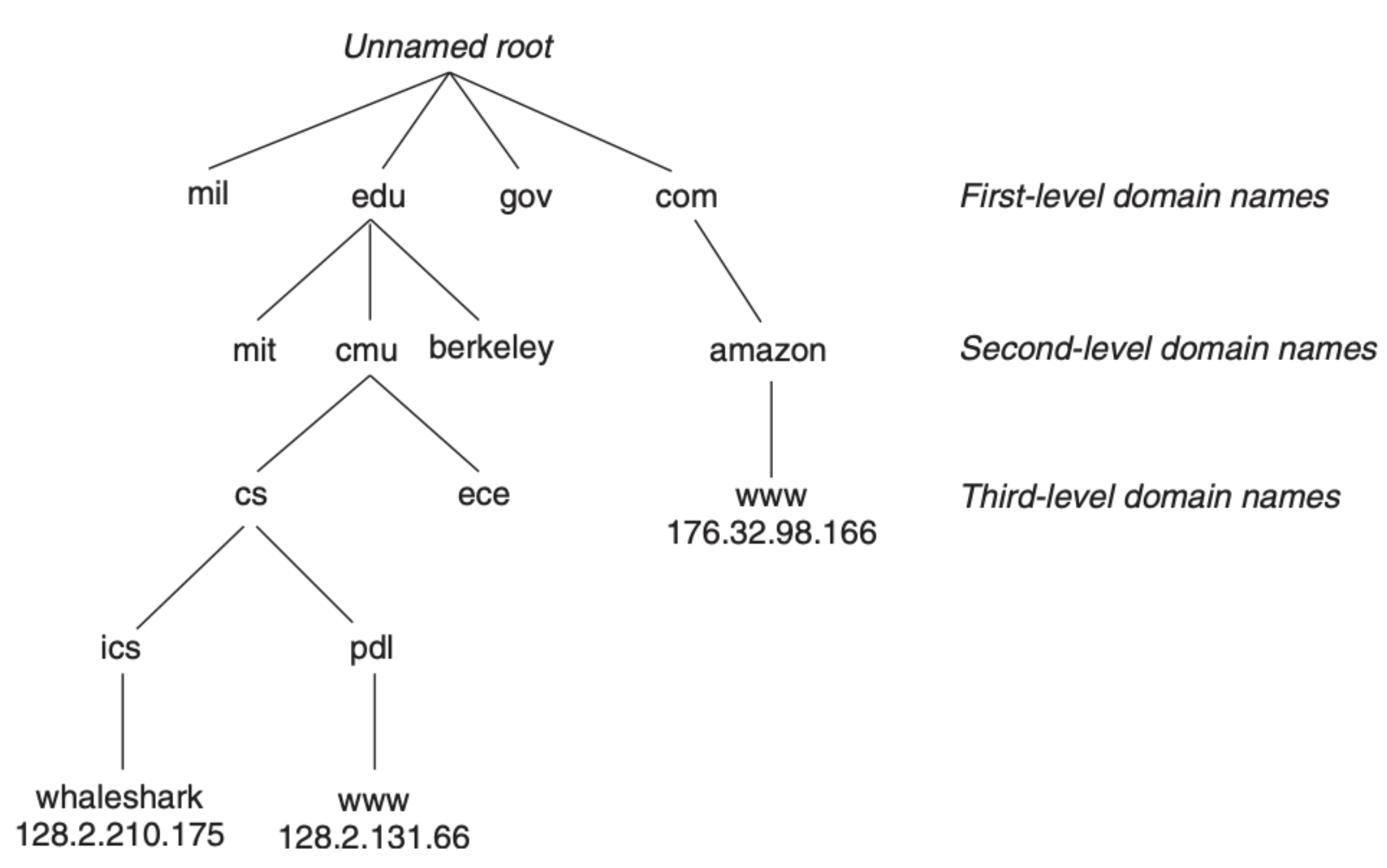
在 Linux 系统中,我们可以使用 nslookup 指令来寻找域名所对应的 IP:
1
2
linux> nslookup localhost
Address: 127.0.0.1
套接字
套接字是一个连接的终端,比如下图所示的一对网络连接:

从这张图我们可以得到下面这些信息:
- 每个套接字的地址(socket address)是由 IP 地址和 16 位的整数端口号所组成
- 一个连接可以独一无二地表示成一个套接字对——
(cliaddr:cliport, servaddr:servport)
从操作系统内核的角度来看,套接字是连接的终端,从用户程序来看,套接字是一个打开的文件(理解这一点有助于我们后面了解接口)。另外,/etc/services 文件中存放了比较重要的端口号以及其对应的名称。
套接字接口
我们前面说过,应用程序的构建离不开套接字接口,而因为网络的复杂性,我们需要的是一套接口而不是一个,具体的接口函数如下所示:
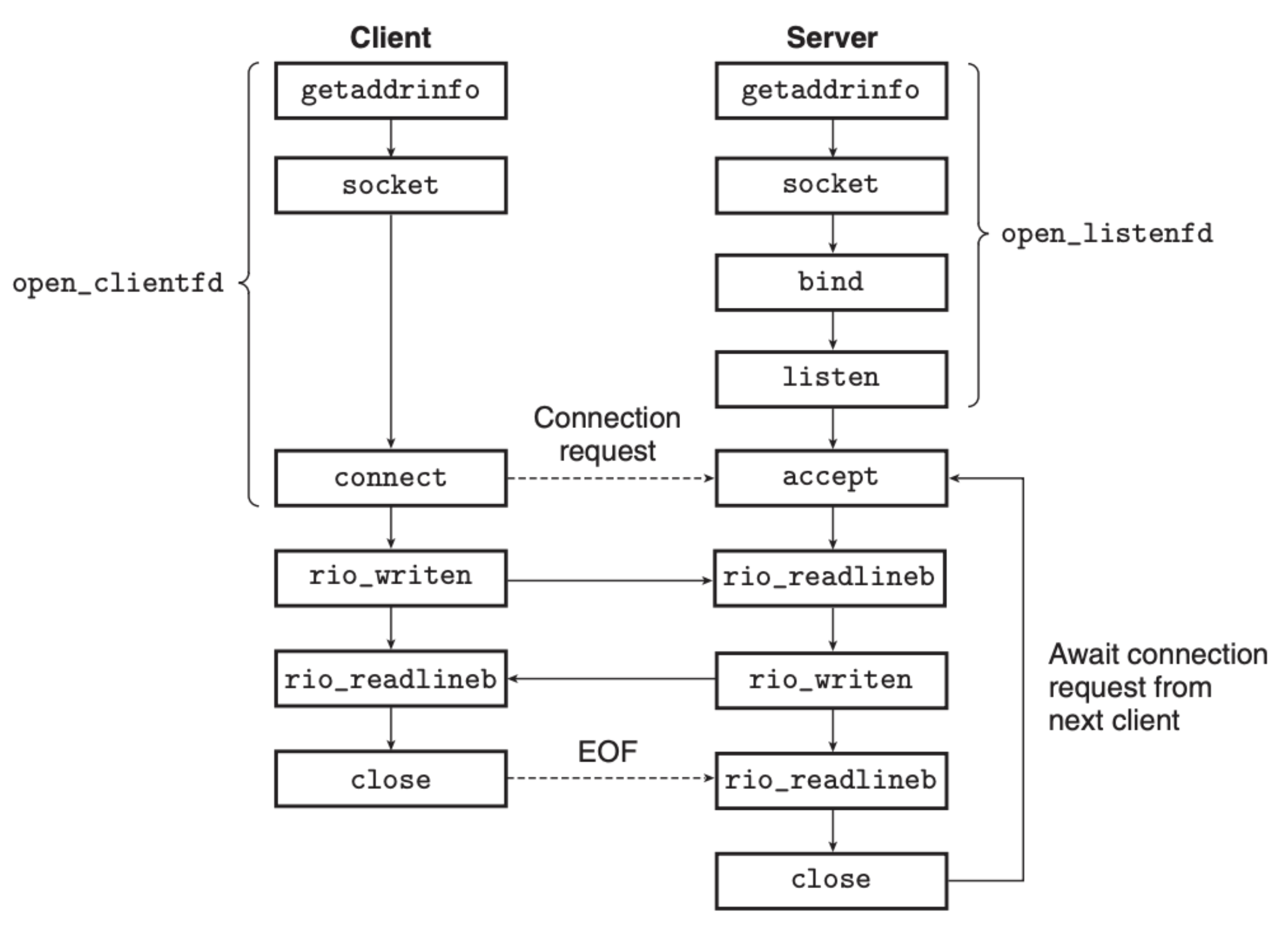
至于说为什么要这么复杂,并且客户端和服务端不一样,这个我们后面会解释,并且我们后面还会将上述函数进行组合形成用户友好的 open_clientfd 和 open_listenfd 函数。但是在这之前,我们需要理解上述每个函数的目的。
套接字地址是存放在下面定义的结构体中:
1
2
3
4
5
6
7
8
9
10
11
12
13
/* IP socket address structure */
struct sockaddr_in {
uint16_t sin_family; /* Protocol family (always AF_INET) */
uint16_t sin_port; /* Port number in network byte order */
struct in_addr sin_addr; /* IP address in network byte order */
unsigned char sin_zero[8]; /* Pad to sizeof(struct sockaddr) */
};
/* Generic socket address structure (for connect, bind, and accept) */
struct sockaddr {
uint16_t sa_family; /* Protocol family */
char sa_data[14]; /* Address data */
};
因为一些历史原因,关于套接字有两个结构,但是对于网络套接字,以第二种为主。
socket
我们前面说过,对于应用程序来说,socket 就是一个文件,因而通过 socket 建立连接的第一步就是创建这个文件,具体的接口定义如下所示:
1
2
3
4
5
#include <sys/types.h>
#include <sys/socket.h>
// Returns: nonnegative descriptor if OK, −1 on error
int socket(int domain, int type, int protocol);
比如我们可以这样使用:clientfd = socket(AF_INET, SOCK_STREAM, 0);,这里的 AF_INET 表明我们使用的是 32 位的 IP 地址,SOCK_STREAM 表明这个 socket 将会被用作连接的终端,当然,最佳实践是通过 getaddrinfo 函数来自动生成这些参数,这个我们后面会讲到。需要注意的是,socket 函数返回的文件还不能直接被使用,也就是说这个文件仅仅是半打开(partially opened),我们还需要确定这个 socket 文件是被用于客户端还是服务端,这两者在定义和使用上会有明显的区别。
我们可以把这一步看作是创建网络通信所必需的 I/O 文件。
connect
客户端通过 connect 函数来与服务端确立连接:
1
2
3
4
#include <sys/socket.h>
// Returns: 0 if OK, −1 on error
int connect(int clientfd, const struct sockaddr *addr, socklen_t addrlen);
这个函数是客户端特有的,这里会用到前面调用 socket 函数生成的文件描述符 clientfd,另外,我们还需要传入服务器端的地址信息 addr,这里的 addrlen 指的是 sizeof(sockaddr_in),最佳实践还是通过 getaddrinfo 函数来自动生成这些参数。
connect 函数会被阻塞直到连接成功或者是有错误发生,如果成功,clientfd 这是就可以开始进行读写了,并且连接的结果可以用 (x:y, addr.sin_addr:addr.sin_port) 这样的套接字对(socket pair)来表示,这里的 x 和 y 分别表示的是客户端的 IP 和端口号。
bind
服务端通过 bind 函数将服务端的地址(IP 地址+端口号)和前面调用 socket 函数生成的文件绑定起来:
1
2
3
4
#include <sys/socket.h>
// Returns: 0 if OK, −1 on error
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
listen
除了将文件和地址绑定,服务端还会调用 listen 函数来将一个激活的 socket 转化为监听状态的 socket 一边用于接收客户端发过来的请求连接:
1
2
3
4
#include <sys/socket.h>
// Returns: 0 if OK, −1 on error
int listen(int sockfd, int backlog);
这里的 backlog 参数是一个阀值,表示的是内核最对缓存的(queue)连接数量,一旦未处理的连接数量超过了这个值,内核就会开始拒绝请求。
accept
最后,服务端会调用 accept 函数来等待客户端发过来的连接:
1
2
3
4
#include <sys/socket.h>
// Returns: nonnegative connected descriptor if OK, −1 on error
int accept(int listenfd, struct sockaddr *addr, int *addrlen);
这个函数会像 connect 一样,被阻塞直到接收到请求,然后创建并返回一个文件,这个文件主要负责单个的连接。
说到这里,你会不会觉得有点绕?特别是服务端的函数,这里我们看一个例子就懂了:
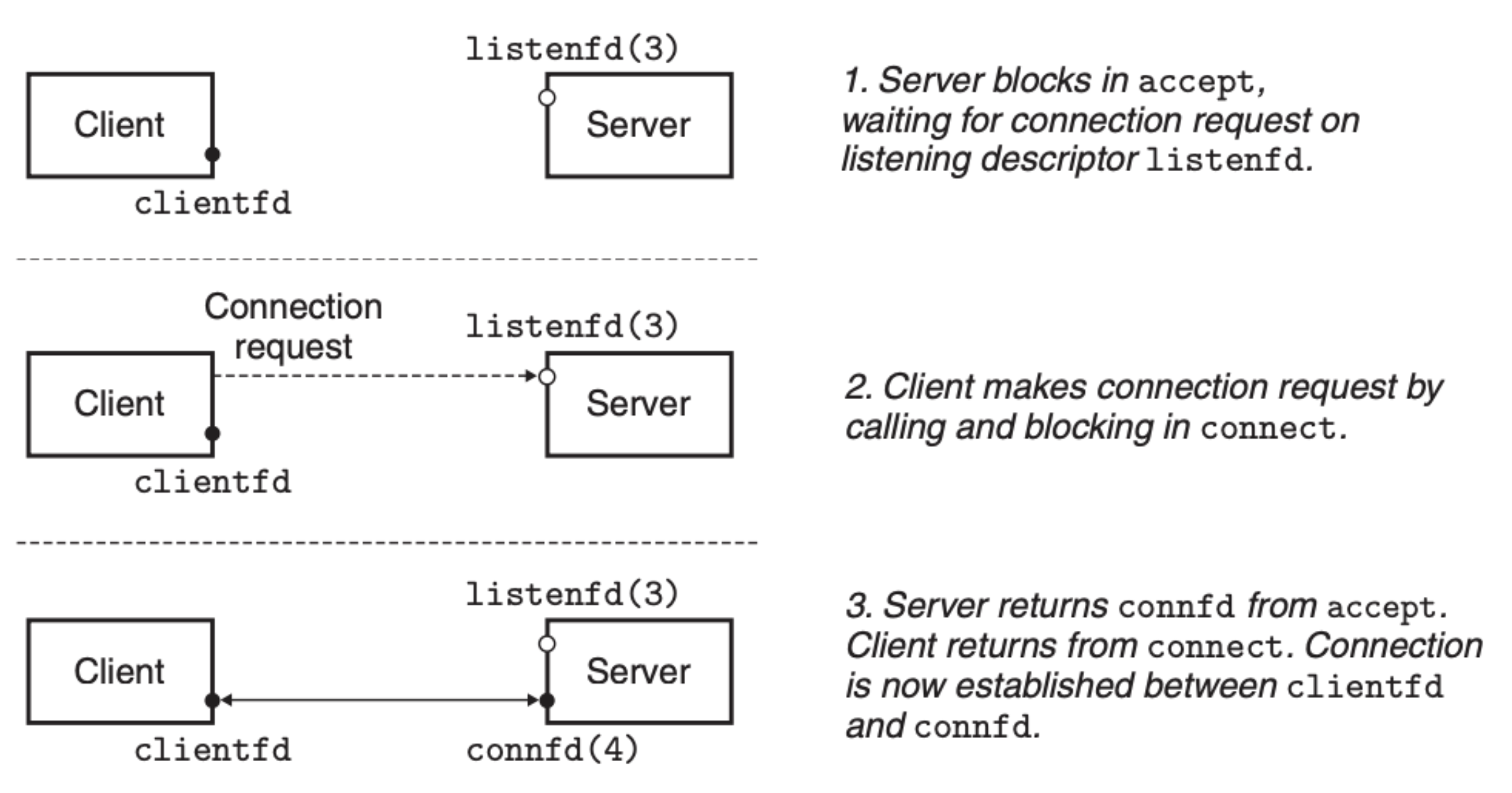
首先,客户端通过 socket 函数创建了 clientfd 文件,服务端通过 socket 创建了文件并调用 bind 将文件与对应的地址绑定起来,还调用了 listen 将这个文件置于监听状态,这样客户端以及服务端的 socket 文件都准备到位了。
接下来,客户端通过调用 connect 函数对服务端发送请求,服务端通过 accept 函数接收请求。
当服务端接收到请求,accept 会生成一个新的文件 connfd 用于此次的连接,最后连接就确立在 clientfd 和 connfd 上。
为什么要这么麻烦呢?服务端为什么不能像客户端那样只用一个套接字文件呢?原因在于服务端的套接字创建之初并不仅仅为了服务某个客户端,可能会有多个客户端同时发送请求过来,这种情况下,服务端可以构建并发的处理机制,listenfd 仅仅用于接收请求,而 connfd 用于处理请求,有多个请求就会有多个 connfd,这样大大提高了服务端的响应速度和处理效率。反观客户端,clientfd 本身就是为了某个请求,因而只需要单个即可。
主机和服务的转换
上面介绍的套接字接口需要频繁用到和 IP 协议相关的参数,如果每次都需要手动传入,那么整个套接字的创建流程就会变的非常复杂,另外 IP 协议相关的参数并不仅仅是地址,还会有其他的辅助参数,因而我们需要借助工具类函数:
1
2
3
4
5
6
7
8
9
10
11
12
#include <sys/types.h>
#include <sys/socket.h>
#include <netdb.h>
// Returns: 0 if OK, nonzero error code on error
int getaddrinfo(const char *host, const char *service, const struct addrinfo *hints, struct addrinfo **result);
// Returns: nothing
void freeaddrinfo(struct addrinfo *result);
// Returns: error message
const char *gai_strerror(int errcode);
getaddrinfo 函数会将地址等相关信息存放到 result 中,其指向的是一个 addrinfo 结构链表,如下图所示:
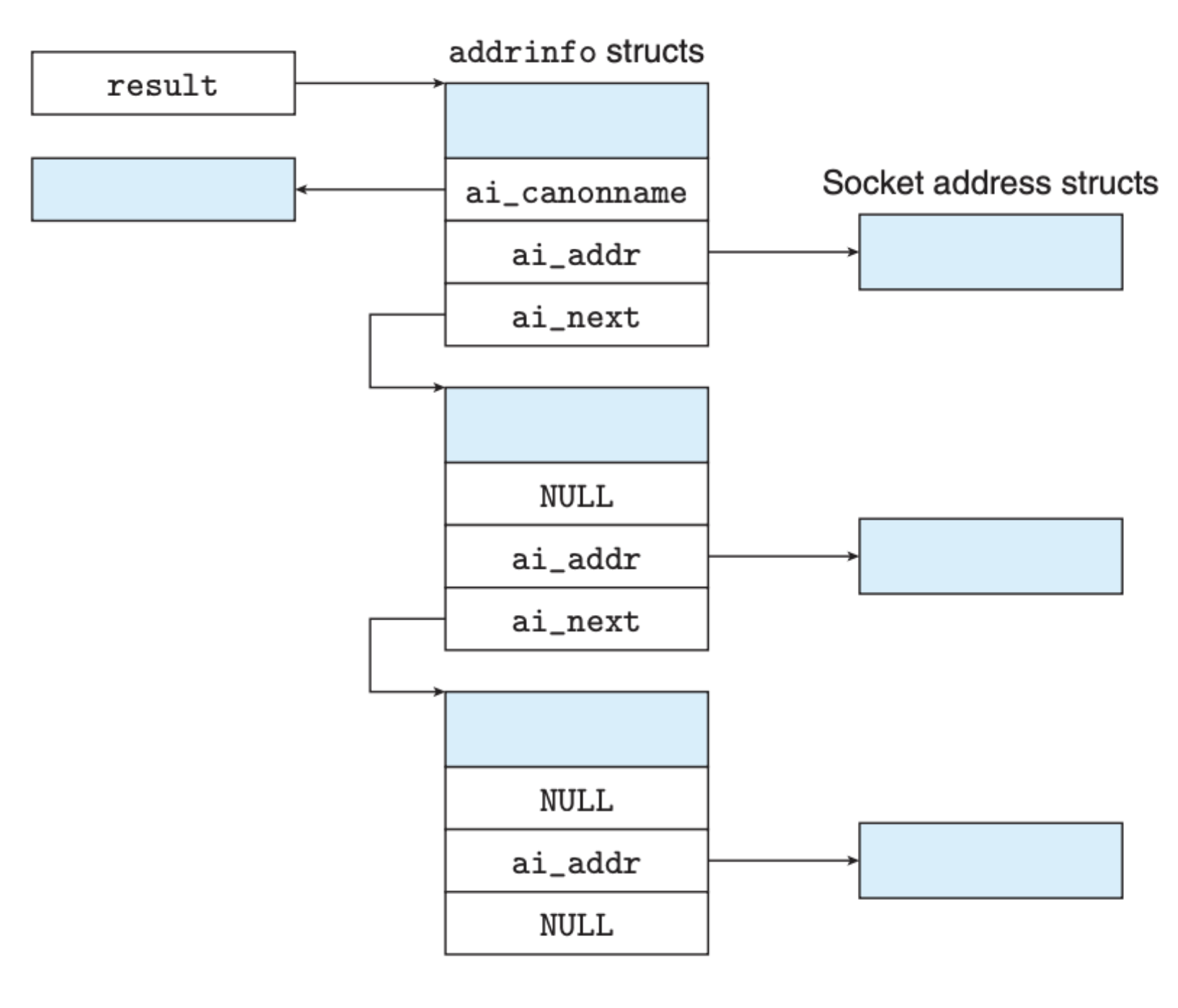
当客户端调用 getaddrinfo 时,函数会遍历上面这个链表直到套接字连接被建立,服务端也是类似的,函数会遍历链表直到套接字文件绑定上有效的地址。另外,为了避免内存泄漏,不用的地址信息需要调用 freeaddrinfo 进行内存释放。还有就是如果 getaddrinfo 返回错误码(非零),可以调用 gai_strerror 将错误码转化成对应的错误信息。
addrinfo 结构的具体定义如下:
1
2
3
4
5
6
7
8
9
10
struct addrinfo {
int ai_flags; /* Hints argument flags */
int ai_family; /* First arg to socket function */
int ai_socktype; /* Second arg to socket function */
int ai_protocol; /* Third arg to socket function */
char *ai_canonname; /* Canonical hostname */
size_t ai_addrlen; /* Size of ai_addr struct */
struct sockaddr *ai_addr; /* Ptr to socket address structure */
struct addrinfo *ai_next; /* Ptr to next item in linked list */
};
这个结构等于说是在原来的套接字地址结构(struct sockaddr)之上又增加了一层抽象(addrinfo),好处是客户端和服务端的程序不会受到 IP 协议变化(IPv4 -> IPv6)的影响。
除了将 IP 信息转化为更为抽象的数据结构,我们也可以调用 getnameinfo 函数进行逆操作:
1
2
3
4
5
#include <sys/socket.h>
#include <netdb.h>
// Returns: 0 if OK, nonzero error code on error
int getnameinfo(const struct sockaddr *sa, socklen_t salen, char *host, size_t hostlen, char *service, size_t servlen, int flags);
清楚了 getaddrinfo 和 getnameinfo,我们可以实现一个类似 nslookup 的小程序来打印出域名和其对应的 IP 地址:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
#include "csapp.h"
int main(int argc, char **argv) {
struct addrinfo *p, *listp, hints;
char buf[MAXLINE];
int rc, flags;
if (argc != 2) {
fprintf(stderr, "usage: %s <domain name>\n", argv[0]);
exit(0);
}
/* Get a list of addrinfo records */
memset(&hints, 0, sizeof(struct addrinfo));
hints.ai_family = AF_INET; /* IPv4 only */
hints.ai_socktype = SOCK_STREAM; /* Connections only */
if ((rc = getaddrinfo(argv[1], NULL, &hints, &listp)) != 0) {
fprintf(stderr, "getaddrinfo error: %s\n", gai_strerror(rc));
exit(1);
}
/* Walk the list and display each IP address */
flags = NI_NUMERICHOST; /* Display address string instead of domain name */
for (p = listp; p; p = p->ai_next) {
Getnameinfo(p->ai_addr, p->ai_addrlen, buf, MAXLINE, NULL, 0, flags);
printf("%s\n", buf);
}
/* Clean up */
Freeaddrinfo(listp);
exit(0);
}
辅助函数
上面讲述的 getaddrinfo 函数以及相关的套接字接口函数都是系统层面的函数,可以看到它们之间有着或多或少的依赖关系,对用户不是特别友好,毕竟谁也不希望仅仅为了构建一个连接,需要去仔细了解六七个函数。因而我们可以考虑将它们包装起来构建成统一的函数,方便使用。
从前面的例子中可知,客户端最终希望得到的是 clientfd 这个套接字文件,服务端稍微复杂些,不过也是为了得到 listenfd 套接字文件,有了这个文件就可以开始接收请求了。为此,我们可以分别为客户端和服务端各实现一个辅助函数,首先是客户端的 open_clientfd 函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
int open_clientfd(char *hostname, char *port) {
int clientfd;
struct addrinfo hints, *listp, *p;
/* Get a list of potential server addresses */
memset(&hints, 0, sizeof(struct addrinfo));
hints.ai_socktype = SOCK_STREAM; /* Open a connection */
hints.ai_flags = AI_NUMERICSERV; /* ... using a numeric port arg. */
hints.ai_flags |= AI_ADDRCONFIG; /* Recommended for connections */
Getaddrinfo(hostname, port, &hints, &listp);
/* Walk the list for one that we can successfully connect to */
for (p = listp; p; p = p->ai_next) {
/* Create a socket descriptor */
if ((clientfd = socket(p->ai_family, p->ai_socktype, p->ai_protocol)) < 0)
continue; /* Socket failed, try the next */
/* Connect to the server */
if (connect(clientfd, p->ai_addr, p->ai_addrlen) != -1)
break; /* Success */
Close(clientfd); /* Connect failed, try another */
}
/* Clean up */
Freeaddrinfo(listp);
if (!p) /* All connects failed */
return -1;
else /* The last connect succeeded */
return clientfd;
}
可以看到,用户仅仅需要传入发送请求的主机名还有端口号就可获得相应的套接字文件 clientfd。
服务端也是类似的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
int open_listenfd(char *port) {
struct addrinfo hints, *listp, *p;
int listenfd, optval=1;
/* Get a list of potential server addresses */
memset(&hints, 0, sizeof(struct addrinfo));
hints.ai_socktype = SOCK_STREAM; /* Accept connections */
hints.ai_flags = AI_PASSIVE | AI_ADDRCONFIG; /* ... on any IP address */
hints.ai_flags |= AI_NUMERICSERV; /* ... using port number */
Getaddrinfo(NULL, port, &hints, &listp);
/* Walk the list for one that we can bind to */
for (p = listp; p; p = p->ai_next) {
/* Create a socket descriptor */
if ((listenfd = socket(p->ai_family, p->ai_socktype, p->ai_protocol)) < 0)
continue; /* Socket failed, try the next */
/* Eliminates "Address already in use" error from bind */
Setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, (const void *)&optval , sizeof(int));
/* Bind the descriptor to the address */
if (bind(listenfd, p->ai_addr, p->ai_addrlen) == 0)
break; /* Success */
Close(listenfd); /* Bind failed, try the next */
}
/* Clean up */
Freeaddrinfo(listp);
if (!p) /* No address worked */
return -1;
/* Make it a listening socket ready to accept connection requests */
if (listen(listenfd, LISTENQ) < 0) {
Close(listenfd);
return -1;
}
return listenfd;
}
因为每当进程被终止,内核会自动关闭所有该进程打卡的文件,所以上面的 Close(listenfd); 其实是可以省略的,但是也没有必要,毕竟关闭没有用或是错误的文件本身就是一个最佳实践。
有了上面这两个辅助函数,我们构建网络应用就会方便很多,这里展示一个例子,我们构建一个 echo 客户端和服务端的,当客户端和服务端确立连接后,客户端会反复从标准输入端口读入信息,并将这些信息发送给服务端,服务端稍加处理后返回结果给客户端,客户端将结果打印到标准输出上。首先,我们来看看客户端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include "csapp.h"
int main(int argc, char **argv) {
int clientfd;
char *host, *port, buf[MAXLINE];
rio_t rio;
if (argc != 3) {
fprintf(stderr, "usage: %s <host> <port>\n", argv[0]);
exit(0);
}
host = argv[1];
port = argv[2];
clientfd = Open_clientfd(host, port);
Rio_readinitb(&rio, clientfd);
while (Fgets(buf, MAXLINE, stdin) != NULL) {
Rio_writen(clientfd, buf, strlen(buf));
Rio_readlineb(&rio, buf, MAXLINE);
Fputs(buf, stdout);
}
Close(clientfd);
exit(0);
}
其实整个逻辑非常简单,基本上就是调用 open_clientfd 确立连接,然后调用前面 第十章 中介绍的几个 I/O 读写函数进行数据的读写。
服务端的逻辑也是类似的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include "csapp.h"
void echo(int connfd);
int main(int argc, char **argv) {
int listenfd, connfd;
socklen_t clientlen;
struct sockaddr_storage clientaddr; /* Enough space for any address */
char client_hostname[MAXLINE], client_port[MAXLINE];
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(0);
}
listenfd = Open_listenfd(argv[1]);
while (1) {
clientlen = sizeof(struct sockaddr_storage);
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen);
Getnameinfo((SA *) &clientaddr, clientlen, client_hostname, MAXLINE, client_port, MAXLINE, 0);
printf("Connected to (%s, %s)\n", client_hostname, client_port);
echo(connfd);
Close(connfd);
}
exit(0);
}
void echo(int connfd) {
size_t n;
char buf[MAXLINE];
rio_t rio;
Rio_readinitb(&rio, connfd);
while((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0) {
printf("server received %d bytes\n", (int)n);
Rio_writen(connfd, buf, n);
}
}
Web 服务器
上面我们着重介绍了套接字,基于网络套接字,我们可以构建各种各样的应用,这其中属 Web 应用最为出名,也就是我们所熟知的网页应用。网页应用通过下面两种方式为客户端提供服务:
- 返回静态内容,比如一个静态的页面(静态内容)
- 运行一个可执行的文件,并将结果返回给客户端(动态内容)
网页内容说到底其实还是二进制数据流,但是这里如何解析成了重点,内容对应的是它的类型(MIME,multipurpose internet mail extensions),常见的类型如下所示:
| MIME type | Description |
|---|---|
| text/html | HTML page |
| text/plain | Unformatted text |
| application/postscript | Postscript document |
| image/gif | Binary image encoded in GIF format |
| image/png | Binary image encoded in PNG format |
| image/jpeg | Binary image encoded in JPEG format |
对于动态内容,这里有些标准性的问题,比如客户端如何将程序参数传递给服务器?服务器又如何将参数传递给子进程?还有子进程又将输出发送到哪?CGI(Common Gateway Interface,通用网关接口)标准就是解决这些问题的,下面这张表格展示了常见的 CGI 环境变量:
| Environment variable | Description |
|---|---|
| QUERY_STRING | Program arguments |
| SERVER_PORT | Port that the parent is listening on |
| REQUEST_METHOD | GET or POST |
| REMOTE_HOST | Domain name of client |
| REMOTE_ADDR | Dotted-decimal IP address of client |
| CONTENT_TYPE | POST only: MIME type of the request body |
| CONTENT_LENGTH | POST only: Size in bytes of the request body |
在子进程加载并运行 CGI 程序之前,它会使用 Linux 下的 dup2 指令将标准输出对接到 clientfd。子进程负责生成 Content-type 和 Content-length 响应头。
下面这个简单的 CGI 程序将两个输出参数进行相加并返回相应的 HTML 文件给客户端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include "csapp.h"
int main(void) {
char *buf, *p;
char arg1[MAXLINE], arg2[MAXLINE], content[MAXLINE];
int n1=0, n2=0;
/* Extract the two arguments */
if ((buf = getenv("QUERY_STRING")) != NULL) {
p = strchr(buf, '&');
*p = '\0';
strcpy(arg1, buf);
strcpy(arg2, p+1);
n1 = atoi(arg1);
n2 = atoi(arg2);
}
/* Make the response body */
sprintf(content, "QUERY_STRING=%s", buf);
sprintf(content, "Welcome to add.com: ");
sprintf(content, "%sTHE Internet addition portal.\r\n<p>", content);
sprintf(content, "%sThe answer is: %d + %d = %d\r\n<p>", content, n1, n2, n1 + n2);
sprintf(content, "%sThanks for visiting!\r\n", content);
/* Generate the HTTP response */
printf("Connection: close\r\n");
printf("Content-length: %d\r\n", (int)strlen(content));
printf("Content-type: text/html\r\n\r\n");
printf("%s", content);
fflush(stdout);
exit(0);
}
有了上面这些知识以及前面介绍的套接字相关内容,让我们来构建一个小型的服务器。
首先,我们搭建一个主程序,已经相应的函数声明:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
/*
* tiny.c - A simple, iterative HTTP/1.0 Web server that uses the
* GET method to serve static and dynamic content
*/
#include "csapp.h"
void doit(int fd);
void read_requesthdrs(rio_t *rp);
int parse_uri(char *uri, char *filename, char *cgiargs);
void serve_static(int fd, char *filename, int filesize);
void get_filetype(char *filename, char *filetype);
void serve_dynamic(int fd, char *filename, char *cgiargs);
void clienterror(int fd, char *cause, char *errnum, char *shortmsg, char *longmsg);
int main(int argc, char **argv) {
int listenfd, connfd;
char hostname[MAXLINE], port[MAXLINE];
socklen_t clientlen;
struct sockaddr_storage clientaddr;
/* Check command-line args */
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(1);
}
listenfd = Open_listenfd(argv[1]);
while (1) {
clientlen = sizeof(clientaddr);
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen);
Getnameinfo((SA *) &clientaddr, clientlen, hostname, MAXLINE, port, MAXLINE, 0);
printf("Accepted connection from (%s, %s)\n", hostname, port);
doit(connfd);
Close(connfd);
}
}
可以看到的是,主程序的框架其实跟前面的 echo 应用类似,这里的主要逻辑在 doit 函数中,该函数用来处理一个 HTTP 请求,具体实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
void doit(int fd) {
int is_static;
struct stat sbuf;
char buf[MAXLINE], method[MAXLINE], uri[MAXLINE], version[MAXLINE];
char filename[MAXLINE], cgiargs[MAXLINE];
rio_t rio;
/* Read request line and headers */
Rio_readinitb(&rio, fd);
Rio_readlineb(&rio, buf, MAXLINE);
printf("Request headers:\n");
printf("%s", buf);
sscanf(buf, "%s %s %s", method, uri, version);
if (strcasecmp(method, "GET")) {
clienterror(fd, method, "501", "Not implemented", "Tiny does not implement this method");
return;
}
read_requesthdrs(&rio);
/* Parse URI from GET request */
is_static = parse_uri(uri, filename, cgiargs);
if (stat(filename, &sbuf) < 0) {
clienterror(fd, filename, "404", "Not found", "Tiny couldn’t find this file");
return;
}
if (is_static) { /* Serve static content */
if (!(S_ISREG(sbuf.st_mode)) || !(S_IRUSR & sbuf.st_mode)) {
clienterror(fd, filename, "403", "Forbidden", "Tiny couldn’t read the file");
return;
}
serve_static(fd, filename, sbuf.st_size);
} else { /* Serve dynamic content */
if (!(S_ISREG(sbuf.st_mode)) || !(S_IXUSR & sbuf.st_mode)) {
clienterror(fd, filename, "403", "Forbidden", "Tiny couldn’t run the CGI program");
return;
}
serve_dynamic(fd, filename, cgiargs);
}
}
这里面包含了整个服务端的处理逻辑,doit 最先做的事情是读取请求信息,为了简单起见,这里我们只处理 GET 方法,如果是接收到其他的 HTTP 方法,则会调用 clienterror 函数生成错误信息并返回给客户端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
void clienterror(int fd, char *cause, char *errnum, char *shortmsg, char *longmsg) {
char buf[MAXLINE], body[MAXBUF];
/* Build the HTTP response body */
sprintf(body, "<html><title>Tiny Error</title>");
sprintf(body, "%s<body bgcolor=""ffffff"">\r\n", body);
sprintf(body, "%s%s: %s\r\n", body, errnum, shortmsg);
sprintf(body, "%s<p>%s: %s\r\n", body, longmsg, cause);
sprintf(body, "%s<hr><em>The Tiny Web server</em>\r\n", body);
/* Print the HTTP response */
sprintf(buf, "HTTP/1.0 %s %s\r\n", errnum, shortmsg);
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "Content-type: text/html\r\n");
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "Content-length: %d\r\n\r\n", (int)strlen(body));
Rio_writen(fd, buf, strlen(buf));
Rio_writen(fd, body, strlen(body));
}
另外,doit 函数,也就是我们的服务器处理程序,不会使用到请求头中的信息,仅仅是将其打印,read_requesthdrs 函数做的就是这个事情:
1
2
3
4
5
6
7
8
9
10
void read_requesthdrs(rio_t *rp) {
char buf[MAXLINE];
Rio_readlineb(rp, buf, MAXLINE);
while(strcmp(buf, "\r\n")) {
Rio_readlineb(rp, buf, MAXLINE);
printf("%s", buf);
}
return;
}
parse_uri 函数用于解析 HTTP URI 上的内容,具体实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
int parse_uri(char *uri, char *filename, char *cgiargs) {
char *ptr;
if (!strstr(uri, "cgi-bin")) { /* Static content */
strcpy(cgiargs, "");
strcpy(filename, ".");
strcat(filename, uri);
if (uri[strlen(uri)-1] == ’/’)
strcat(filename, "home.html");
return 1;
} else { /* Dynamic content */
ptr = index(uri, ’?’);
if (ptr) {
strcpy(cgiargs, ptr+1);
*ptr = ’\0’;
} else
strcpy(cgiargs, "");
strcpy(filename, ".");
strcat(filename, uri);
return 0;
}
}
parse_uri 会从 URI 中解析出文件路径并存放在 filename 中,doit 函数调用 stat 函数读取文件的元信息,如果调用错误,则会和前面一样调用 clienterror 函数。这里的关键是,parse_uri 会确定请求是需要静态内容还是动态内容,如果是静态内容,则会调用 serve_static 函数将文件包装起来返回给客户端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
void serve_static(int fd, char *filename, int filesize) {
int srcfd;
char *srcp, filetype[MAXLINE], buf[MAXBUF];
/* Send response headers to client */
get_filetype(filename, filetype);
sprintf(buf, "HTTP/1.0 200 OK\r\n");
sprintf(buf, "%sServer: Tiny Web Server\r\n", buf);
sprintf(buf, "%sConnection: close\r\n", buf);
sprintf(buf, "%sContent-length: %d\r\n", buf, filesize);
sprintf(buf, "%sContent-type: %s\r\n\r\n", buf, filetype);
Rio_writen(fd, buf, strlen(buf));
printf("Response headers:\n");
printf("%s", buf);
/* Send response body to client */
srcfd = Open(filename, O_RDONLY, 0);
srcp = Mmap(0, filesize, PROT_READ, MAP_PRIVATE, srcfd, 0);
Close(srcfd);
Rio_writen(fd, srcp, filesize);
Munmap(srcp, filesize);
}
/*
* get_filetype - Derive file type from filename
*/
void get_filetype(char *filename, char *filetype) {
if (strstr(filename, ".html"))
strcpy(filetype, "text/html");
else if (strstr(filename, ".gif"))
strcpy(filetype, "image/gif");
else if (strstr(filename, ".png"))
strcpy(filetype, "image/png");
else if (strstr(filename, ".jpg"))
strcpy(filetype, "image/jpeg");
else
strcpy(filetype, "text/plain");
}
如果是动态内容,则创建子进程对文件进行执行,并将结果进行返回:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
void serve_dynamic(int fd, char *filename, char *cgiargs) {
char buf[MAXLINE], *emptylist[] = { NULL };
/* Return first part of HTTP response */
sprintf(buf, "HTTP/1.0 200 OK\r\n");
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "Server: Tiny Web Server\r\n");
Rio_writen(fd, buf, strlen(buf));
if (Fork() == 0) { /* Child */
/* Real server would set all CGI vars here */
setenv("QUERY_STRING", cgiargs, 1);
Dup2(fd, STDOUT_FILENO); /* Redirect stdout to client */
Execve(filename, emptylist, environ); /* Run CGI program */
}
Wait(NULL); /* Parent waits for and reaps child */
}
因为通过 dup2 把标准输出对接到客户端上了,所以执行的结果也就随之返回了。
总结
上面将的内容仅仅是网络编程中比较基础的内容,除了这些,网络编程还有许许多多的协议、接口、标准等等,针对这些内容,最权威的文档是 RFCs(Requests for comments)。